 恩智浦ARM微控制器上的以太网吞吐量三种不同测量方案的介绍
恩智浦ARM微控制器上的以太网吞吐量三种不同测量方案的介绍
本文介绍了一种测量以太网吞吐量的方法,提供了良好的性能估计,并说明了影响性能的各种因素。
以太网是世界上安装最广泛的局域网(LAN)技术。它自20世纪80年代早期开始使用,并被IEEE Std 802.3所涵盖,它规定了许多速度等级。在嵌入式系统中,最常用的格式是10 Mbps和100 Mbps(通常称为10/100以太网)。
有20多个内置以太网的恩智浦ARM MCU,涵盖所有三种几代ARM(ARM7,ARM9和Cortex-M3)。恩智浦在三代产品中使用了基本相同的实现,因此设计人员可以在系统迁移到下一代ARM时重用其以太网功能,从而节省时间和资源。
本文讨论了测量LPC1700产品上以太网吞吐量的三种不同方案。详细信息在优化系统中可以实现的目标。
优越的实现
恩智浦的以太网模块(见图1)包含一个全功能的10/100以太网MAC(媒体访问控制器),它使用DMA硬件加速来提高性能。 MAC完全符合IEEE Std 802.3标准,并使用媒体独立接口(MII)或简化MII(RMII)协议以及片上MII管理(MIIM)串行总线与片外以太网PHY(物理层)连接。
恩智浦以太网模块具有以下特点:
完全以太网功能 - 该模块支持完全以太网操作,如802.3标准中所述。
增强型架构 - 恩智浦通过多种附加功能增强了架构,包括接收过滤,自动冲突后退和帧重传,以及通过时钟切换进行电源管理。
DMA硬件加速 - 该块有两个DMA管理器,每个管理器一个用于发送和接收。使用Scatter-Gather DMA进行自动帧传输和接收可以进一步卸载CPU。
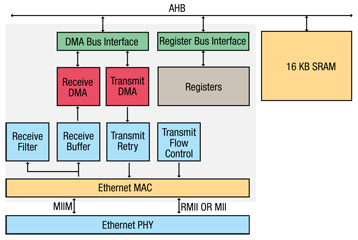
图1:LPC24xx以太网框图。恩智浦的Cortex-M3架构。
恩智浦LPC1700微控制器的以太网吞吐量
在以太网中,两个或多个站使用以太网协议通过共享信道(介质)发送和接收数据。以太网性能对于每个网络元素(信道或站点)来说意味着不同的东西。带宽,吞吐量和延迟是衡量整体性能的指标。在信道的情况下,虽然带宽是链路容量的度量,但吞吐量是可以通过信道发送可用数据的速率。在站的情况下,以太网性能可以意味着该设备以以太网信道的全比特和帧速率操作的能力。另一方面,延迟测量由几个因素(例如传播时间,处理时间,故障和重试)引起的时间延迟。
本文的重点是恩智浦LPC1700在以下操作的能力通过以太网接口(由内部EMAC模块和外部PHY芯片提供)连接到的以太网通道的完整位和帧速率。以这种方式,吞吐量将被定义为每秒可用数据(有效载荷)的度量,MCU能够向/从通信信道发送/接收。同样的概念也可以应用于支持以太网的其他恩智浦LPC微控制器。不幸的是,这些类型的测试通常需要特定的设备,如网络分析仪和/或网络流量发生器,以便获得精确的测量结果。然而,使用简单的测试设置可以获得估计的数字。实际上,我们的目标是了解可能影响以太网吞吐量的不同因素,因此用户可以专注于不同的技术以提高以太网性能。
这里只考虑发送器的吞吐量,如接收器的情况有点复杂,因为它的性能与将信息放入通道的发送器的性能有关。在这种情况下,接收器的吞吐量将受到通过信道发送数据的发送器的吞吐量的影响。一旦我们获得了发射机的吞吐量,我们就可以将此数字视为接收机能够达到的最大理想数量(在理想条件下),并获得接收机相对于此数量的吞吐量。
参考信息
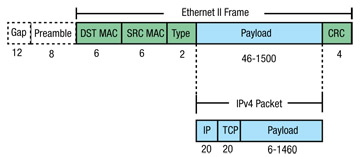
图2:以太网II帧。
考虑比特率为100 Mbps,每帧由有效载荷组成(有用数据,最小46字节,最大1,500)字节),以太网报头(14字节),CRC(4字节),前导码(8字节)和数据包间隙(12字节),然后以下是每秒和每个最大可能帧数: br》对于最小尺寸的帧:( 46字节数据) - 》 148,809帧/秒 - 》 6.84 Mb/秒
对于最大尺寸的帧:(1,500字节数据) - 》 8,127帧/秒 - 》 12.19 Mb/sec
上述费率是实际上无法达到的最大可能值。这些值是理想的,任何实际实现都会有较低的值(参见图2)。
注意:
帧/秒的计算方法是将以太网链路速度(100 Mbps)除以总数以比特为单位的帧大小(最小大小帧为84 * 8 = 672,最大大小帧为1,538 * 8 = 12,304)。
兆字节/秒是通过将帧/秒乘以数字来计算的每帧中有用数据的字节数(最小大小帧为46字节,最大大小帧为1,500字节)。
测试条件(参见图3)
MCU:LPC1768在运行时100 MHz
主板:Keil MCB1700
PHY芯片:国家DP83848(RMII接口)
工具链:KeilμVision4v4.1
从RAM运行的代码
TxDescriptorNumber = 3
以太网模式:全双工 - 100 Mbps
测试说明
为了获得最大吞吐量,有50个帧由1,514个字节组成(包括以太网报头),每个帧包含75 Kb的有效载荷(有用的数据)。 CRC(4字节)由EMAC控制器(以太网控制器)自动添加。
图3:测试设置。
为了测量此过程所需的时间,在开始发送帧之前设置GPIO引脚(在我们的例子中为P0.0),并在完成该过程后立即清除。通过这种方式,可以使用示波器测量时间,作为P0.0引脚上产生脉冲的宽度。使用以太网交叉电缆将电路板连接到PC。
PC运行嗅探器程序(在本例中为WireShark,http://www.wireshark.org/),以验证是否已发送50帧并且数据是正确的。使用有效载荷中的特定模式,因此可以容易地识别任何错误。如果50帧到达PC没有错误,则认为测试有效(参见图4)。
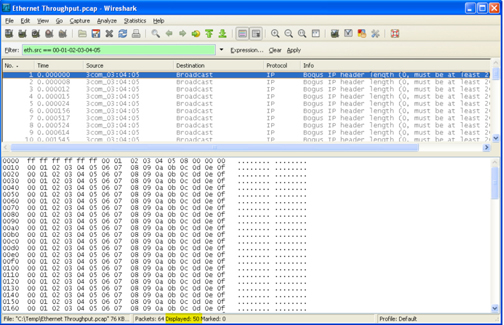
图4:验证有效负载。
测试场景
EMAC使用一系列描述符,这些描述符提供指向数据缓冲区,控制和状态信息所在的内存位置的指针。在传输的情况下,应用程序应将帧数据放入这些数据缓冲区。 EMAC使用DMA获取用户的数据并在传输之前填充帧的有效负载。因此,应用程序使用的方法将应用程序数据复制到那些数据缓冲区中将影响吞吐量的整体测量。出于这个原因,提出了三种不同的方案:
“理想”方案,根本不考虑应用程序,
“典型”方案,其中应用程序使用处理器将应用程序的数据复制到EMAC的数据缓冲区中。
“优化”方案,其中应用程序通过DMA将应用程序的数据复制到EMAC的数据缓冲区中。
场景描述
“理想”场景:在这种情况下,软件使用测试模式设置描述符的数据缓冲区,并且只有TxProduceIndex增加50次(每个数据包一次增加一次)发送)以触发帧传输。换句话说,根本不考虑该应用程序。尽管这不是典型用户的情况,但它将提供最大可能的传输吞吐量。
“典型”场景:此案例表示应用程序将数据复制到描述符中的典型情况发送帧之前的数据缓冲区。将此案例的结果与前一个案例的结果进行比较,很明显该应用程序正在影响整体性能。不应将此情况视为实际的EMAC吞吐量。但是,这里介绍的是说明非优化应用程序如何降低整体结果,给人的印象是硬件太慢。
“优化”场景:此测试使用DMA来复制应用程序的数据进入描述符的数据缓冲区。这种情况考虑了一个真实的应用,但使用了有效利用快速LPC1700硬件的优化方法。
软件
本文提供了Keil MDK项目形式的测试软件(请查看恩智浦网站上的AN11053)。可以使用配置向导并打开“config.h”文件来选择所需的方案(参见图5)。除了场景之外,还可以通过此文件修改要发送的数据包数量和帧大小。
测试结果
运行测试后,表格中列出了以下结果:
帧发送有效载荷(字节)总数据(字节)时间(毫秒)相对于最大值的吞吐量(兆字节/秒)%。可能的最大可能12.19 100.0%场景1 50 1500 75000 6.25 12.00 98.44%场景2 50 1500 75000 10.44 7.18 58.93%场景3 50 1500 75000 7.1 10.56 86.66%
表1:测试结果。
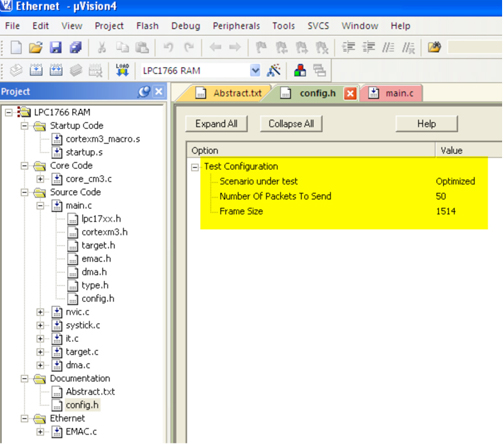
图5:选择测试场景。
结论
尽管场景1不是一个实际案例,但它为我们的硬件提供了可能的最大值作为参考,这非常接近于以太网100 Mbps的最大可能性。在场景2中,应用程序对整体性能的影响变得明显。最后,方案3显示了优化的应用程序如何极大地提高整体吞吐量。
通过运行闪存(而不是RAM)中的代码,在某些情况下通过增加代码,可以找到优化应用程序并获得更好结果的其他方法描述符的数量。总之,以太网吞吐量主要受应用程序如何将数据从应用程序缓冲区传输到描述符的数据缓冲区的影响。改进此过程将提高整体以太网性能。 LPC1700和其他LPC部件具有内置于系统硬件的优化,具有DMA支持,增强型EMAC硬件和智能存储器总线架构。
-
微控制器
+关注
关注
48文章
6806浏览量
147600 -
ARM
+关注
关注
134文章
8648浏览量
361746 -
以太网
+关注
关注
40文章
5073浏览量
166204
发布评论请先 登录
相关推荐
如何提高CYBT-243053-02吞吐量?
如何使用iperf测量AURIX以太网服务器的速度?
全志R128 BLE最高吞吐量测试正确配置测试
如何使用AT32F437以太网通信接口实现在应用中编程(IAP)的解决方案
全志R128 BLE最高吞吐量测试正确配置测试





Arm TrustZone STM32微控制器的安全启动和安全固件更新解决方案







 工商网监
工商网监
评论