 悄悄来临的半监督学习革命
悄悄来临的半监督学习革命
对机器学习工程师们来说,最经常遇到的状况之一就是能轻松收集到一大堆数据,但是却只有非常有限的资源做数据标注。每个遇到这种尴尬处境的人都只能冷静下来,把他们的状况总结成简洁明了的「有监督数据不多,但未标注数据有很多」,然后在查阅论文之后按图索骥找到一类看似可行的方案:半监督学习(semi-supervised learning)。
然后接下来事情就开始走样了。
听上去很美,踏上去是大坑
一直以来,半监督学习都是机器学习领域内的一个大坑,每个尝试想从里面捞到好处的工程师最终都只能对传统的、老式的数据标注增加更多的理解而已。不同的问题里可能会有不同的表现,但是最终大同小异,我们来看下面这张图:
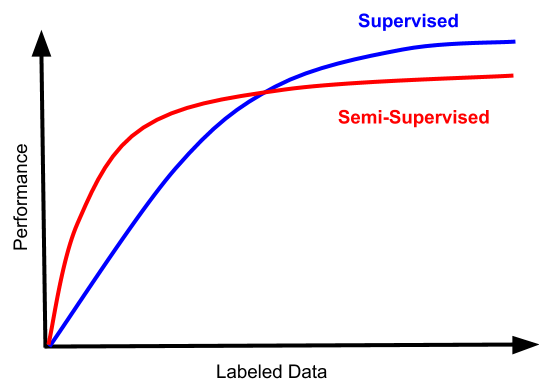
当标注数据不多的时候,半监督学习确实可以带来一定的性能提升。但是实际使用的时候你就会发现,那些提升只能帮你把模型表现从「糟糕透了、不可接受」提高到「稍微好了那么一点、但还是没办法使用」而已。说到底,如果你的标注数据规模较小,以至于半监督学习可以起到帮助的话,那同时也说明你的分类器表现仍然在一个很差的水平,没法实际使用。
除此之外,半监督学习也需要一些额外的资源代价,而且使用了半监督学习的方法面对更多的标注数据的时候,性能增长曲线会比有监督学习更平缓;原因之一是无标注数据可能会带来偏倚(见MITPress-%20SemiSupervised%20Learning.pdf第四节)。在深度学习早期曾经流行过一种半监督学习做法,首先在未标注数据上学习一个自动编码器,然后在有标注数据上进行微调(fine-tune)。现在已经几乎没有人这么做了,因为大家通过无数的实验发现,通过自动编码器学习到的表征会影响到精细调节阶段增加的有标注数据带来的性能提升幅度,而且是起到限制作用。有趣的是,即便今天我们已经大幅度改进了生成式方法,这仍然没能让这个模式变得更好使;这很可能是因为,做出一个好的生成式和模型和做出一个好的分类器毕竟不是一回事。所以结果是,今天的工程师们做微调的时候,他们是在监督学习的基础上做微调的(即便对于语言模型也一样,学习文本其实是一种自监督学习过程) ——从实用角度讲,从其他有监督预训练模型上做迁移学习的效果比从无监督学习模型上做迁移的效果好太多了。
所以,一个一定要尝试半监督学习的机器学习工程师很可能会走上这样一条路径:
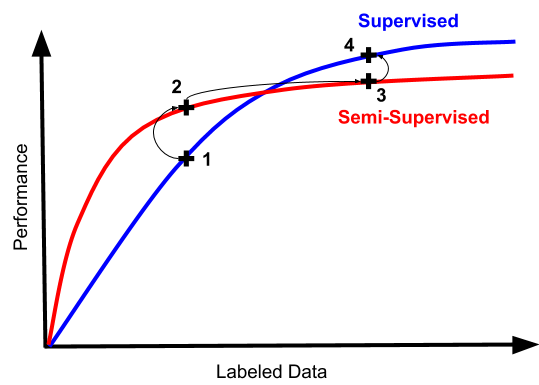
因为数据少,所以模型的表现糟透了。我们试试半监督学习吧(毕竟这还有点技术含量,标数据太枯燥了);
你看,准确率提升了吧!不过数字还是挺低的,看来我们还是得多标一些数据
标数据毕竟还是有用的,我多标好几倍数据以后半监督学习模型的表现又提升了一些。不过我有点好奇,我都标了这么多数据了,直接用监督学习会怎么样
实践证明,有这么多数据以后,监督学习还是更简单直接,效果也更好。那我们为啥不一开始就多标注点数据呢,花了那么多时间精力试了半监督学习结果还是用不上……
如果你比较幸运的话,你的问题有可能会有这样一条性能曲线:
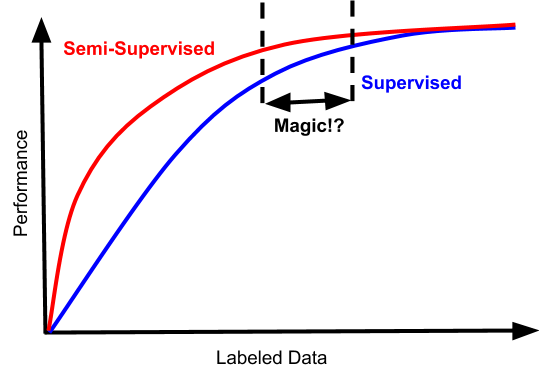
在这种情况下,在某一个数据规模之内半监督学习的效果会好一些,确实提高了数据使用效率。但以我的经验,首先很难达到这样的状况;其次,半监督学习的提升总是不多的,学术论文里刷刷分还行,对实际应用来说影响很小,如果考虑到使用的方法的复杂性和多使用的计算资源的话,还是不如直接多标点数据的投入产出比比较好。
革命来临
不过别急,咱们这篇文章的标题不是「悄悄来临的半监督学习革命」吗?
如今有件事是微微让人兴奋的,那就是半监督学习的性能提升曲线逐渐变成了这个样子:
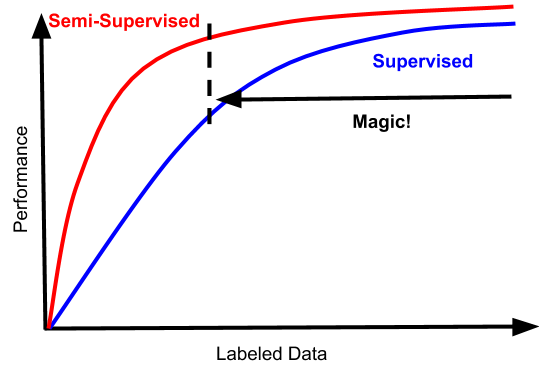
这就会产生真正的区别了。首先,这个曲线符合了所有人对于半监督学习的期待:更多的数据就有更好的性能,而且对于同样的有标注数据,性能总是比监督学习方法更好;即便是数据量足够大、监督学习已经能够发挥出好的效果的范围内,半监督学习也仍然有提升。而且,为了达到这些提升所需要额外付出的计算复杂度和资源也已经很小了。这个「魔法般的区域」的起始点更低,而且不受到数据规模限制。
所以发生了什么呢?很多方面都有了新的改进,比如很多很聪明的方法为数据做自我标注,以及新的表示损失的方法,让损失和数据中的噪声以及自我标注可能带来的偏倚之间相互协调。这两篇论文是近期改进的典型例子,而且也能引领你浏览更多相关的论文:
MixMatch: A Holistic Approach to Semi-Supervised Learning
MixMatch:一种半监督学习的整体性方法
论文摘要:半监督学习方法的提出是为了更好地利用未标注的数据,减轻对于大规模标注数据集的依赖;如今也证明了这是一种强有力的学习范式。在这篇论文中,作者们把当前不同任务中的做法为半监督学习做了统一,得到了一种新的算法,MixMatch,它的工作方式是通过 MixUp 猜测数据扩增方法产生的无标签样本的低熵标签,并把无标签数据和有标签数据混合起来。作者们通过实验表明 MixMatch 在多种不同的数据集、多种不同的有标签数据规模中都能以很大幅度领先此前的所有方法。比如,在 CIFAR 数据集上、只有 250 个标签的情况下,作者们把错误率降低到了之前方法的 1/4,在 STL-10 数据集上也降低到了之前方法的一半。作者们也展示了 MixMatch 可以在差分隐私的使用目的下,在准确率和隐私保护之间取得好得多的平衡。最后,作者们进行了对照实验,分析了 MixMatch 方法中的哪些组件最为关键。
Unsupervised Data Augmentation
无监督数据扩增
论文摘要:面对渴求大量数据的深度学习,数据扩增方法可以缓和一部分需求,但数据扩增方法往往只应用在有监督学习设定中,带来的提升也较为有限。在这篇论文中,作者们提出了一种在半监督学习设定中,把数据扩增方法运用在未标注数据上的新方法。他们的方法,无监督数据扩增 UDA,会鼓励模型面对未标注数据和扩增过的未标注数据时产生一致的预测。与此前使用高斯噪声和 dropout 噪声的方法不同,UDA 有一些小的调整,它借助目前最先进的数据扩增方法产生了难度更高、更真实的噪声。这些小调整让 UDA 在六种语言任务、三种视觉任务中都带来了显著的表现提升,即便使用到的有标注数据集非常小。比如,在 IMDb 数据集的分类测试中,UDA 只使用 20 个标签就得到了比此前最好的方法在 25,000 个有标签数据上训练更好的结果。在标准的半监督学习测试(CIFAR-10,4000 个标签;以及 SVHN,1000 个标签)中,UDA 击败了此前所有的方法,而且把错误率降低了至少 30%。UDA 在大规模数据集上也有好的表现,比如在 ImageNet 上,只需要额外增加 130 万张无标签图像,相比此前的方法,UDA 也可以继续提升首位和前五位命中率。
在半监督学习的整个世界得到革新之后,大家也开始意识到半监督学习可能在机器学习的隐私问题方面可能能够大有作为。比如使用在 PATE 中(有监督数据是需要保护的隐私数据,带有强隐私保护能力的学生模型只能通过无标签数据训练)。有能力保护隐私的知识蒸馏方法也是联邦学习的关键组成部分之一,而联邦学习的效果就是高效的分布式学习,它不需要模型接触全部的用户数据,而且带有数学上强有力的隐私保护。
如今,在真实使用场景中考虑半监督学习已经重新成为了一件很有价值的事情。以前的研究者们对半监督学习的不屑态度如今要受到挑战,这也说明了这个领域内技术水平发展之快。这些趋势出现确实还没有多久,我们也还需要观察这些方法能够经得住时间的考验。但是,如果常用的机器学习工具和范式能从这些新进展中获得大的进步的话,这无疑是十分诱人的。
-
机器学习
+关注
关注
66文章
8112浏览量
130545
原文标题:从聊胜于无到可堪大用,半监督学习革命悄悄来临
文章出处:【微信号:worldofai,微信公众号:worldofai】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
机器学习基础知识全攻略
OpenAI推出Sora:AI领域的革命性突破
基于transformer和自监督学习的路面异常检测方法分享

什么是强化学习


机器学习模型类型分类
适用于任意数据模态的自监督学习数据增强技术

人工智能的关键技术包括哪些
机器学习有哪些算法?机器学习分类算法有哪些?机器学习预判有哪些算法?
人工智能技术包括哪些方面
人工智能ai是什么
人工智能有哪些算法
最新3D表征自监督学习+对比学习:FAC
机器学习步骤详解,一文了解全过程





 工商网监
工商网监
评论