 机器视觉应用程序从神经网络中获取应用所需
机器视觉应用程序从神经网络中获取应用所需
人工智能(AI)长期以来一直是科幻作家和学者的主题。将人类大脑的复杂性复制到计算机中的挑战催生了新一代的科学家,数学家和计算机算法开发人员。现在,持续的研究已经让位于人工智能的使用,更常被称为深度学习或机器学习,这些应用正日益成为我们世界的一部分。虽然基本概念已存在很长时间,但商业现实从未完全实现。近年来,数据产生的速度飙升,开发人员不得不长时间思考如何编写算法以从中提取有价值的数据和统计数据。此外,另一个关键因素是高可扩展级别的计算资源的可用性,这是云自愿产生的。例如,口袋里的智能手机可能会使用Google的Now('OK Google')或Apple的Siri语音命令应用程序,这些应用程序使用深度学习算法(称为(人工)神经网络)的强大功能来启用语音识别和学习功能。然而,除了与手机通话的乐趣和便利之外,还有许多工业,汽车和商业应用,现在正受益于深度学习神经网络的力量。
卷积神经网络
在看一些这些应用程序之前,让我们先研究一下神经网络是如何工作的,以及它需要什么样的资源。当我们一般性地谈论神经网络时,我们应该更准确地将它们描述为人工神经网络。它们作为软件算法实现,基于人类和动物的生物神经网络 - 中枢神经系统。多年来已经构思出几种不同类型的神经网络结构,其中卷积神经网络(CNN)是最广泛采用的。其中一个关键原因是它们的架构方法使它们非常适合使用基于GPU和FPGA设备的硬件加速器提供的并行化技术。 CNN流行的另一个原因是它们适合处理具有大量空间连续性的数据,其中图像处理应用程序非常适合。空间连续性是指共享相似强度和颜色属性的特定位置附近的像素。 CNN由不同的层构成,每个层都有特定的用途,并且在它们的操作中使用两个不同的阶段。第一部分是指令或训练阶段,它允许处理算法理解它具有哪些数据以及每个数据之间的关系或上下文。 CNN被创建为来自结构化和非结构化数据的学习框架,计算机创建的神经元形成连接和断开的网络。模式匹配是CNN背后的关键概念,在机器学习中广泛使用。

图1:CNN的层方法
有关CNN工作原理的更多见解可以在Cadence 1a 的论文中找到,以及在最近的IEEE社会新会议上记录的有用视频 1b 计算机前沿。当微软研究团队 1c 赢得ImageNet计算机视觉挑战时,CNN对图像处理应用程序有用的证据得到了进一步的尊重。
CNN的第二阶段是执行。由不同的层节点组成,关于可能的图像可能变得越来越抽象的命题。卷积层从图像源中提取低级特征,以便检测图像中的线或边等特征。其他层(称为汇集层)用于通过对图像的特定区域进行平均或“汇集”共同特征来减少变化。然后可以将其传递给进一步的卷积和池化层。 CNN层的数量与图像识别的准确性相关,尽管这增加了系统性能需求。如果存储器带宽可用,则层可以以并行方式操作,CNN中计算密集度最高的部分是卷积层。
开发人员面临的挑战是如何提供足够高的计算资源来运行CNN,以确定在应用程序的时间限制内所需的不同图像分类的数量。例如,工业自动化应用可能使用计算机视觉来识别部件需要在传送带上路由到哪个下一级。暂停该过程直到神经网络识别该部分将破坏流程并减缓生产。
实施CNN
加速部分CNN正在进行的“强化”学习和执行阶段将显着加快这一主要是数学任务。凭借其高内存带宽和计算能力,GPU和FPGA是这项工作的潜在候选者。具有任何Von Neumann架构所展示的缓存瓶颈的传统微处理器可以运行算法,但是将层抽象任务移交给硬件加速器。虽然GPU和FPGA都提供了重要的并行处理能力,但GPU固定架构的性质意味着FPGA具有灵活且动态可重构的架构,更适合CNN加速任务。凭借非常精细的粒度方法,基本上在硬件中实现CNN算法,与GPU的软件衍生算法方法相比,FPGA架构有助于将延迟保持在绝对最小值并且更具确定性。 FPGA的另一个优点是能够在设备结构内“硬化”功能模块,例如DSP;这种方法进一步加强了网络的确定性。在资源使用方面,FPGA非常高效,因此每个CNN层都可以在FPGA架构内构建,并且靠近它自己的内存。
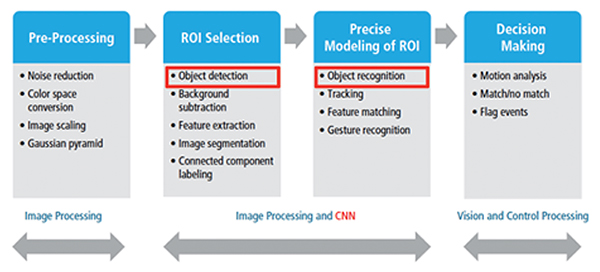
图2:图像处理概述CNN
图2突出显示了为行业图像处理应用设计的CNN的关键组件块,两个中间代表CNN核心的块。
基于FPGA的CNN加速应用程序的开发通过使用C语言的OpenCL 2a 并行编程扩展来补充。适用于卷积神经网络的FPGA器件的一个例子是英特尔可编程解决方案组(PSG)的Arria 10系列器件,正式名称为Altera。
为了帮助开发人员着手进行基于FPGA的CNN加速项目,英特尔PSG提供了CNN参考设计。这使用OpenCL内核来实现每个CNN层。使用通道和管道将数据从一个层传递到下一个层,该功能允许在OpenCL内核之间传递数据,而不必占用外部存储器带宽。卷积层使用FPGA中的DSP模块和逻辑实现。硬化块包括浮点函数,可进一步提高设备吞吐量,而不必影响可用内存带宽。
图3所示的框图突出显示了一个可以使用FPGA作为加速处理单元的示例图像处理和分类系统。
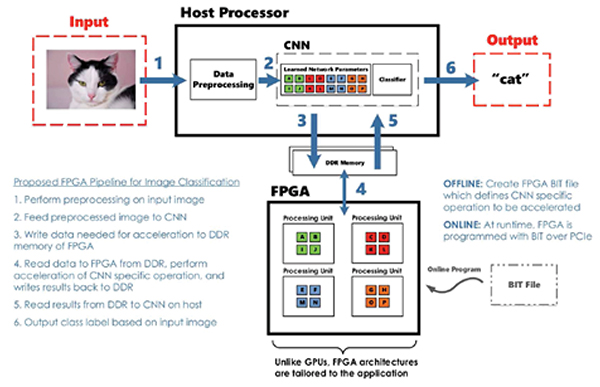
图3:使用FPGA加速的图像分类系统的框图
英特尔PSG还在其网站上提供了许多关于在工业,医疗和汽车应用中使用FPGA卷积神经网络的有用文档和视频。选择深度学习应用程序的框架是关键的第一步。为了帮助开发人员,有越来越多的工具,如OpenANN(openann.github.io),一个人工神经网络的开源库,以及信息社区网站,如deeplearning.net和embedded-vision.com。流行的深度学习设计框架包括对使用OpenCL的支持,包括基于C ++的Caffe(caffe.berkeleyvision.org)和基于Lua的Torch。 DeepCL是另一个完全支持OpenCL的框架,虽然它尚未获得前两个用户群。
结论
工业市场热衷于利用深度学习神经网络的功能可以带来许多制造和自动化控制应用。由于德国工业4.0等倡议以及更广泛的工业物联网概念,这一重点得到了进一步的发展。配备高品质的视觉相机,CPU和CPU。例如,FPGA解决方案和相关控制,卷积神经网络可用于自动化大量制造过程检查,提高产品质量,可靠性和工厂安全性。
凭借其动态可配置逻辑架构,高内存带宽和高功效,FPGA非常适合加速CNN的卷积和汇聚层。由许多社区驱动的开源框架和并行代码库(如OpenCL)提供支持,未来将FPGA用于此类应用程序是安全的。 FPGA提供了高度可扩展且灵活的解决方案,以满足许多工业领域的不同应用需求。
-
FPGA
+关注
关注
1601文章
21296浏览量
593036 -
神经网络
+关注
关注
42文章
4570浏览量
98702 -
机器视觉
+关注
关注
160文章
4039浏览量
118271
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论