 谷歌Transformer大进化 机翻最强王者上线
谷歌Transformer大进化 机翻最强王者上线
谷歌Evolved Transformer通过AutoML技术进行特定任务定制,在编码器和解码器模块底部的卷积层以分支模式运行,提高了语言建模的性能,目前在机器翻译领域可以达到最先进的结果。
Transformer是一种AI架构,最早是在2017年Google的科学家合著的论文《Attention Is All You Need》中介绍的,它比较擅长撰写散文和产品评论、合成声音、以古典作曲家的风格制作和声。
但是,谷歌的一个研究小组认为它可以更进一步使用AutoML技术,根据特定任务进行定制翻译。在一篇新发表的论文和博客中,研究人员描述了工作成果:与原始的Transformer相比,现在的Transformer既达到了最先进的翻译结果,也提高了语言建模的性能。
目前,他们已经发布了新的模型Evolved Transformer——开放源代码的AI模型和数据集库,来作为Tensor2Tensor(谷歌基于tensorflow新开源的深度学习库,该库将深度学习所需要的元素封装成标准化的统一接口,在使用其做模型训练时可以更加的灵活)的一部分。
一般意义上,AutoML方法是从控制器训练和评估质量的随机模型库开始,该过程重复数千次,每次都会产生新的经过审查的机器学习架构,控制器可以从中学习。最终,控制器开始为模型组件分配高概率,以便这些组件在验证数据集上更加准确,而评分差的区域则获得较低的概率。
研究人员称,使用AutoML发现Evolved Transformer需要开发两种新技术,因为用于评估每种架构性能的任务WMT'14英德语翻译的计算成本很高。
第一种是通过暖启动(warm starting)的方式,将初始模型填充为Transformer架构进行播种,而不采用随机模型,有助于实现搜索。第二种渐进式动态障碍(PDH)则增强了搜索功能,以便将更多的资源分配给能力最强的候选对象,若模型“明显不良”,PDH就会终止评估,重新分配资源。
通过这两种技术,研究人员在机器翻译上进行大规模NAS,最终找到了Evolved Transformer。
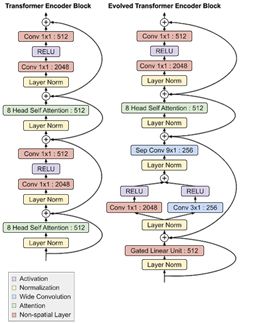
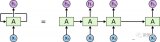
(Evolved Transformer架构)
那么Evolved Transformer有什么特别之处呢?
与所有深度神经网络一样,Evolved Transformer包含神经元(函数),这些神经元从输入数据中传输“信号,并缓慢调整每个连接的突触强度(权重),这是模型提取特征和学习进行预测的方式。此外,Evolved Transformer还能使每个输出元件连接到每个输入元件,并且动态地计算它们之间的权重。
与大多数序列到序列模型一样,Evolved Transformer包含一个编码器,它将输入数据(翻译任务中的句子)编码为嵌入(数学表示)和一个解码器,同时使用这些嵌入来构造输出(翻译)。
但研究人员也指出,Evolved Transformer也有一些部分与传统模型不同:在编码器和解码器模块底部的卷积层以分支模式运行,即在合并到一起时,输入需要通过两个单独的的卷积层。
虽然最初的Transformer仅仅依赖于注意力,但Evolved Transformer是一种利用自我关注和广泛卷积的优势的混合体。
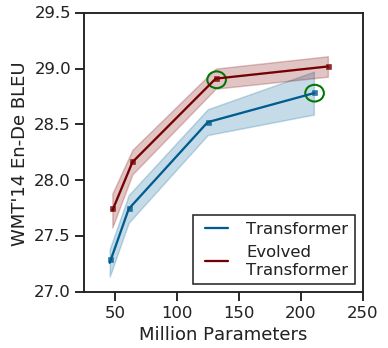
(原始Transforme与Evolved Transformer的性能对比)
在测试中,研究人员将Evolved Transformer与原始Transformer在模型搜索期间使用的英德翻译任务进行了比较,发现前者在BLEU(评估机器翻译文本质量的算法)和Perplexity(衡量概率分布预测样本的程度)上性能更好。
在较大的数据中,Evolved Transformer达到了最先进的性能,BLEU得分为29.8分。在涉及不同语言对和语言建模的翻译实验中,Evolved Transformer相比于原始Transformer的性能提升了两个Perplexity。
-
谷歌
+关注
关注
27文章
5838浏览量
103228 -
AI
+关注
关注
87文章
26363浏览量
263957 -
机器翻译
+关注
关注
0文章
138浏览量
14793 -
Transformer
+关注
关注
0文章
130浏览量
5895
原文标题:谷歌Transformer大进化,机翻最强王者上线
文章出处:【微信号:Aiobservation,微信公众号:人工智能观察】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
新火种AI|谷歌深夜炸弹!史上最强开源模型Gemma,打响新一轮AI之战

谷歌大型模型终于开放源代码,迟到但重要的开源战略

谷歌发布全球最强开源大模型Gemma
谷歌Gemini 1.5深夜爆炸上线,史诗级多模态硬刚GPT-5!最强MoE首破100万极限上下文纪录

大语言模型背后的Transformer,与CNN和RNN有何不同

成都汇阳投资关于谷歌携 Gemini 王者归来,AI 算力和应用值得期待
更深层的理解视觉Transformer, 对视觉Transformer的剖析
降低Transformer复杂度O(N^2)的方法汇总

BEV人工智能transformer
基于Transformer的目标检测算法

谷歌DeepMind发布机器人大模型RT-2,提高泛化与涌现能力

谷歌Transformer八子全部“出逃”,他们创作了ChatGPT中的“T”

2D Transformer 可以帮助3D表示学习吗?
Transformer结构及其应用详解





 工商网监
工商网监
评论