 Nature下一代计算架构革命 从全光学神经网络开始
Nature下一代计算架构革命 从全光学神经网络开始
近日,Nature刊载IBM新研究,使用光学器件打造的“全光学”深度神经网络可以比传统计算方式的能效更高,同时具备可扩展性、无需光电转换和高带宽等优势。这一发现可能给未来光学神经网络加速器的出现打下基础。
光纤能够以光的形式在世界范围内传输数据,成为现代电信技术的支柱。不过如果需要分析这些传输数据,要将其从光信号转换为电子信号,然后用电子设备进行处理。曾经有一段时间,光学被认为是未来最具潜力的计算技术的基础,但与电子计算机的快速进步相比,光学计算技术的竞争力明显不足。
不过,在过去几年中,业界越来越关注对计算能源的成本问题。因此,光学计算系统再次受到关注。光学计算的能耗低,又能作为AI算法(如深度神经网络(DNN))的专用加速硬件。 近日,Feldmann等人在《自然》期刊上发表了这种“全光学网络实现”的最新进展。
深度神经网络包括多层人工神经元和人工突触。这些连接的强度称为网络权重,可以是阳性,表示神经元的兴奋,或阴性,表示神经元的抑制。网络会尽力将实际输出和期望输出之间的差异实现最小化,从而改变突触的权重,来执行图像识别等任务。
CPU和其他硬件加速器通常用于DNN的计算。DNN的训练可以使用已知数据集,而经过训练后的DNN可以用来推理任务中的未知数据。虽然计算量很大,但计算操作的多样性不会很高,因为“乘法累加”操作在许多突触权重和神经元激励中占主导地位。
DNN在计算精度较低时仍能正常工作。因此,DNN网络代表了非传统计算技术的潜在机会。研究人员正在努力打造基于新型非易失性存储器件的DNN加速器。这类设备在切断电源时也能保存信息,通过模拟电子计算提升DNN的速度和能效。
那么,为什么不考虑使用光学器件呢?导光部件中可以包含大量数据 - 无论是用于电信的光纤还是用于光子芯片上的波导。在这种波导内部,可以使用“波分复用”技术,让许多不同波长的光一起传播。然后可以以与电子到光学调制和光电子检测相关的可用带宽限制的速率调制(以可以携带信息的方式改变)每个波长。
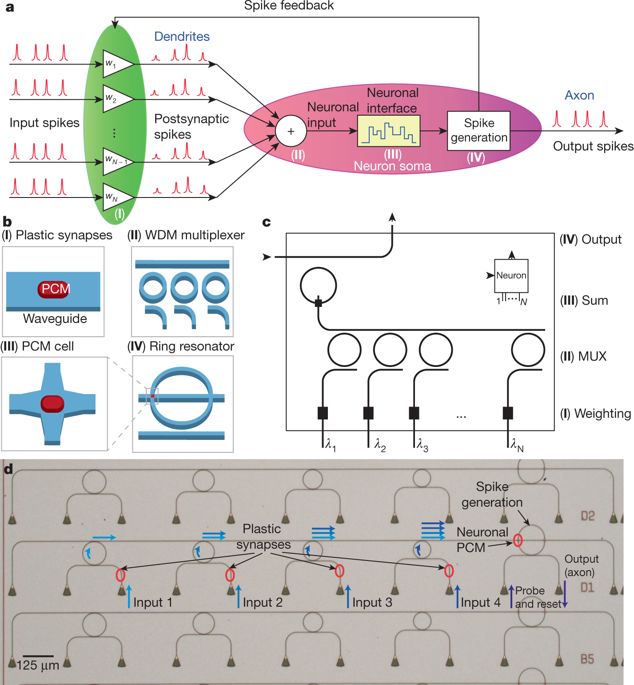
图1全光学脉冲神经元回路
使用谐振器可以实现单个波长的添加或移除,就像对货车的装货和卸货一样。使用微米级环形谐振器可以构建DNN网络突触权重阵列。这种谐振器可以采用热调制,电光调制,或通过相变材料调制。这些材料可以在非晶相和结晶相之间切换,不同的材料的吸光能力差别很大。在理想条件下,进行乘法累加运算的功耗很低。
Feldmann研究团队在毫米级光子芯片上实现了“全光学神经网络”,其中网络内没有使用光电转换。输入的数据被电子调制到不同的波长上注入网络,但此后所有数据都保留在芯片上。利用集成相变材料实现突触权重的调节和神经元的集成。
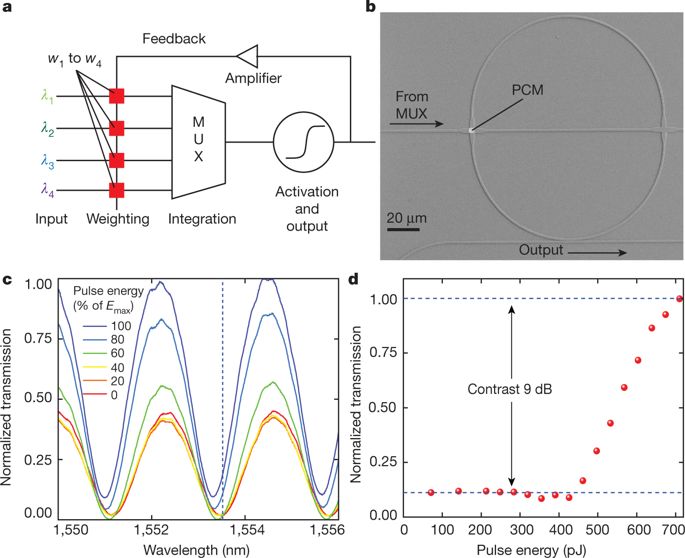
图2人工神经元的脉冲生成与操作
本文作者小规模地展示了有监督和无监督的学习 - 即使用标记数据实现训练(DNN学习的方式),以及使用未标记的数据训练(类似人类的学习方式)。
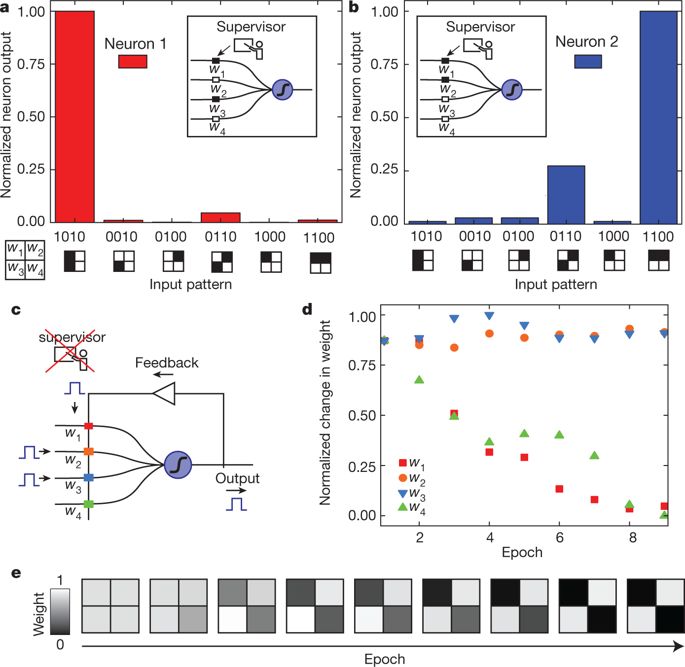
图3基于相变全光学神经元系统实现监督学习和非监督学习
因为权重表达是通过光的吸收实现的,所以负权重需要更大的偏置信号,该信号不能激活相变材料。一种替代方法是使用Mach-Zehnder干涉仪的装置,将单个波导分成两个臂,然后重新组合,这时的透射光量取决于两个传播路径之间光学相位的差异。然而,要想将这种方法与波分复用相结合可能难度较大,因为每个干涉仪的臂需要为每个波长引入适当的相位差。
全光学实现的DNN仍然存在重大挑战。在理想情况下,它们的总功率使用率可能较低,经常需要热光功率来调节和维持每个Mach-Zehnder干涉仪臂中的光学相位差异。
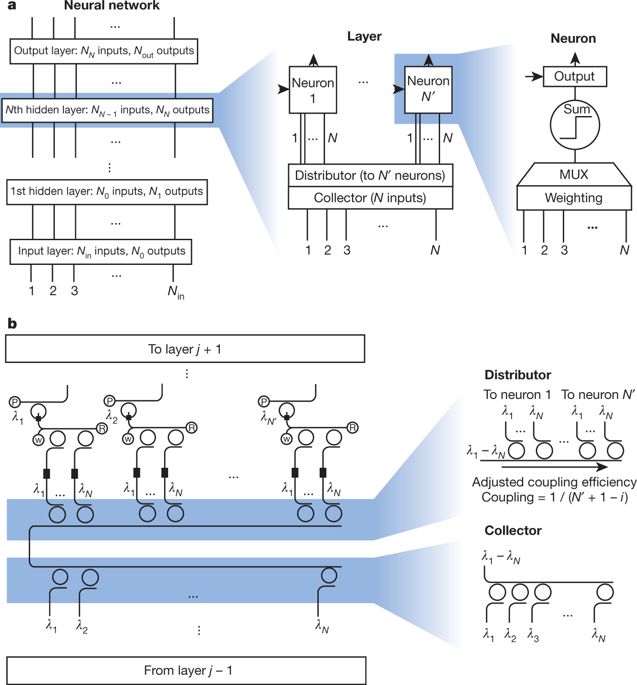
图4全光学神经网络的可扩展架构
此外,对注入含有相变材料的系统的总光功率必须仔细校准,以使材料对输入信号的响应符合预期。尽管相变材料也可以用于调整Mach-Zehnder相位,但是材料吸收光的强度和减慢光速之间会出现不可避免的交叉耦合,这会增加系统的复杂性。
传统的DNN规模已经发展到很大,可能包含数千个神经元和数百万个突触。但是光子网络的波导需要彼此间隔很远才能防止耦合,并且避免急剧弯曲以防止光离开波导。因为两个波导的交叉可能会将不需要的功率注入错误路径,这对光子芯片设计的2D特性造成了实质性的限制。
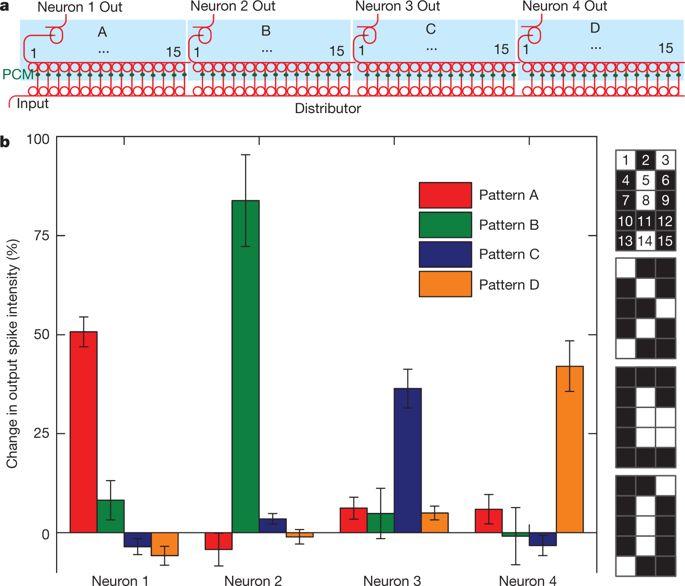
图5单层脉冲神经网络的实验实现
实现光学器件打造神经网络需要很长的距离和很大的面积,但是每个光学结构的关键部分的制造需要高精度。这是因为波导和耦合区域,比如在每个微环谐振器的入口和出口处,必须达到相应网络性能所需的精确尺寸。对于如何制造小型微环谐振器也存在诸多限制。
最后,调制技术提供的光学效应较弱,需要很长的相互作用区域,以使其对通过的光的有限影响能够达到显著水平。
Feldmann 团队的研究中所取得的进步,有望推动该领域的未来发展,该研究可能会为未来高能效、可扩展的光学神经网络加速器的出现打下基础。
-
神经网络
+关注
关注
42文章
4558浏览量
98605 -
光学器件
+关注
关注
1文章
130浏览量
11687
原文标题:Nature最新:下一代计算架构革命,从“全光学神经网络”开始
文章出处:【微信号:aicapital,微信公众号:全球人工智能】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论