 网络爬虫的原理是什么
网络爬虫的原理是什么
网络爬虫原理
网络爬虫指按照一定的规则(模拟人工登录网页的方式),自动抓取网络上的程序。简单的说,就是讲你上网所看到页面上的内容获取下来,并进行存储。网络爬虫的爬行策略分为深度优先和广度优先。如下图是深度优先的一种遍历方式是A到B到D到E到C到F(ABDECF)而宽度优先的遍历方式ABCDEF。
网络爬虫实现原理
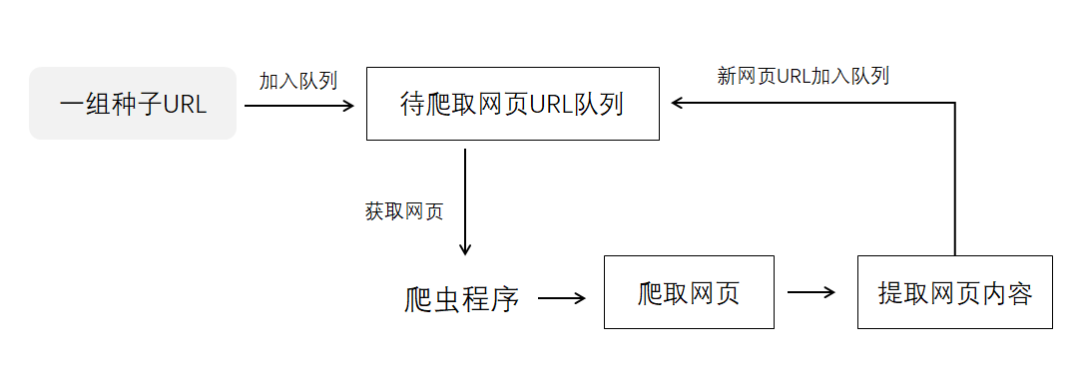
1、获取初始URL。初始URL地址可以有用户人为指定,也可以由用户指定的某个或某几个初始爬取网页决定。
2、根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,首先需要爬取对应URL地址中的网页,爬取了对应的URL地址中的网页后,将网页存储到原始数据库中,并且在爬取网页的同时,发现新的URL地址,同时将已爬取的URL地址存放到一个URL列表中,用于去重及判断爬取的进程。
3、将新的URL放到URL队列中,在第二步中,获取下一个新的URL地址之后,会将新的URL地址放到URL队列中。
4、从URL队列中读取新的URL,并依据新的URL爬取网页,同时从新的网页中获取新的URL并重复上述的爬取过程。
5、满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件。如果没有设置停止条件,爬虫会一直爬取下去,一直到无法获取新的URL地址为止,若设置了停止条件,爬虫则会在停止条件满足时停止爬取。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
网络爬虫
+关注
关注
1文章
50浏览量
8578 -
爬虫
+关注
关注
0文章
77浏览量
6487
发布评论请先 登录
相关推荐
全球新闻网封锁OpenAI和谷歌AI爬虫
分析结果显示,至2023年底,超半数(57%)的传统印刷媒体如《纽约时报》等已关闭OpenAI爬虫,反之电视广播以及数字原生媒体相应地分别为48%和31%。而对于谷歌人工智能爬虫,32%的印刷媒体采取相同措施,电视广播和数字原生媒体的比率分别为19%和17%。
如何解决Python爬虫中文乱码问题?Python爬虫中文乱码的解决方法
如何解决Python爬虫中文乱码问题?Python爬虫中文乱码的解决方法 在Python爬虫过程中,遇到中文乱码问题是常见的情况。乱码问题主要是由于编码不一致所导致的,下面我将详细介绍如何解
爬虫的基本工作原理 用Scrapy实现一个简单的爬虫
数以万亿的网页通过链接构成了互联网,爬虫的工作就是从这数以万亿的网页中爬取需要的网页,从网页中采集内容并形成结构化的数据。
Python网络爬虫Selenium的简单使用
想要学习爬虫,如果比较详细的了解web开发的前端知识会更加容易上手,时间不够充裕,仅仅了解html的相关知识也是够用的。
如何看待Python爬虫的合法性?
Python爬虫是一种自动化程序,可以从互联网上获取信息并提取数据。通过模拟网页浏览器的行为,爬虫可以访问网页、抓取数据、解析内容,并将其保存到本地或用于进一步分析
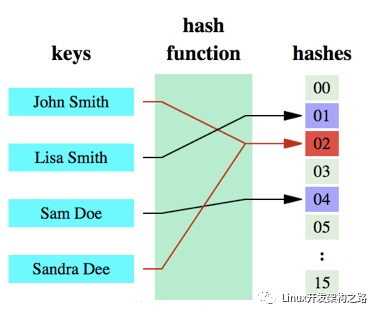
什么情况下需要布隆过滤器
什么情况下需要布隆过滤器? 先来看几个比较常见的例子 字处理软件中,需要检查一个英语单词是否拼写正确 在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上 在网络爬虫里,一个网址是否被访问过 yahoo
Python 一个超快的公共情报搜集爬虫
Photon是一个由s0md3v开源的情报搜集爬虫,其主要功能有: 1.爬取链接(内链、外链)。 2.爬取带参数的链接,如(pythondict.com/test?id=2)。 3.文件(pdf
crawlerdetect:Python 三行代码检测爬虫
是否担心高频率爬虫导致网站瘫痪? 别担心,现在有一个Python写的神器——crawlerdetect,帮助你检测爬虫,保障网站的正常运转。 1.准备 开始之前,你要确保Python和pip已经成功
feapder:一款功能强大的爬虫框架
今天推荐一款更加简单、轻量级,且功能强大的爬虫框架:feapder 项目地址: https://github.com/Boris-code/feapder 2. 介绍及安装 和 Scrapy 类似
Photon:一个超快的公共情报搜集爬虫
Photon是一个由s0md3v开源的情报搜集爬虫,其主要功能有: 1.爬取链接(内链、外链)。 2.爬取带参数的链接,如(pythondict.com/test?id=2)。 3.文件(pdf
Playwright 的基本用法
的 API,Playwright 同时也可以作为网络爬虫的一个爬取利器。 1. Playwright 的特点 Playwright 支持当前所有主

网络爬虫 Python和数据分析
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的
发表于 09-25 08:25







 工商网监
工商网监
评论