 Google提出间接卷积算法,未来可会有突破?
Google提出间接卷积算法,未来可会有突破?
本文介绍的内容主要聚焦Google 的一项最新工作:改变基于 GEMM 实现的 CNN底层算法提出的新方法。通用矩阵乘法(General Matrix Multiply, GEMM)是广泛用于线性代数、机器学习、统计学等各个领域的常见底层算法,其实现了基本的矩阵与矩阵相乘的功能,因此算法效率直接决定了所有上层模型性能,目前主流的卷积算法都是基于GEMM来实现的。来自谷歌的Peter Vajda在ECV2019中提出了一种全新的间接卷积算法,用于改进GEMM在实现卷积操作时存在的一些缺点,进而提升计算效率。
通用矩阵乘法
GEMM是基础线性代数子程序库(Basic Linear Algebra Subprograms, BLAS)中的一个函数。BLAS提供了实现矩阵和向量基本运算的函数,最早于1979年由C.L.LAWSON提出。BLAS的发展大致可以分为三个阶段(levels)的历程,这和函数定义,出版顺序,以及算法中多项式的阶数以及复杂性有关,第一阶段只包含与向量(vector)有关的运算,第二阶段添加了向量与矩阵进行运算的操作,第三阶段添加了矩阵与矩阵之间的运算,前两个阶段的BLAS都是用于向量处理器的,而第三阶段适用于矩阵处理器,所以BLAS的发展和硬件的发展密不可分。GEMM属于第三阶段的算法,正式公布于1990年,其迭代更新形式为:

其中A和B可以进行转置或hermitian共轭转置,而A、B和C都可以被忽略(be strided),因此实际上这个公式就表示了任意矩阵之间所有可能的加法和乘法组合,例如最基本的A*B,可以将α置1,C置为全0矩阵即可,这也是其通用性的表现。
由于矩阵乘法相对于向量-向量乘法以及向量-矩阵乘法,有更低的时间复杂度,效率更高,因此其广泛用于许多科学任务中,与之相关的GEMM算法成为了目前BLAS设计者的主要优化对象。例如可以将A和B分解为分块矩阵,使得GEMM可以递归实现。有关GEMM的详细信息可以参见[1][2][3]。如何对GEMM进行优化,是BLAS相关工作的研究热点。
基于 GEMM 的卷积算法及其缺点
卷积神经网络(CNN)在CV问题中的表现很出色,有多种在算法层面对齐进行实现的方法:直接卷积算法,采用7层循环,快速卷积算法,利用傅里叶变换来进行卷积,以及基于GEMM的卷积算法。
通过将卷积操作用矩阵乘法来代替,进而使用GEMM算法来间接进行卷积操作,这使得卷积操作可以在任何包含GEMM的平台上进行,并且受益于矩阵乘法的高效性,任何针对GEMM的改进和研究都能有助于卷积运算效率的提升,从而提高模型的运算速度,因此目前大部分主流的神经网络框架,例如Tensorflow、Pytorch和Caffe都使用基于GEMM的方法来在底层代码中实现卷积。
具体的,基于GEMM的卷积方法需要借助于 im2col或im2row buffer来内存转换,使得数据格式满足GEMM算法的输入要求,从而将卷积操作转化为GEMM操作,然而这个转换过程是一个计算开销和内存开销都比较大的过程,特别是在输入channel数较小时,这个过程会在整个卷积过程中占有很大的比例。简言之,就是在卷积过程中,每个pixel都会被多次重复的转换,这是不必要的计算开销。因此有许多工作都在对这一过程进行改进,本文工作提出了一种改进算法——间接卷积算法(Indirect Convolution algorithm),主要有以下两个优点:
1、去掉了im2row的转换过程,这使得算法性能有了巨大的提升(up to 62%)。
2、用了一个更小的indirection buffer来代替原来的im2row buffer。不同于im2row buffer的大小随着输入channel数线性增加,indirection buffer没有这个特性,因此indirection buffer的内存占用特性非常有利于输入channel数较多时的卷积操作。
间接卷积算法
原始的GEMM通过如下计算来不断迭代进行矩阵运算操作并输出矩阵:

其中A是输入张量,B是一个常量滤波器,C是输出矩阵,在传统的im2col+GEMM算法中,通常α=1而β=0,原始GEMM操作示意图如下:

图1 原始GEMM操作
其中 im2col buffer 代表矩阵A,filter tensor 代表矩阵B,A和B的乘积就是输出copy表示将输入的张量展开为一个二维矩阵,也就是im2col buffer。可以看到buffer的每一行则是由固定个数(步长)的pixel展开成一维的向量组成的,这些pixel都在原始tensor中的一个patch内,在经过和filter tensor相乘后,由于矩阵行列相乘得到一个元素,因此这几个pixel的信息都被整合成了一个值,也就是对他们进行了卷积操作。最后在输出矩阵C中,行数rows代表输出的像素点个数,columns代表输出的channel数。可以看到buffer的columns是和输入channel数有关的。
为了降低buffer带来的开销,作者提出了一种间接矩阵乘法的思想,不把输入的tensor直接展开并存储在buffer中,而只是在buffer中存放每个pixel在input tensor的坐标,也就是从存数据变成了存地址(类似于指针pointer思想),这样不管channel数有多少,存的地址信息始终只有二维,极大的降低了buffer的计算和存储开销,如下图:
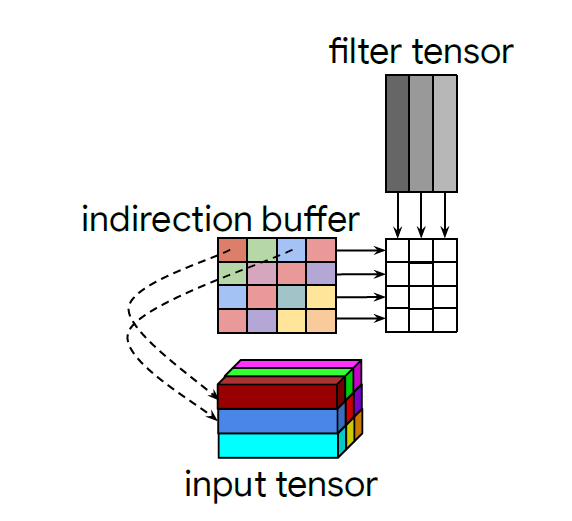
图2 indirect convolution
当然,由于buffer中存的是地址信息,因此不能直接和filter做矩阵乘法,所以就只能通过在buffer的行间进行循环,根据该行的pointer找到对应的输入数据,再将输入数据与kernel相乘,并与之前循环的结果拼接起来,从而间接的实现矩阵乘法,因此叫做indirection buffer。
对于不同的卷积步长,只需要将不同步长对应的卷积patch位置确定即可。而对于padding策略,将指向填充位置的pointer对应的输入pixel的向量值全部设置为0。
间接卷积算法的缺点
间接卷积算法作为GEMM-BASED CNN算法的一种改进,能极大的提升计算效率,但是存在以下几个限制:
1. 这个算法是为NHWC layout设计的,也就是说应用范围比较窄,不能和目前的主流方法相比。
2. 算法适用于前向传播中的卷积操作,而在反向传播中作用不大,不及基于col2im和row2im的算法。
3. 具有和GEMM相同的缺点,在深度小卷积核的卷积操作中效率并不好。
实验测试结果
Efficient Deep Learning for Computer Vision主要聚焦于如何将深度学习部署到移动设备上,因此本文的工作主要在移动设备和移动芯片上进行测试,结果如下:

可以看到一旦步长增加,那么Indirect convolution带来的性能提升就会明显下降,这是因为步长越大,在原始的GEMM算法中重复计算的量就会减小,因此原始GEMM的性能本身就会提升,而indirect convolution并不受益于步长增加。
-
Google
+关注
关注
5文章
1712浏览量
56788 -
算法
+关注
关注
23文章
4452浏览量
90746
原文标题:基于GEMM实现的CNN底层算法被改?Google提出全新间接卷积算法
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AURIX TC397是否可以搭配Google TensorFlow的演算法去运算?
Google新算法抵御来自量子计算的威胁,Saphlux新技术推动AR/VR领域创新






 工商网监
工商网监
评论