 基于计算机视觉的自动搜索图像语义分割架构
基于计算机视觉的自动搜索图像语义分割架构
近日,斯坦福大学李飞飞组的研究者提出了 Auto-DeepLab,其在图像语义分割问题上超越了很多业内最佳模型,甚至可以在未经过预训练的情况下达到预训练模型的表现。Auto-DeepLab 开发出与分层架构搜索空间完全匹配的离散架构的连续松弛,显著提高架构搜索的效率,降低算力需求。
深度神经网络已经在很多人工智能任务上取得了成功,包括图像识别、语音识别、机器翻译等。虽然更好的优化器 [36] 和归一化技术 [32, 79] 在其中起了重要作用,但很多进步要归功于神经网络架构的设计。在计算机视觉中,这适用于图像分类和密集图像预测。
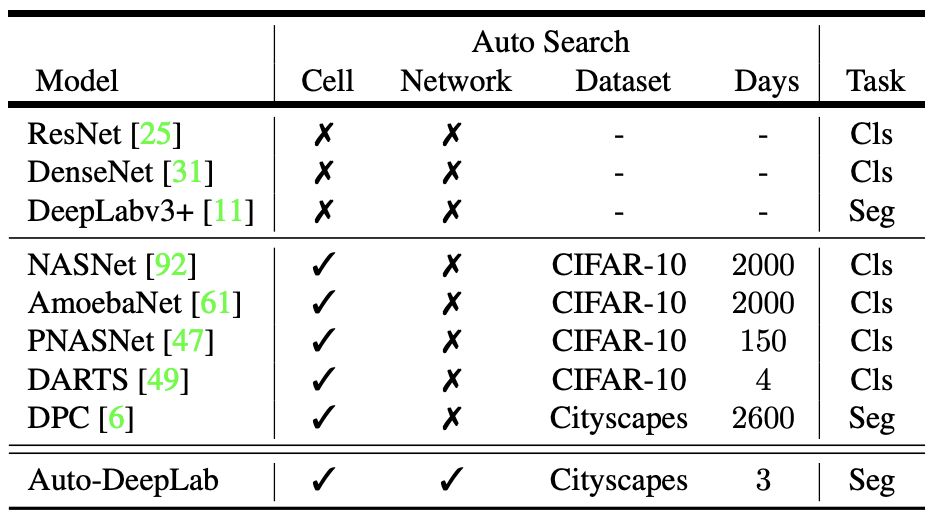
表 1:本研究提出的模型 Auto-DeepLab 和其它双层 CNN 架构的对比。主要区别有:(1) Auto-DeepLab 直接搜索用于语义分割的 CNN 架构;(2) Auto-DeepLab 搜索网络级架构和单元级架构;(3) Auto-DeepLab 的高效搜索在一个 P100 GPU 上仅需 3 天。
最近,在AutoML和 AI 民主化的影响下,人们对自动化设计神经网络架构产生了极大兴趣,自动化设计神经网络无需严重依赖专家经验和知识。更重要的是,去年神经架构搜索(NAS)成功找到了在大规模图像分类任务上超越人类设计架构的网络架构 [92, 47, 61]。
图像分类对 NAS 来说是一个很好的起点,因为它是最基础且研究最深入的高级识别任务。此外,该研究领域存在具有规模相对较小的基准数据集(如 CIFAR-10),从而减少了计算量并加快了训练速度。然而,图像分类不应该是 NAS 的终点,现下的成功表明它可以扩展至要求更高的领域。在本文中,作者研究了用于语义图像分割的神经架构搜索。这是一项重要的计算机视觉任务,它为输入图像的每个像素分配标签,如「人」或「自行车」。
简单地移植图像分类的方法不足以进行语义分割。在图像分类中,NAS 通常使用从低分辨率图像到高分辨率图像的迁移学习 [92],而语义分割的最佳架构必须在高分辨率图像上运行。这表明,本研究需要:(1) 更松弛、更通用的搜索空间,以捕捉更高分辨率导致的架构变体;(2) 更高效的架构搜索技术,因为高分辨率需要的计算量更大。
作者注意到,现代 CNN 设计通常遵循两级分层结构,其中外层网络控制空间分辨率的变化,内层单元级架构管理特定的分层计算。目前关于 NAS 的绝大多数研究都遵循这个两级分层设计,但只自动化搜索内层网络,而手动设计外层网络。这种有限的搜索空间对密集图像预测来说是一个问题,密集图像预测对空间分辨率变化很敏感。因此在本研究中,作者提出了一种格子状的网络级搜索空间,该搜索空间可以增强 [92] 首次提出的常用单元级搜索空间,以形成分层架构搜索空间。本研究的目标是联合学习可重复单元结构和网络结构的良好组合,用于语义图像分割。
就架构搜索方法而言,强化学习和进化算法往往是计算密集型的——即便在低分辨率数据集 CIFAR-10 上,因此它们不太适合语义图像分割任务。受 NAS 可微分公式 [68, 49] 的启发,本研究开发出与分层架构搜索空间完全匹配的离散架构的连续松弛。分层架构搜索通过随机梯度下降实施。当搜索终止时,最好的单元架构会被贪婪解码,而最好的网络架构会通过维特比算法得到有效解码。作者在从 Cityscapes 数据集中裁剪的 321×321 图像上直接搜索架构。搜索非常高效,在一个 P100 GPU 上仅需 3 天。
作者在多个语义分割基准数据集上进行了实验,包括 Cityscapes、PASCAL VOC 2012 和 ADE20K。在未经 ImageNet 预训练的情况下,最佳 Auto-DeepLab 模型在 Cityscapes 测试集上的结果超过 FRRN-B 8.6%,超过 GridNet 10.9%。在利用 Cityscapes 粗糙标注数据的实验中,Auto-DeepLab 与一些经过 ImageNet 预训练的当前最优模型的性能相近。值得注意的是,本研究的最佳模型(未经过预训练)与 DeepLab v3+(有预训练)的表现相近,但在 MultiAdds 中前者的速度是后者的 2.23 倍。另外,Auto-DeepLab 的轻量级模型性能仅比 DeepLab v3+ 低 1.2%,而参数量需求却少了 76.7%,在 MultiAdds 中的速度是 DeepLab v3+ 的 4.65 倍。在 PASCAL VOC 2012 和 ADE29K 上,Auto-DeepLab 最优模型在使用极少数据进行预训练的情况下,性能优于很多当前最优模型。
本论文主要贡献如下:
这是首次将 NAS 从图像分类任务扩展到密集图像预测任务的尝试之一。
该研究提出了一个网络级架构搜索空间,它增强和补充了已经得到深入研究的单元级架构搜索,并对网络级和单元级架构进行更具挑战性的联合搜索。
本研究提出了一种可微的连续方式,保证高效运行两级分层架构搜索,在一个 GPU 上仅需 3 天。
在未经 ImageNet 预训练的情况下,Auto-DeepLab 模型在 Cityscapes 数据集上的性能显著优于 FRRN-B 和 GridNet,同时也和 ImageNet 预训练当前最佳模型性能相当。在 PASCAL VOC 2012 和 ADE20K 数据集上,最好的 Auto-DeepLab 模型优于多个当前最优模型。
论文:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation

论文地址:https://arxiv.org/pdf/1901.02985v1.pdf
摘要:近期,在图像分类问题上神经架构搜索(NAS)确定的神经网络架构能力超越人类设计的网络。本论文将研究用于语义图像分割的 NAS,语义图像分割是将语义标签分配给图像中每个像素的重要计算机视觉任务。现有的研究通常关注搜索可重复的单元结构,对控制空间分辨率变化的外部网络结构进行人工设计。这种做法简化了搜索空间,但对于具备大量网络级架构变体的密集图像预测而言,该方法带来的问题很多。因此,该研究提出在搜索单元结构之外还要搜索网络级架构,从而形成一个分层架构搜索空间。本研究提出一种包含多种流行网络设计的网络级搜索空间,并提出一个公式来进行基于梯度的高效架构搜索(在 Cityscapes 图像上使用 1 个 P100 GPU 仅需 3 天)。本研究展示了该方法在较难的 Cityscapes、PASCAL VOC 2012 和 ADE20K 数据集上的效果。在不经任何 ImageNet 预训练的情况下,本研究提出的专用于语义图像分割的架构获得了当前最优性能。
4 方法
这部分首先介绍了精确匹配上述分层架构搜索的离散架构的连续松弛,然后讨论了如何通过优化执行架构搜索,以及如何在搜索终止后解码离散架构。
4.2 优化
连续松弛的作用在于控制不同隐藏状态之间连接强度的标量现在也是可微计算图的一部分。因此可以使用梯度下降对其进行高效优化。作者采用了 [49] 中的一阶近似,将训练数据分割成两个单独的数据集 trainA 和 trainB。优化在以下二者之间交替进行:
1. 用 ∇_w L_trainA(w, α, β) 更新网络权重 w;
2. 用 ∇_(α,β) L_trainB(w, α, β) 更新架构 α, β。
其中损失函数 L 是在语义分割小批量上计算的交叉熵。
4.3 解码离散架构
单元架构
和 [49] 一样,本研究首先保留每个构造块的两个最强前任者(predecessor),然后使用 argmax 函数选择最可能的 operator,从而解码离散单元架构。
网络架构
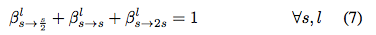
公式 7 本质上表明图 1 中每个蓝色节点处的「outgoing 概率」的总和为 1。事实上,β 可被理解为不同「时间步」(层数)中不同「状态」(空间分辨率)之间的「transition 概率」。本研究的目标是从头开始找到具备「最大概率」的的路径。在实现中,作者可以使用经典维特比算法高效解码该路径。
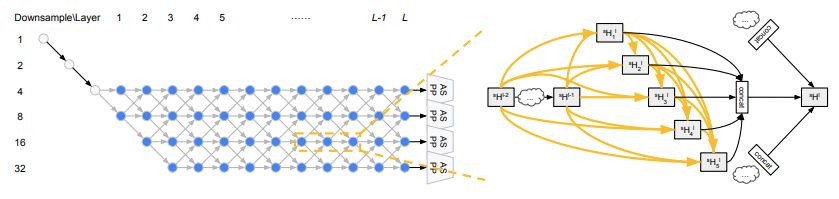
图 1:左图是 L = 12 时的网络级搜索空间。灰色节点表示固定的「stem」层,沿着蓝色节点形成的路径表示候选网络级架构。右图展示了搜索过程中,每个单元是一个密集连接的结构。
5 实验结果
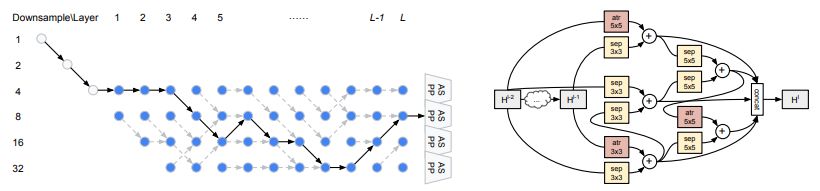
图 3:使用本研究提出的分层神经架构搜索方法找到的最优网络架构和单元架构。灰色虚线箭头表示每个节点处具备最大 β 值的连接。atr 指空洞卷积(atrous convolution),sep 指深度可分离卷积(depthwise-separable convolution)。
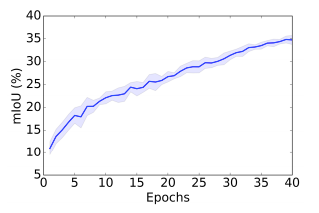
图 4:在 10 次随机试验中,40 个 epoch 中架构搜索优化的验证准确率。
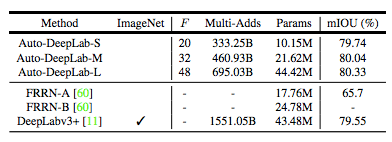
表 2:不同 Auto-DeepLab 模型变体在 Cityscapes 验证集上的结果。F:控制模型容量的 filter multiplier。所有 Auto-DeepLab 模型都是从头开始训练,且在推断过程中使用单尺度输入。
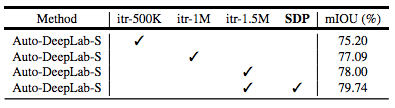
表 3:Cityscapes 验证集结果。研究采用不同的训练迭代次数(50 万、100 万与 150 万次迭代)和 SDP(Scheduled Drop Path)方法进行实验。所有模型都是从头训练的。
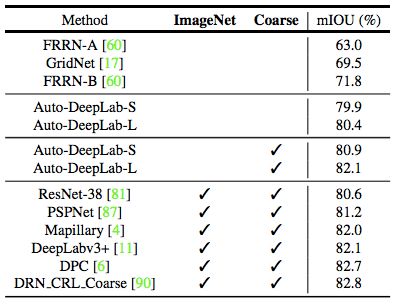
表 4:模型在推断过程中使用多尺度输入时在 Cityscapes 测试集上的结果。ImageNet:在 ImageNet 上预训练的模型。Coarse:利用粗糙注释的模型。
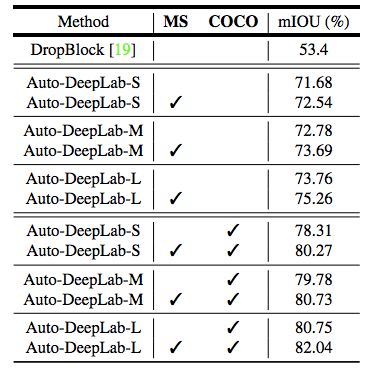
表 5:PASCAL VOC 2012 验证集结果。本研究采用多尺度推理(MS,multi-scale inference)和 COCO 预训练检查点(COCO)进行实验。在未经任何预训练的情况下,本研究提出的最佳模型(Auto-DeepLab-L)超越了 DropBlock 20.36%。所有的模型都没有使用 ImageNet 图像做预训练。
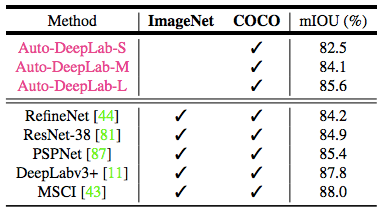
表 6:PASCAL VOC 2012 测试集结果。本研究提出的 AutoDeepLab-L 取得了可与众多在 ImageNet 和 COCO 数据集上预训练的顶级模型相媲美的结果。
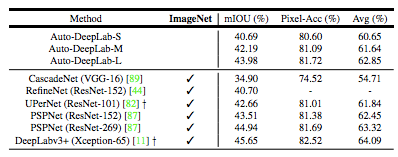
表 7:ADE20K 验证集结果。在推断过程中使用多尺度输入。† 表示结果分别是从他们最新的模型 zoo 网站获得的。ImageNet:在 ImageNet 上预训练的模型。Avg:mIOU 和像素准确率的均值。
图 5:在 Cityscapes 验证集上的可视化结果。最后一行展示了本研究提出方法的故障模式,模型将一些较难的语义类别混淆了,如人和骑车的人。
图 6:在 ADE20K 验证集上的可视化结果。最后一行展示了本研究提出方法的故障模式,模型无法分割非常细粒度的对象(如椅子腿),且将较难的语义类别混淆了(如地板和地毯)
-
人工智能
+关注
关注
1776文章
43766浏览量
230562 -
计算机视觉
+关注
关注
8文章
1592浏览量
45602
原文标题:李飞飞等人提出Auto-DeepLab:自动搜索图像语义分割架构
文章出处:【微信号:IV_Technology,微信公众号:智车科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度解析计算机视觉的图像分割技术

机器视觉与计算机视觉的关系简述
自动驾驶系统要完成哪些计算机视觉任务?
李飞飞等人提出Auto-DeepLab:自动搜索图像语义分割架构

跨图像关系型KD方法语义分割任务-CIRKD






 工商网监
工商网监
评论