 MIT研究人员开发出一种具有预测性人工智能的机器人
MIT研究人员开发出一种具有预测性人工智能的机器人
摸一摸就知道长什么样、看一看就知道摸着是什么感觉,你以为我说的是人?不,是AI。MIT研究人员开发出一种具有预测性人工智能的机器人,它可以通过触摸来学习“看”,通过“看”来学习感觉,李昀烛和朱俊彦这两位大神参与了此项研究。
我们人类可以通过简单地触摸来轻松地判断物体的外形,这完全归功于我们的触觉,它使我们具备了这种能力。此外,我们当然也可以通过观察物体来确定它的感受。
但做同样的事情对于机器来说可能是困难的,这也是一个巨大的挑战。即使是被编程有感官的机器人也无法做到这一点,它们不能把这些触觉信号互换使用。
现在,麻省理工学院计算机科学与人工智能实验室(CSAIL)的研究人员已经开发出一种具有预测性人工智能(AI)的机器人,它可以通过触摸来学习“看”,通过“看”来学习感觉。
强强联合,必出精品
在细讲这篇论文之前,先来给大家隆重介绍一下这个研究团队——均来自MIT CSAIL,一作是MIT CSAIL博士、曾经的北大学神李昀烛,二作是即将在CMU担任助理教授、曾经的清华学神朱俊彦。
李昀烛
李昀烛是CSAIL的二年级博士生,他的研究领域是计算机视觉、机器学习和机器人技术,尤其是基于深度学习的机器人动力学建模和多模态感知。他本科毕业于北京大学,本科期间参加北京大学和斯坦福大学的多个实验室研究,并以第一作者身份发表多篇计算机视觉和机器学习顶级会议论文。
朱俊彦
朱俊彦目前是CSAIL的一名博士后研究员,他将于2020年秋季回到CMU担任助理教授。朱俊彦主要从事计算机视觉、计算机图形和机器学习的研究。他毕业于加州大学伯克利分校,2012 年获得清华大学计算机科学系的工学学士学位,在 CMU 和 UC Berkeley 经过 5 年学习后,于 2017 年获得 UC Berkeley 电气工程与计算机科学系的博士学位。(参见:【AI新星耀名校】陈天奇、朱俊彦、金驰加盟CMU、普林斯顿)
李昀烛和朱俊彦曾经合作多次,最近最近爆火的MIT十美元“灭霸”手套也是二人合作完成的。这次又强强联合,会出怎样的精品呢?接下来看看这项新研究。
这项研究做了什么?
研究团队使用KUKA机器人手臂并添加了一个名为GelSight的特殊触觉传感器,该传感器之前由Edward Adelson领导的另一个麻省理工学院小组设计。
图1.数据采集装置:(a)他们使用一个装备了GelSight传感器的机器人手臂来收集触觉数据,并使用网络摄像头来捕捉对象交互场景的视频。(b)凝胶接触物体的图示。交叉模式预测:在收集到的视觉触觉对的基础上,他们为几个任务训练了交叉模式预测网络:(c)通过视觉学习感知(视觉→触摸):从相应的视觉输入和参考图像预测触摸信号;(d)通过触摸来学习看(触摸→视觉):通过触摸预测视觉。预测的触摸位置和ground truth位置(用(d)中的黄色箭头标记)具有相似的感觉。
GelSight是一块透明的合成橡胶板,其一面涂有油漆,含有微小的金属斑点。在另一侧,安装摄像头。该团队使用网络摄像头记录了近12000个被触摸的200件物品的视频,包括工具、家用产品、织物等。
图2.物品集。这里他们展示了训练和测试中使用的物品集,包含了食品、工具、厨房用品、织物和文具等各种各样的物品。
然后,研究人员将这些视频分解为静态帧并编制了“VisGel”,这是一个包含超过300万个视觉/触觉配对图像的数据集。这些参考图像随后帮助机器人对物品和环境的细节进行编码。
“通过观察场景,我们的模型可以想象触摸平坦表面或锋利边缘的感觉,” 李昀烛说:“仅通过触摸,我们的模型可以单纯从触觉中预测与环境的相互作用。将这两种感官结合在一起,可以增强机器人的能力并减少我们在涉及操纵和抓取物体的任务时可能需要的数据。”
视觉和触觉演示
视觉到触觉(绿色:Ground Truth;红色:预测)
触觉到视觉(绿色:Ground Truth;红色:预测)
现在,机器人只能识别受控环境中的物体。然而,一些细节,如物体的颜色和柔软度,对于新的AI系统得出结论仍然是个挑战。尽管如此,研究人员希望这种新方法能够为制造环境中的“人-机器人”无缝结合铺平道路,尤其是在缺乏视觉数据的任务中。
该团队新AI系统的下一步是通过收集更多非结构化区域中的数据或使用MIT新设计的传感器手套来构建更大的数据集,以便机器人可以在更多样化的环境中工作。
“这是第一种可以令人信服地在视觉和触摸信号之间进行转换的方法,”加州大学伯克利分校的博士后Andrew Owens说:“像这样的方法有可能对机器人技术非常有用,你需要回答诸如'这个物体是硬还是软?'之类的问题,或者'如果我通过杯柄举起这个杯子,我的握力有多好?'这是一个非常具有挑战性的问题,因为信号是如此不同,而且这个模型已经证明了它的强大能力。”
该论文会在加利福尼亚州长滩举行的CVPR上发表,接下来和大家分享一下这篇论文。
使用跨模态预测方法
研究人员提出了一种从触觉预测视觉的跨模态预测方法,反之亦然。首先,他们将触摸的规模和位置合并到他们的模型中。然后,使用数据再平衡机制来增加结果的多样性。最后,通过从附近的输入帧中提取时间信息,进一步提高了结果的时间一致性和准确性。
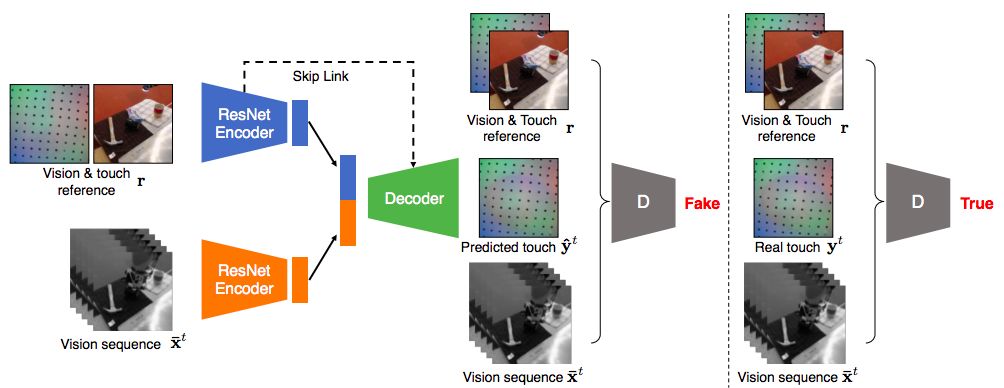
图3.跨模态预测模型概述:视觉→触摸模式。
图3显示了一个示例输入输出组合,其中网络将一系列视觉图像和相应的参考作为输入,并将触觉预测合成为输出。同样的框架也可以应用于触摸→视觉。
实验介绍
研究人员使用VisGel数据集对视觉和触觉之间的跨模态预测任务的方法进行了评估。他们报告了评估预测不同方面的多个指标。
对于视觉→触觉预测,测量
(1)使用AMT的感知现实性:结果是否真实,
(2)接触时刻:模型能否预测GelSight传感器是否与物体接触,
(3)标记物的变形:模型是否能够跟踪膜的变形。
对于触摸→视觉方向,他们使用
(1)通过AMT的视觉真实性和
(2)触摸感来评估他们的模型:预测的触摸位置是否与ground truth位置具有相似的感觉。他们还将有关完整参考指标的评估纳入补充资料,并向所有基线提供参考图像,因为它们对于处理比例差异至关重要(图4)。
图4.使用参考图像。使用/不使用参考图像的方法的定性结果。他们用参考图像训练的模型产生了更具视觉吸引力的图像。
图5.跨模态预测结果示例。(a)和(b)显示了他们的模型和基线的视觉→触摸预测的两个例子。(c)和(d)显示触摸→视觉方向。 在这两种情况下,他们的结果看起来既真实又在视觉上类似于ground truth 目标图像。在(c)和(d)中,他们的模型在没有ground truth 位置标注的情况下进行训练,可以准确地预测触摸位置,与完全监督的预测方法相当。

图6.Vision2Touch定量结果。上图:检测触摸了物体表面的错误。使用时间提示可以显著提高性能或他们的模型。下图:根据图像还原触觉点位置的失真错误情况。他们的方法仍然有效。

图7.Vision2Touch检测接触时刻。显示了标记随时间的变形,由所有黑色标记的平均移动决定。较高的变形意味着物体与较大的力接触。上图:三种典型案例,其中(a)所有方法都可以推断出接触时刻,(b)没有时间线索的方法无法捕捉接触时刻,(c)没有时间线索的方法会产生错位结果。下图:我们展示了案例(c)中的几个视觉和触摸框架。 我们的模型具有时间线索可以更准确地预测GelSight的变形。标记的运动为红色显示以获得更好的可视化效果。

表2.Vision2Touch AMT “真实vs虚假”测试。与pix2pix和基线相比,他们的方法可以合成更逼真的触觉信号,既适用于已知物品,也适用于未知物品。
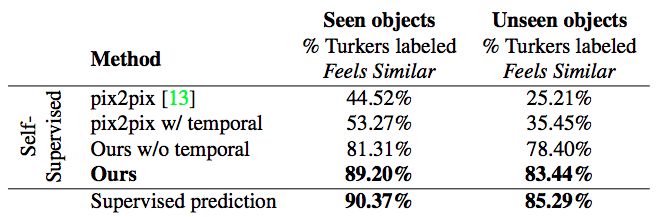
表3. Touch2Vision“感觉相似vs感觉不同”测试。他们的自我监督方法明显优于基线。其精度可与用ground truth 标注训练的完全监督预测方法相媲美。

表4. Touch2Vision AMT“真实vs虚假”测试。 尽管pix2pix在看不见的对象中获得了最高分,但由于mode collapse,它总是产生相同的图像。
讨论
在这项研究中,研究团队提出用条件对抗网络在视觉和触觉之间建立联系。在与世界互动时,人类严重依赖于两种感官模式。他们的模型可以为已知对象和未知对象提供有希望的跨模态预测结果。在未来,视觉-触觉交叉模式连接可以帮助下游视觉和机器人应用,例如在弱光环境中的物体识别和抓取,以及物理场景理解。
-
传感器
+关注
关注
2525文章
48069浏览量
739998 -
机器人
+关注
关注
206文章
27025浏览量
201379 -
人工智能
+关注
关注
1776文章
43824浏览量
230584
原文标题:触感隔空看到,MIT“灭霸手套”作者李昀烛、朱俊彦又一重磅研究
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论