 谷歌发布非政策强化学习算法OPC的最新研究机器学习即将开辟新篇章?
谷歌发布非政策强化学习算法OPC的最新研究机器学习即将开辟新篇章?
在谷歌最新的论文中,研究人员提出了“非政策强化学习”算法OPC,它是强化学习的一种变体,它能够评估哪种机器学习模型将产生最好的结果。数据显示,OPC比基线机器学习算法有着显著的提高,更加稳健可靠。
在谷歌AI研究团队一篇新发表的论文《通过非政策分类进行非政策评估》(Off-PolicyEvaluation via Off-Policy Classification)和博客文章中,他们提出了所称的“非政策分类”,即OPC(off-policy classification)。它能够评估AI的表现,通过将评估视为一个分类问题来驱动代理性能。
研究人员认为他们的方法是强化学习的一种变体,它利用奖励来推动软件政策实现与图像输入协同工作这个目标,并扩展到包括基于视觉的机器人抓取在内的任务。
“完全脱离政策强化学习是一种变体。代理完全从旧数据中学习,对于工程师来说这是很有吸引力的,因为它可以在不需要物理机器人的情况下进行模型迭代。”
Robotics at Google(专注机器学的的谷歌新团队)的软件工程师Alexa Irpan写道,“完全脱离政策的RL,可以在先前代理收集的同一固定数据集上训练多个模型,然后选择出最佳的那个模型。”
但是OPC并不像听起来那么容易,正如Irpan在论文中所描述的,非政策性强化学习可以通过机器人进行人工智能模型培训,但不能进行评估。并且在需要评估大量模型的方法中,地面实况评估通常效率太低。
OPC在假设任务状态变化方面几乎没有随机性,同时假设代理在实验结束时用“成功或失败”来解决这个问题。两个假设中第二个假设的二元性质,允许为每个操作分配两个分类标签(“有效”表示成功或“灾难性”表示失败)。
另外,OPC还依赖Q函数(通过Q学习算法学习)来估计行为的未来总回报。代理商选择具有最大预期回报的行动,其绩效通过所选行动的有效频率来衡量(这取决于Q函数如何正确地将行动分类为有效与灾难性),并以分类准确性作为非政策评估分数。
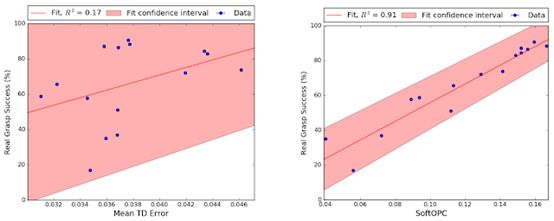
(左图为基线,右图为建议的方法之一,SoftOpC)
谷歌AI团队使用完全非策略强化学习对机器学习策略进行了模拟培训,然后使用从以前的实际数据中列出的非策略分数对其进行评估。
在机器人抓取任务时,他们报告OPC的一种变体SoftOPC在预测最终成功率方面表现最佳。假设有15种模型(其中7种纯粹在模拟中训练)具有不同的稳健性,SoftOPC产生的分数与与真正的抓取成功密切相关,并且相比于基线方法更加稳定可靠。
在未来的研究中,研究人员打算用“噪声”(noisier)和非二进制动力学来探索机器学习任务。“我们认为这个结果有希望应用于许多现实世界的RL问题,”Irpan在论文结尾写道。
-
谷歌
+关注
关注
27文章
5839浏览量
103234 -
AI
+关注
关注
87文章
26364浏览量
263960 -
机器学习
+关注
关注
66文章
8096浏览量
130523
原文标题:又一个里程碑,谷歌发布最新研究,机器学习开辟新篇章!
文章出处:【微信号:Aiobservation,微信公众号:人工智能观察】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度强化学习实战
将深度学习和强化学习相结合的深度强化学习DRL
基于LCS和LS-SVM的多机器人强化学习
量化深度强化学习算法的泛化能力

深度强化学习到底是什么?它的工作原理是怎么样的
一文详谈机器学习的强化学习
机器学习中的无模型强化学习算法及研究综述

2021 OPPO开发者大会:新篇章公式

强化学习的基础知识和6种基本算法解释
强化学习的基础知识和6种基本算法解释






 工商网监
工商网监
评论