 一个基于TF2.0的强化学习训练工具
一个基于TF2.0的强化学习训练工具
近日,Github 一位开发者 danaugrs 开源了一个新项目——Huskarl,一个专注研究和快速原型的深度强化学习框架。
此框架基于 TensorFlow 2.0 构建,使用了 tf.keras API,保证了其简洁性和可读性。Huskarl 可以使多环境的并行计算变得很容易,这将对加速策略学习算法(比如 A2C 和 PPO)非常有用。此外,Huskarl 还可以与 OpenAI Gym 环境无缝结合,并将计划支持多代理环境和 Unity3D 环境。
OpenAI Gym:2016 年 OpenAI 发布的一个可以开发、对比强化学习算法的工具包,提供了各种环境、模拟任务等,任何人都可以在上面训练自己的算法。
Unity3D:一个全面整合的专业游戏引擎,由 Unity Technologies 开发的一款可以让玩家轻松创建三维视频游戏、实时三维动画等类型互动内容的多平台综合型游戏开发工具。
目前,Huskarl 已经支持了 DQN(Deep Q-Learning Network)、Multi-step DQN、Double DQN、A2C(Advantage Actor-Critic)等算法,还有 DDPG(Deep Deterministic Policy Gradient)、PPO(Proximal Policy Optimization)、Curiosity-Driven Exploration 等算法在计划中。

最重要的是,TF 2.0 的 nightly 已经发布,这个开源工具也是基于 TF2.0 开发的,所以大家要先安装一下 tf 2.0 nighty 版本。除此之外,还需要安装以下工具和环境:
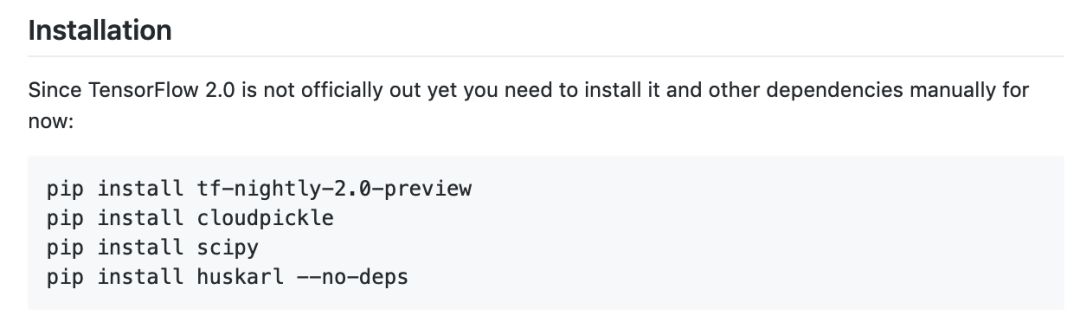
这个工具还是新鲜出炉烫手的呢,大家赶紧来尝鲜试一下~
地址:
https://github.com/danaugrs/huskarl
-
强化学习
+关注
关注
4文章
258浏览量
11112 -
tensorflow
+关注
关注
13文章
313浏览量
60241 -
开源工具
+关注
关注
0文章
26浏览量
4390
原文标题:新鲜开源:基于TF2.0的深度强化学习平台
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

NeurIPS 2023 | 扩散模型解决多任务强化学习问题

模拟矩阵在深度强化学习智能控制系统中的应用

深度学习框架区分训练还是推理吗
大模型训练中RM分数越来越高,那训出来LLM的效果一定好吗?
语言模型做先验,统一强化学习智能体,DeepMind选择走这条通用AI之路

基于强化学习的目标检测算法案例

什么是深度强化学习?深度强化学习算法应用分析


利用强化学习来探索更优排序算法的AI系统

基于深度强化学习的视觉反馈机械臂抓取系统
ICLR 2023 Spotlight|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架RLx2

彻底改变算法交易:强化学习的力量
基于多智能体深度强化学习的体系任务分配方法





 工商网监
工商网监
评论