 谷歌开源了一个强大的NLP深度学习框架Lingvo
谷歌开源了一个强大的NLP深度学习框架Lingvo
谷歌近日开源了一个强大的NLP深度学习框架Lingvo,侧重于语言相关任务的序列模型,如机器翻译、语音识别和语音合成。过去两年来,谷歌已经发表了几十篇使用Lingvo获得SOTA结果的论文。
近日,谷歌开源了一个内部 NLP 的秘密武器 ——Lingvo。
这是一个强大的 NLP 框架,已经在谷歌数十篇论文的许多任务中实现 SOTA 性能!
Lingvo 在世界语中意为 “语言”。这个命名暗指了 Lingvo 框架的根源 ——它是使用 TensorFlow 开发的一个通用深度学习框架,侧重于语言相关任务的序列模型,如机器翻译、语音识别和语音合成。
Lingvo 框架在谷歌内部已经获得青睐,使用它的研究人员数量激增。过去两年来,谷歌已经发表了几十篇使用 Lingvo 获得 SOTA 结果的论文,未来还会有更多。
包括 2016 年机器翻译领域里程碑式的《谷歌神经机器翻译系统》论文 (Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation),也是使用 Lingvo。该研究开启了机器翻译的新篇章,宣告机器翻译正式从 IBM 的统计机器翻译模型 (PBMT,基于短语的机器翻译),过渡到了神经网络机器翻译模型。该系统使得机器翻译误差降低了 55%-85% 以上,极大地接近了普通人的翻译水平。
除了机器翻译之外,Lingvo 框架也被用于语音识别、语言理解、语音合成、语音 - 文本转写等任务。
谷歌列举了 26 篇使用 Lingvo 框架的 NLP 论文,发表于 ACL、EMNLP、ICASSP 等领域顶会,取得多个 SOTA 结果。全部论文见文末列表。
Lingvo 支持的架构包括传统的RNN 序列模型、Transformer 模型以及包含 VAE 组件的模型,等等。
谷歌表示:“为了表明我们对研究界的支持并鼓励可重复的研究工作,我们公开了该框架的源代码,并开始发布我们论文中使用的模型。”
此外,谷歌还发布了一篇概述 Lingvo 设计的论文,并介绍了框架的各个部分,同时提供了展示框架功能的高级特性的示例。
相关论文:
https://arxiv.org/pdf/1902.08295.pdf

强悍的贡献者列表 ——91 位作者!
摘要
Lingvo 是一个 Tensorflow 框架,为协作式深度学习研究提供了一个完整的解决方案,特别侧重于sequence-to-sequence模型。Lingvo 模型由灵活且易于扩展的模块化构建块组成,实验配置集中且高度可定制。该框架直接支持分布式训练和量化推理,包含大量实用工具、辅助函数和最新研究思想的现有实现。论文概述了 Lingvo 的基础设计,并介绍了框架的各个部分,同时提供了展示框架功能的高级特性的示例。
为协作研究设计、灵活、快速
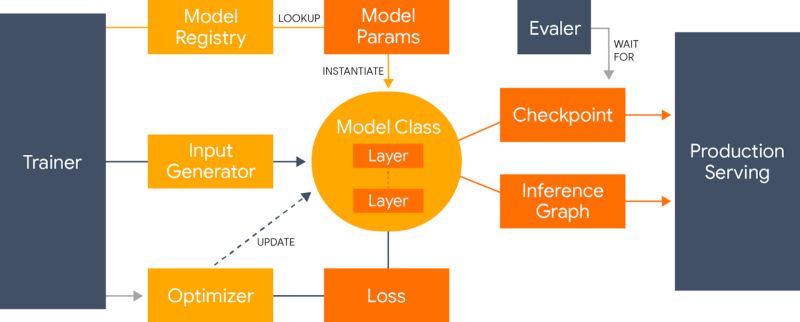
Lingvo 框架概览:概述了如何实例化、训练和导出模型以进行评估和服务。
Lingvo 是在考虑协作研究的基础下构建的,它通过在不同任务之间共享公共层的实现来促进代码重用。此外,所有层都实现相同的公共接口,并以相同的方式布局。这不仅可以生成更清晰、更易于理解的代码,还可以非常简单地将其他人为其他任务所做的改进应用到自己的任务中。强制实现这种一致性的代价是需要更多的规则和样板,但是 Lingvo 试图将其最小化,以确保研究期间的快速迭代时间。
协作的另一个方面是共享可重现的结果。Lingvo 为检入模型超参数配置提供了一个集中的位置。这不仅可以记录重要的实验,还可以通过训练相同的模型,为其他人提供一种简单的方法来重现你的结果。

Lingvo 中的任务配置示例。每个实验的超参数都在它自己的类中配置,与构建网络的代码分开,并检入版本控制。
虽然 Lingvo 最初的重点是 NLP,但它本质上非常灵活,并且研究人员已经使用该框架成功地实现了图像分割和点云分类等任务的模型。它还支持 Distillation、GANs 和多任务模型。
同时,该框架不牺牲速度,并且具有优化的输入 pipeline 和快速分布式训练。
最后,Lingvo 的目的是实现简单生产,甚至有一条明确定义的为移动推理移植模型的路径。
使用Lingvo的已发表论文列表
Translation:
The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation.Mia X. Chen, Orhan Firat, Ankur Bapna, Melvin Johnson, Wolfgang Macherey, George Foster, Llion Jones, Mike Schuster, Noam Shazeer, Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Zhifeng Chen, Yonghui Wu, and Macduff Hughes. ACL 2018.
Revisiting Character-Based Neural Machine Translation with Capacity and Compression.Colin Cherry, George Foster, Ankur Bapna, Orhan Firat, and Wolfgang Macherey. EMNLP 2018.
Training Deeper Neural Machine Translation Models with Transparent Attention.Ankur Bapna, Mia X. Chen, Orhan Firat, Yuan Cao and Yonghui Wu. EMNLP 2018.
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation.Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, and Jeffrey Dean. Technical Report, 2016.
Speech Recognition:
A comparison of techniques for language model integration in encoder-decoder speech recognition.Shubham Toshniwal, Anjuli Kannan, Chung-Cheng Chiu, Yonghui Wu, Tara N. Sainath, Karen Livescu. IEEE SLT 2018.
Deep Context: End-to-End Contextual Speech Recognition.Golan Pundak, Tara N. Sainath, Rohit Prabhavalkar, Anjuli Kannan, Ding Zhao. IEEE SLT 2018.
Speech recognition for medical conversations.Chung-Cheng Chiu, Anshuman Tripathi, Katherine Chou, Chris Co, Navdeep Jaitly, Diana Jaunzeikare, Anjuli Kannan, Patrick Nguyen, Hasim Sak, Ananth Sankar, Justin Tansuwan, Nathan Wan, Yonghui Wu, and Xuedong Zhang. Interspeech 2018.
Compression of End-to-End Models.Ruoming Pang, Tara Sainath, Rohit Prabhavalkar, Suyog Gupta, Yonghui Wu, Shuyuan Zhang, and Chung-Cheng Chiu. Interspeech 2018.
Contextual Speech Recognition in End-to-End Neural Network Systems using Beam Search.Ian Williams, Anjuli Kannan, Petar Aleksic, David Rybach, and Tara N. Sainath. Interspeech 2018.
State-of-the-art Speech Recognition With Sequence-to-Sequence Models.Chung-Cheng Chiu, Tara N. Sainath, Yonghui Wu, Rohit Prabhavalkar, Patrick Nguyen, Zhifeng Chen, Anjuli Kannan, Ron J. Weiss, Kanishka Rao, Ekaterina Gonina, Navdeep Jaitly, Bo Li, Jan Chorowski, and Michiel Bacchiani. ICASSP 2018.
End-to-End Multilingual Speech Recognition using Encoder-Decoder Models.Shubham Toshniwal, Tara N. Sainath, Ron J. Weiss, Bo Li, Pedro Moreno, Eugene Weinstein, and Kanishka Rao. ICASSP 2018.
Multi-Dialect Speech Recognition With a Single Sequence-to-Sequence Model.Bo Li, Tara N. Sainath, Khe Chai Sim, Michiel Bacchiani, Eugene Weinstein, Patrick Nguyen, Zhifeng Chen, Yonghui Wu, and Kanishka Rao. ICASSP 2018.
Improving the Performance of Online Neural Transducer Models.Tara N. Sainath, Chung-Cheng Chiu, Rohit Prabhavalkar, Anjuli Kannan, Yonghui Wu, Patrick Nguyen, and Zhifeng Chen. ICASSP 2018.
Minimum Word Error Rate Training for Attention-based Sequence-to-Sequence Models.Rohit Prabhavalkar, Tara N. Sainath, Yonghui Wu, Patrick Nguyen, Zhifeng Chen, Chung-Cheng Chiu, and Anjuli Kannan. ICASSP 2018.
No Need for a Lexicon? Evaluating the Value of the Pronunciation Lexica inEnd-to-End Models.Tara N. Sainath, Rohit Prabhavalkar, Shankar Kumar, Seungji Lee, Anjuli Kannan, David Rybach, Vlad Schogol, Patrick Nguyen, Bo Li, Yonghui Wu, Zhifeng Chen, and Chung-Cheng Chiu. ICASSP 2018.
Learning hard alignments with variational inference.Dieterich Lawson, Chung-Cheng Chiu, George Tucker, Colin Raffel, Kevin Swersky, and Navdeep Jaitly. ICASSP 2018.
Monotonic Chunkwise Attention.Chung-Cheng Chiu, and Colin Raffel. ICLR 2018.
An Analysis of Incorporating an External Language Model into a Sequence-to-Sequence Model.Anjuli Kannan, Yonghui Wu, Patrick Nguyen, Tara N. Sainath, Zhifeng Chen, and Rohit Prabhavalkar. ICASSP 2018.
Language understanding
Semi-Supervised Learning for Information Extraction from Dialogue.Anjuli Kannan, Kai Chen, Diana Jaunzeikare, and Alvin Rajkomar. Interspeech 2018.
CaLcs: Continuously Approximating Longest Common Subsequence for Sequence Level Optimization.Semih Yavuz, Chung-Cheng Chiu, Patrick Nguyen, and Yonghui Wu. EMNLP 2018.
Speech synthesis
Hierarchical Generative Modeling for Controllable Speech Synthesis.Wei-Ning Hsu, Yu Zhang, Ron J. Weiss, Heiga Zen, Yonghui Wu, Yuxuan Wang, Yuan Cao, Ye Jia, Zhifeng Chen, Jonathan Shen, Patrick Nguyen, Ruoming Pang. Submitted to ICLR 2019.
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis.Ye Jia, Yu Zhang, Ron J. Weiss, Quan Wang, Jonathan Shen, Fei Ren, Zhifeng Chen, Patrick Nguyen, Ruoming Pang, Ignacio Lopez Moreno, Yonghui Wu. NIPS 2018.
Natural TTS Synthesis By Conditioning WaveNet On Mel Spectrogram Predictions.Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu. ICASSP 2018.
On Using Backpropagation for Speech Texture Generation and Voice Conversion.Jan Chorowski, Ron J. Weiss, Rif A. Saurous, Samy Bengio. ICASSP 2018.
Speech-to-text translation
Leveraging weakly supervised data to improve end-to-end speech-to-text translation.Ye Jia, Melvin Johnson, Wolfgang Macherey, Ron J. Weiss, Yuan Cao, Chung-Cheng Chiu, Naveen Ari, Stella Laurenzo, Yonghui Wu. Submitted to ICASSP 2019.
Sequence-to-Sequence Models Can Directly Translate Foreign Speech.Ron J. Weiss, Jan Chorowski, Navdeep Jaitly, Yonghui Wu, and Zhifeng Chen. Interspeech 2017.
https://github.com/tensorflow/lingvo/blob/master/PUBLICATIONS.md
开源地址:
https://github.com/tensorflow/lingvo
-
谷歌
+关注
关注
27文章
5850浏览量
103246 -
深度学习
+关注
关注
73文章
5236浏览量
119893 -
nlp
+关注
关注
1文章
463浏览量
21817
原文标题:谷歌重磅开源NLP通用框架,20多篇最新论文都用了它
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
谷歌模型框架是什么软件?谷歌模型框架怎么用?
谷歌模型框架是什么?有哪些功能和应用?
深度学习cntk框架介绍
深度学习框架对照表
人工智能深度学习的框架简述
计算机视觉深度学习训练推理框架






 工商网监
工商网监
评论