 聚焦 | 新技术“红”不过十年?半监督学习却成例外?
聚焦 | 新技术“红”不过十年?半监督学习却成例外?
这一波深度学习的发展,以2006年Hinton发表Deep Belief Networks的论文为起点,到今年已经超过了10年。从过往学术界和产业界对新技术的追捧周期,超过10年的是极少数。从深度学习所属的机器学习领域来看,到底什么样的方向能够支撑这个领域继续蓬勃发展下去,让学术界和产业界都能持续投入和产出,就目前来看,半监督学习是一个很有潜力的方向。
机器学习范式的发展
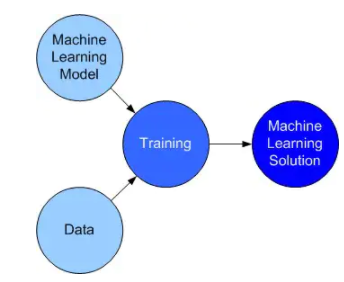
传统机器学习的解决路径可以表示为:
ML Solution = ML expertise + Computation + Data
其中ML expertise是机器学习专家,负责特征工程、机器学习模型设计和最终的训练,是整个机器学习解决方案效果的关键因素。Computation是计算能力,代表具体选择什么的硬件去承载专家设计的优化方案。这个部分一般来说穷有穷的打法,富有富的策略:以CTR预估为例,小厂设备不多,资源不足,那么可能GBDT就是一个不错的选择;大厂的话,资源相对富裕,那么各种DNN就上来了。Data无论做什么业务,或多或少也都有一些,C端产品的话,上线后总会有用户反馈可以做为label;B端产品的话,以我曾经搞过的图片识别为例,定向爬虫和人工标注也能弄到有标签样本。Data总会有,无外乎多少的区别。
这里就存在一个问题,Computation和Data即便有了,也不一定有很匹配的人来把整个事情串联运用起来,发挥最终的价值。21世纪,最贵的是人才;为什么贵?因为稀缺。于是大家就在想,能不能把机器学习问题的解决路径改为:
New ML Solution = 100x Computation + 100x Data
简而言之,就是用更多地Computation和Data代替人的作用。100x Computation替代人工模型设计,这两年也得到了长足的发展,这就是AutoML。狭义的来看AutoML,NAS和Meta Learning在学术界工业界都有不错的进展。尤其是NAS,2017年Zoph和Le发表的Neural Architecture Search with Reinforcement Learning作为引爆点,快速形成了一个火爆的研究领域,主要思路是通过RNN controller来sample神经网络结构,训练这个网络结构,以这个网络结构的指标作为RL的reward优化这个controller,让这个controller能够sample出更有效的网络结构。
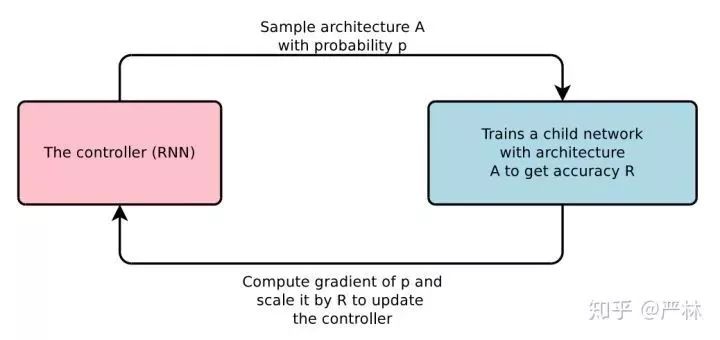
Controller训练过程
这个领域后续还有一些列出色的工作,但由于不是今天讨论的重点,暂且按下不表,有时间再写一篇关于NAS的从认知到实践。
100x Data听上去就是一个很有诱惑力的事情,因为更多的数据,往往意味着更好的效果。以最近异常火爆的BERT和GPT2,都被认为是大力出奇迹的暴力美学典范。大量的数据带来效果提高了人们对当前AI的认知边界,GPT2生成的文本就是一个很好的例子。但是数据规模的扩大,往往意味着某方面成本的提升。广告CTR预估,100x的样本要么是DAU增长了100倍,要么是出了100x的广告(估计会被用户打死的),都不太真实;图片的人工标注增长100x即便金钱成本能接受,时间成本也太长,猜想ImageNet如果1亿标注样本,估计CV的发展还会有更多的爆发点。
在谈半监督学习的进展前,我们先看看另一个机器学习方向在解决数据不足和数据稀疏上的努力。
Multi-Task Learning
Multi-Task Learning是指不同的任务之间通过共享全部或者部分模型参数,相互辅助,相互迁移,共同提高的机器学习方法。实际使用过程中,Multi-Task Learning由于多个任务共享参数,还能带来Serving Cost的下降,在学术界和工业界都有不少相关工作,并且在一些数据上取得了不错的进展。
Multi-Task Learning由于不同任务之间可以相互辅助学习,往往数据稀疏的任务能够从数据丰富的任务收益,得到提高,同时数据丰富任务还不怎么受影响或者微弱提升。这在一定程度上缓解了数据量的需求。
最近几年比较好的Multi-Task Learning工作,首先让我比较有印象的是Cross-stitch。Cross-stitch通过在Multi-Task的表达学习中,通过权重转换矩阵 alpha_{AB} 或者 alpha_{BA} 直接获得另一个任务的中间表示信息,这种方案在效果上比传统的Shared Bottom灵活,也减少了模型参数被某一个任务完全主导的风险。
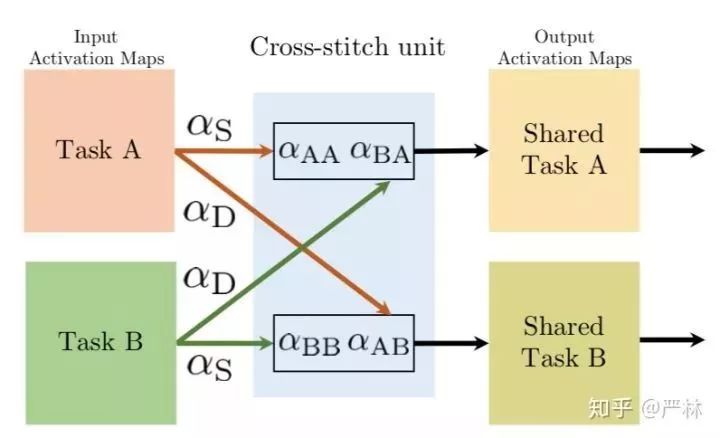
Cross-stitch子结构
后来的ESSM跟Cross-stitch有异曲同工之妙,只是将任务的学习方向改为单向:pCVR单向从pCTR中学习,以满足业务上的逻辑因果关系。
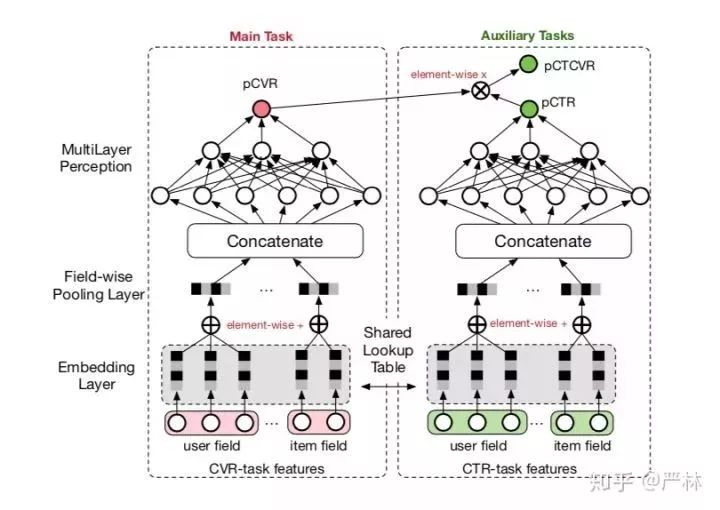
ESSM学习框架
Multi-Task Learning最近比较有意思的工作,SNR应该算一个,思路主要收到Mixture-of-Expert的启发(Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer:这篇文章背后的思想其实是Google解决大规模机器学习的新思路,完全值得开篇另述!),不同的任务走不同的网络路由,即不同的任务会由不同的Experts组合预估,而Experts总量固定,在不同任务间是部分共享的。对比Cross-stitch,每个任务都必须使用另外任务的信息,这种网络架构设计,使得不同任务的Expert既有独立又有共享。具体的独立和共享方式,每个任务通过模型训练学习得到,比较好的平衡了任务的独立性和共通性。SNR还使用了稀疏路由的思想,使得每个任务在保证效果的前提下经过最少的Experts,降低计算量。

Multi-Task Learning在学术界和工业界都获得了不俗的成绩,但是也有一个要命的短板,需要另外一个数据丰富且能够学习比较好的任务帮忙。这个要求限制了Multi-Task Learning发挥的空间,因为很多情况下,不仅没有其他任务,仅有的任务label也很匮乏,于是半监督学习就有了用武之地。
半监督学习
半监督学习通常情况下,只有少量的有label数据,但是可以获得大量的无label数据,在这种情况下希望能够获得跟监督学习获得相似甚至相同的效果。半监督学习的历史其实已经也比较久远了,2009年Chapalle编著的Semi-Supervised Learning,就对其定义和原理做了详细介绍。在计算力随着深度学习的热潮快速发展的同时,大量的label贫困任务出现,于是半监督学习也越来越重要。
半监督学习近两年最有亮点的工作当属发表在EMNLP'2018的Phrase-Based & Neural Unsupervised Machine Translation,大幅提升了半监督机器机器翻译的SOTA。
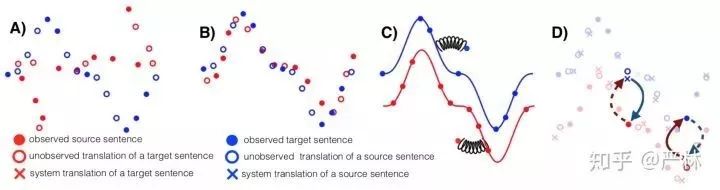
翻译训练过程示意
在整个训练过程中,B)先对其两种语言的work级别翻译,然后C)针对两种语言分别学一个Language Model,获得语言分布,最后D)再根据语言分布反复使用Back-Translation在已知的少量句对上翻译获得最终模型。这种方案大幅提高了在对齐句对不多的语种之间的翻译质量,同时由于其novelty,获得了EMNLP'2018的Best Paper Award,初读此文时有一种眼前一亮的感觉。(尽管标题叫Unsupervised Machine Translation,但是实际上利用到了部分label数据,我更愿意将其归类为Semi-Supervised Machine Translation。)
最近Google的研究人员又提出来一种新的半监督训练方法MixMatch,这种方法号称是Holistic的,综合运用了:A)distribution average; B)temperature sharpening; C)MixUp with labeled and unlabeled data. 其训练过程如下:

这个方法在CIFAR-10上只有250个label时能将错误率从38%降到11%,令人印象深刻。『江山代有才人出』,另一波Google的研究人员提出了UDA,在我看来这种方法更为彻底,也更加End-to-End。UDA主要利用数据分布的连续性和一致性,在输入有扰动的情况下,输出应该保持稳定,于是对于unlabeled data增加了一个损失函数:

即有扰动和无扰动的unlabeled data的预估分布的KL距离应该非常小,同时数据扰动用尽可能贴近任务本身的方法去做,比如图像用AutoArgument,文本用上面提到的Back-Translation和Word Replacement。
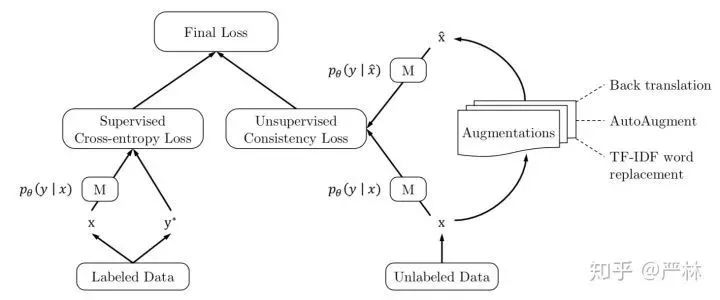
UDA训练示意
UDA的效果在文本和图像上都得到了很好地验证,大幅降低标注数据不足情况下得错误率;更值得关注的一点是,即便在ImageNet这种标注数据已经非常多的情况下,再使用UDA依然能带来效果的提升,说明UDA在数据分布拟合上具有很好地通用性。
结语
总体来看,半监督机器学习无论是采用聚类、图传播、数据增强还是泛化学习,主要依据的理论基础都是labeled和unlabeled data在分布上的连续性和一致性,因此机器学习方法可以利用这点进行有效的结构化学习,增强模型的表征能力,进而很好地提高预测效果。虽然半监督机器学习已经取得了一些很好的结果,从近两年ICML、ICLR和NeurIPS等会议看,相关工作也越来越多,但是还远没有到CV中的ResNet和NLP中的BERT的水平,要实现100x Data真正发挥作用,还需要学术界和工业界共同努力。
-
深度学习
+关注
关注
73文章
5219浏览量
119863 -
半监督学习
+关注
关注
0文章
20浏览量
2479
原文标题:新技术“红”不过十年,半监督学习为什么是个例外?
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于transformer和自监督学习的路面异常检测方法分享

什么是强化学习


机器学习模型类型分类
适用于任意数据模态的自监督学习数据增强技术

人工智能的关键技术包括哪些
机器学习有哪些算法?机器学习分类算法有哪些?机器学习预判有哪些算法?
人工智能是什么的一个分支
人工智能技术包括哪些方面
人工智能ai是什么
人工智能有哪些算法
人工智能的关键技术是什么?
最新3D表征自监督学习+对比学习:FAC
机器学习步骤详解,一文了解全过程





 工商网监
工商网监
评论