 Face++ Detection Team在2018年做COCO skeleton的工作
Face++ Detection Team在2018年做COCO skeleton的工作
本文主要介绍了 Face++DetectionTeam 在 2018 年做 COCO skeleton 的工作。
Background
人体关键点检测(Human Keypoint Detection)又称为人体姿态识别,旨在准确定位图像之中人体关节点的位置,是人体动作识别、人体行为分析、人机交互的前置任务。作为当前计算机视觉不可或缺的热门研究领域之一,人体姿态识别有着大量的落地场景和广阔的应用前景,现有及可期的场景应用有人体步态识别、体感游戏、AI 美体、虚拟现实、增强现实、康复训练、体育教学等等,可广泛赋能于游戏、手机、医疗、教育、数字现实等不同领域。
人体关键点检测任务对于现实生活有着很大的潜在用途,目前公开的比赛中最权威的是 MS COCO Keypoint track 的比赛,也是该领域最有挑战的比赛,参赛队不乏 Facebook,Google 及微软这样的国际巨头,也不乏 CMU 等顶尖研究机构,是该领域最先进方法的试金石。旷视科技 Detection 组在2017,2018 年两次夺得该比赛的冠军,2017 年旷视 COCO Keypoint 比赛冠军工作 CPN 在业界具有深远影响,并获得广泛使用。这里,我们将介绍旷视 2018 年 COCO Keypoint 比赛夺冠的工作。
人体姿态识别主流方法目前分为两种:单阶段和多阶段,虽然后者遵照从粗糙到精细的逻辑更贴合任务本质,但是目前表现似乎没有优于单阶段方法,我们认为,目前多阶段方法差强人意的性能主要归因于多种不合理的设计。我们的工作从 1)网络设计、2)特征流、3)损失函数入手提出一系列改进措施,工作成果在 MS COCO Keypoint 数据集上超越现有方法取得当前最优结果,论文已公开于 Arxiv,链接请见:arxiv.org/abs/1901.0014
Introduction
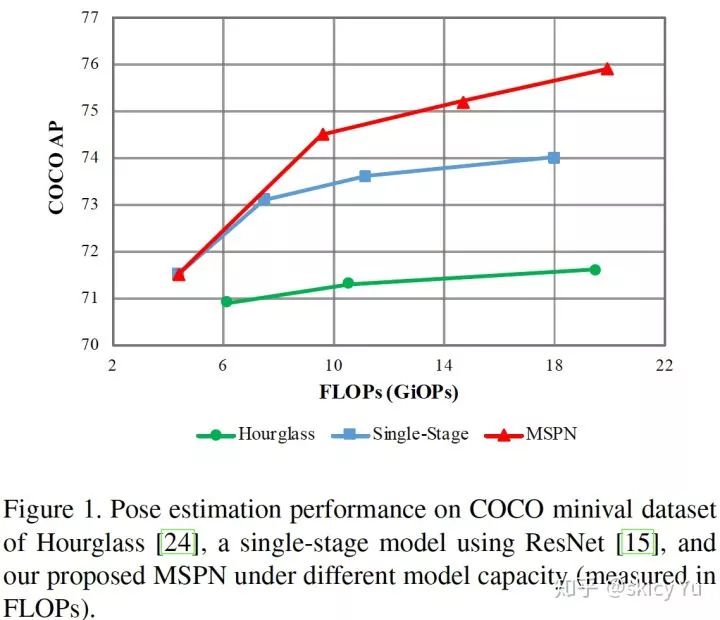
图1
深度卷积网络出现之后,人体姿态识别飞速发展。现阶段最优方法[1,2]网络结构较为简单,多是采用单阶段网络设计,比如 2017 COCO Keypoint 挑战赛冠军方法[1]采用基于 ResNet-Inception 的网络结构,最新的 Simple Baseline[2] 采用 ResNet 网络结构。另一种网络结构则采用多阶段网络设计,即把一个轻量级网络作为单元网络,接着将其简单地堆叠到多阶段。
直观上讲,多阶段的天然逐级优化特性会更适用于这个任务,但是当前存在的多阶段网络并没有单阶段网络在 COCO 上表现好。我们试图研究这一挑战性问题,提出当前多阶段网络的欠佳表现主要是由于设计不足导致的,并可通过一系列 1)网络结构、2)特征流、3)损失函数方面的创新性优化,最大化发掘多阶段网络的潜力,实现目前最先进的效果。
因此,我们提出新型的多阶段姿态估计网络 MSPN,具体改进有 3 个方面:
目前多阶段网络里的单元网络离最优比较远,使用已经验证的网络(如 Resnet)要比主流的多阶段方法(如 Hourglass)采用的轻量级网络好很多,究其原因主要是下采样 Encoder 需要承载更多内容,而轻量级网络满足不了。
由于重复下采样,上采样会丢失信息从而不利于学习,我们提出融合多阶段特征以加强信息流动,来缓解这一问题。
我们观察到关节点的定位是逐级精细优化的,因此提出由粗到精的学习策略,并采用多尺度监督提升训练。由图 1 可知,当提升单阶段网络容量时,精度会趋近于饱和,而增长遇到瓶颈;对于目前主流的多阶段网络,当堆叠多于 2 个单元网络后,精度提升非常有限。对于我们提出的 MSPN,随着单元网络的堆叠数增加,精度会持续提升。
在 MS COCO 基准上,MSPN 在 test-dev 数据集上获得 76.1 AP;在 MS COCO 2018 中,test-dev 达到 78.1 AP,test-challenge 76.4 AP, 相比去年冠军提升了 4.3 AP。
--------多阶段网络---------
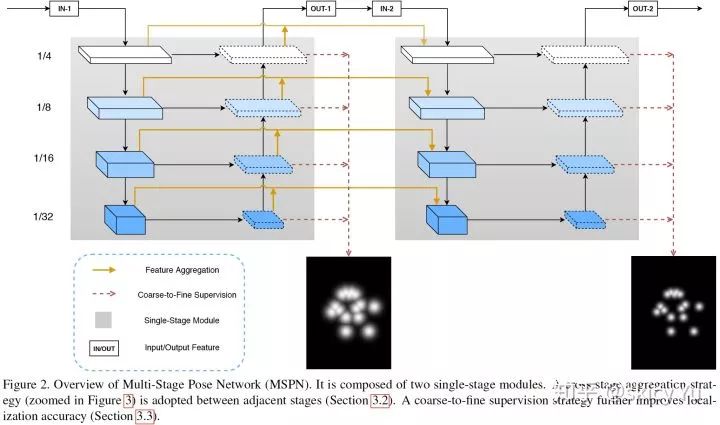
图2
多阶段姿态估计网络 MSPN 如图 2 所示。它采用自上向下的框架,即首先使用人体检测算法给出人体框,据此抠图,并进行单人人体姿态估计。如上所述,MSPN 的新突破有 3 点:第一,使用图像分类表现较好的网络(如 ResNet)作为多阶段网络的单元网络;第二,提出逐阶段传递的信息聚集方式,降低信息损失;第三,引入由粗到精的监督,并进行多尺度监督。
------有效的单阶段子单元网络设计-----
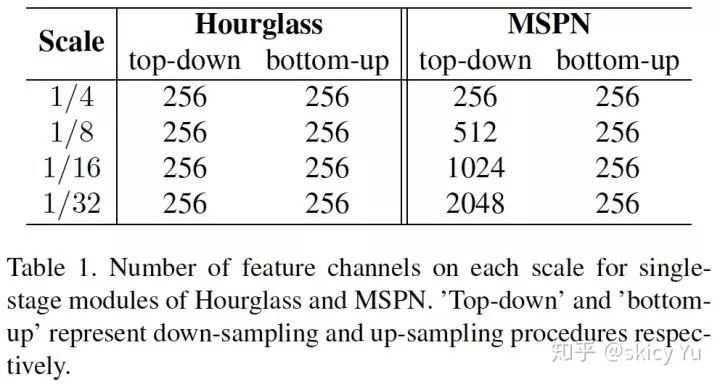
表1
目前主流的多阶段网络全部基于 Hourglass 变体。从表 1 可知,Hourglass 在重复下采样和上采样的过程中,卷积层的通道数是相同的。这是因为高层语义信息更强,需要更多通道表征。
下采样时,Hourglass 变体会导致特征编码(Encoder)无法很好地表达特征,从而造成一定程度上的特征信息丢失。相比于下采样,上采样很难更优地表征特征,所以增加下采样阶段的网络能力对整体网络会更有效。
--------------跨阶段特征融合-------------
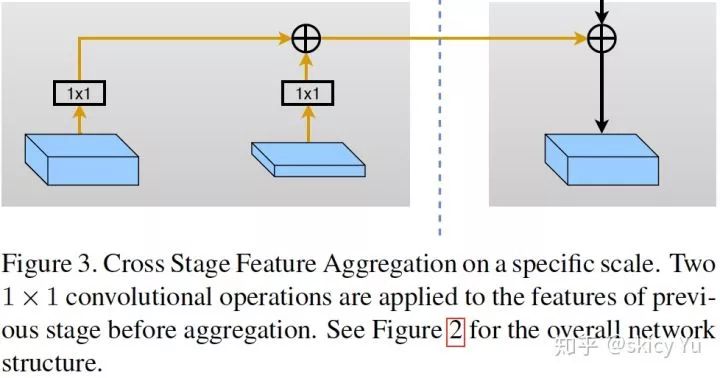
图3
多阶段网络在重复的上采样和下采样过程中,很容易造成信息流失,我们提出了一种有效的跨阶段特征融合方法来应对这一现象。如图 3 所示,上一阶段上、下采样的特征经过 1x1 卷积相加到后一阶段下采样部分,从而实现多阶段之间的特征融合,有效缓解特征流失。
---------------由粗到精监督--------------
图4
人体姿态估计如果要定位较有挑战性的关节点(如隐藏关节点)需要较强的领域上下文信息。同时,对于基于回归 heatmap 的任务,作为 GT 的高斯核越小,回归精度越准。考虑到以上两点,并结合多阶段网络的自身逐级递进优化的特性,我们提出基于多阶段的由粗到精的监督方式。每个阶段方式的监督heatmap的高斯核逐渐减小,可较理想地兼顾领域上下文信息和精准度。由于中间监督对于深度神经网络有较好效果[3],我们在每个阶段内部也采用了多尺度的中间监督。
-------------实验-------------
实验中,我们使用 MegDet [4]获得人体检测框,并使用 COCO(80 类)之中人这一类的结果作为人体框结果,没有单独针对人进行训练。抠图之前,框扩展为高宽 4:3 的比例。训练中,我们采用 Adam 作为优化策略,初始学习率为 5e-4,Weight Decay 为 1e-5。数据增强方面,主要采用翻转、旋转(-45度~+45度)、尺度变换(0.7~1.35)。姿态估计网络图像输入尺寸为 384x288。消融实验中,图像输入尺寸为 256x192。测试方面,沿用 [5] 中的策略,即采用翻转求平均,最大值位置向次大值位置偏移 1/4 作为最终位置。所有消融实验在 COCO minival 上进行。
消融实验
多阶段网络
我们通过一系列实验验证多阶段网络设计的重要性。
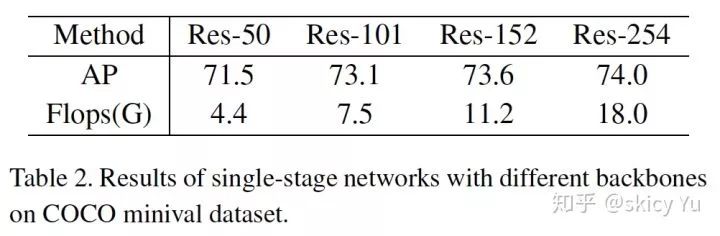
表2
首先,我们通过实验观察单阶段网络增加模型复杂度的表现。从表 2 可知,ResNet-50 作为 Backbone 的单阶段网络精度可以达到 71.5,ResNet-101 可以提升 1.6 个点,但是继续往高增加复杂度,精度的提升幅度逐渐变小,趋近于饱和。
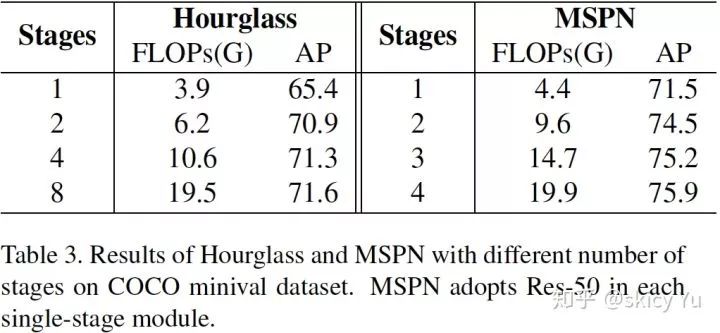
表3
我们同时对比了当前主流的多阶段网络 Hourglass 与该工作在精度提升方面的差异。由表 3 可知,Hourglass 在第 2 个阶段以上叠加新阶段提升非常有限:从 2 个阶段到 8 个阶段,计算量增加 3 倍,而精度只涨了 0.7 AP。相比于 Hourglass 的增长受限,MSPN 从第 2 个阶段以上叠加新阶段会持续提升精度。
为验证我们对多阶段网络有效改进的泛化性,我们尝试把其他网络作为单元网络。如表 4,两阶段的 ResNet-18 会稍高于相当计算量的单阶段 ResNet-50 网络。4 阶段小计算量的 X-ception 网络会比同计算量单阶段的大计算量的 X-ception 网络高出近 1 AP。

表4
跨阶段特征融合以及由粗到精监督
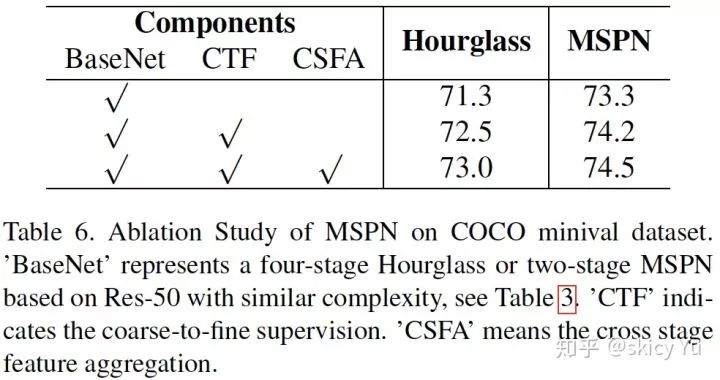
表5
表 5 的实验可以验证跨阶段特征融合以及由粗到精监督的有效性。对于 4 阶段的 Hourglass 和 2 阶段的 MSPN 借助以上两种策略均实现涨点。
------------实验结果-------------
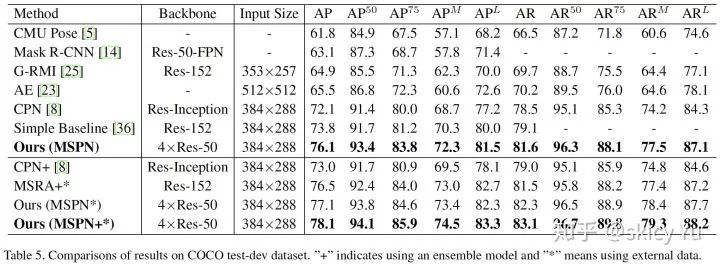
表6
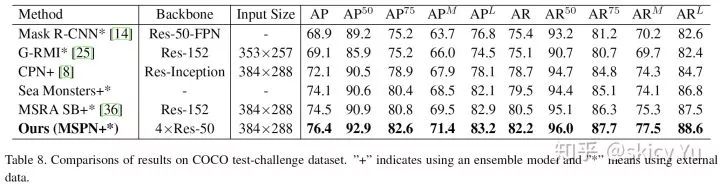
表7
表 6 和表 7 分别对比 MSPN 与当前最优方法在 COCO test-dev 数据集和 COCO test-challenge 数据集上的精度差异。可以看出,MSPN 均超过当前最优方法,在 test-dev 上领先2.3 AP,在 test-challenge上领先 1.9 AP。
----------------总结---------------
我们提出了针对人体姿态估计更有效的多阶段网络设计思想,并用充分的实验验证其有效性,该网络在 COCO 数据集上突破当前的精度瓶颈,实现了新的 state-of-the-art。我们同时也验证了该工作所涉及的多阶段网络设计思想的泛化性。
--------------结果例图-----------
图5
-
人机交互
+关注
关注
12文章
1120浏览量
54747 -
网络
+关注
关注
14文章
7248浏览量
87406 -
数据集
+关注
关注
4文章
1176浏览量
24340
原文标题:COCO 2018 Keypoint冠军算法解读
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
2018年,人脸识别领域有哪些值得关注的企业呢?
发布一个基于face++的人脸识别程序
Face ID也是无法工作
Face ID也是无法工作。
opencv和face++如何进行人脸检测吗?
VHDL Decoder Skeleton
2016高交会思必驰携手旷视Face++展现人工智能技术力量
人脸识别技术大总结1—Face Detection Alignment
哪些公司入股旷视科技Face++
旷视科技face++股东名单_旷视科技face++历史几轮融资情况
Megvii Face++面部识别技术介绍
艾迈斯半导体与Face++携手打造领先的3D技术

低亮度人脸检测、附源码——CVPR2021之 Low Light Face Detection【一文读懂】






 工商网监
工商网监
评论