 一种被称为Barrier-enabled IO stack的方案
一种被称为Barrier-enabled IO stack的方案
本期和大家聊的是刚刚在2月份拿到FAST 2018最佳论文奖的一篇文章。它讨论了实现一种支持保序IO操作的设备会带来哪些好处,目前的Linux内核里处理FLUSH、FUA的方式可以参见https://lwn.net/Articles/400541/,本文大部分内容来自于 blog.acolyer.org ,图表来自于论文原文。
作者
朱延海,Linux系统工程师,来自阿里云系统组。
阿里云系统团队,是由原淘宝内核组扩建而成,2013年淘宝内核组响应阿里巴巴集团的号召,整建制转入阿里云,开始为云计算底层系统构建完善的系统支持。 阿里云系统团队是由一群具有高度使命感和自我追求的内核开发人员组成,团队中的大多数人,都是活跃的社区内核开发人员。目前的工作领域主要涉及(但不限于) Linux内核的内存管理、文件系统、网络和内核维护构建,以及和内核相关联的用户态库和工具。如果你对我们的工作很感兴趣,欢迎加入我们,请将简历发送至 tao.ma at linux.alibaba.com或者 boyu.mt at alibaba-inc.com。
概述
现代高速Flash设备的性能诀窍在于充分提高请求处理的并行度(scale-out),而并非无限地降低其延迟(scale-up)—例如,使用多通道控制器(multi-channel controllers)、更大的缓存以及更深的命令队列,这些都是用来提高并行度的有效办法。同时,写一个flash cell所需要的时间一直没有什么变化,近来甚至有变差的趋势。在大部分情况下,用户对此并不在意,也感觉不到—除非你的应用希望它发出的一系列请求是保序的(guarantee ordering),这也就是本文所要重点讨论的问题:
“在目前的设备上,为请求保序是通过一种代价很高的办法来实现的:把排在请求X前边的所有请求都发出去,然后等待它们全部完成、持久化并返回,然后才发射请求X,这时我们就可以说X前边的请求和X之间建立了明确的先后顺序关系。我们把这种机制叫做Transfer-and-Flush。”
显而易见,当你使用Transfer-and-Flush机制时,设备的并行度会大大降低,因此带来最终性能的降低,设备越是依赖高并行度来攫取性能,这种做法就越是令人无法接受。例如,在一个智能手机的单通道SSD上,保序写请求的IOPS是无序写请求的20%,对于32通道SSD,这一比例降低至1%。在目前的Linux内核中,文件系统若真的想执行一系列保序请求,使用的机制也是Transfer-and-Flush。然而,通过Transfer-and-Flush来保序显然杀伤力过大了:首先,也许文件系统原本只想让两个单个请求之间是有序的,但却不得不使得由flush分隔的两组操作集合之间变得有序,而这每一个集合里都可能包含了大量不需要保序的请求;其次,这么做不仅实现了保序,同时还提供了同步的持久化保证,这并不是保序想要的—当一个上层应用发出两个保序的请求A1和A2时,它对于A1和A2具体何时被持久化并没有什么期待,可以是异步的,它唯一的要求是一但持久化动作开始,A1的持久化必须发生在A2之前。
本文的作者提出了一种被称为Barrier-enabled IO stack的方案,这一方案不依赖Transfer-and-Flush,文件系统也就无需停下来等待前边的请求成功返回。这一方案得到的性能提升相当惊人:
“SQlite服务器场景性能提升270%,手机场景性能提升75%;实现了Barrier-enabled IO stack的BarrierFS在MySQL场景性能指标是EXT4的43倍,在SQLite场景性能指标是EXT4的73倍”
下边我们来介绍下作者的方案
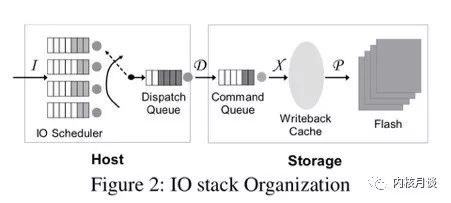
我们知道,现代IO stack天生就是乱序的。试想文件系统发射出来的一簇请求在下边的路径里会经历些什么:
IO调度器会对请求重排列,还有可能合并请求
设备上的控制器收到请求后放到自己内部的命令队列里,这时它也可以随意改变请求顺序。设备内部的错误、超时、重传等等也都有可能对请求实际执行的顺序产生影响
现代设备内部通常也像文件系统一样,有数据块和元数据块,有自己的journal。请求抵达存储设备内部之后,最终对用户可见、对用户有意义的持久化“顺序”不光是由数据块的持久化顺序决定,同时也受那些元数据的持久化顺序影响,而这两者并不一定是相同的。
因此,多数操作系统的IO stack都包含了一个从硬盘时代流传下来的设计假设:上位机不能控制持久化顺序
“现代IO stack设计中的一个基本假设就是上位机不能真正地控制到数据的持久化顺序”
因此,一但上位机确实需要控制持久化顺序时,就只能使用昂贵的Transfer-and-Flush机制了:如果请求a需要排在请求b之前完成,那么把请求a发到存储设备之后,上位机就首先需要等设备报告a彻底完成,然后发一个flush命令并等待flush完成(以防设备上的cache造成乱序),然后才发请求b。
以EXT4的默认工作模式Ordered模式为例,当它提交一个journal transaction时,它需要执行两次写:第一次写journal descriptor和log blocks(JD),第二次写commit block(JC)。JD必须先于JC完成持久化。在transaction的层面上看,各个transaction之间也必须是有序的,排在前边的transaction一定要比排在后边的transaction先完成持久化,否则文件系统执行故障恢复时就有崩溃的可能。为了把保序语义引入IO stack,作者显然需要自底向上把这个语义贯穿到整个IO stack中去。下边具体介绍一下作者的工作。
带barrier的保序块设备
“给设备加入barrier指令支持后,上位机就不再需要通过显式地刷cache来保证请求顺序了。当设备收到barrier指令时,它会确保排在barrier前的所有指令—可能是写也可能是读—都执行完毕、完成数据传输后,才开始执行排在barrier后边的指令。”
论文的作者把他提出的这种barrier实现成了SCSI命令的一个附加属性,而不是一条独立的SCSI命令。设备具体实现barrier支持的方法有很多,对于本身已经带有一个大电容,写操作返回时就可以保证持久化的那些设备,可以认为它们天生对于收到的写请求就是保序的,因此只要在设备上边的各个层次能够保证提交顺序,整条链路就直接可以做出保序的承诺,因此对于这些设备没什么需要修改的。对于其他设备,在设备内部实现保序其实和之前在整个IO stack上实现保序的逻辑基本是一样的,要么确保writeback cache按顺序回写、要么在回写时引入事务机制、要么实现按顺序recovery。论文对于具体如何实现这种带barrier支持的存储设备一笔带过,并表示这不是重点,作者认为论文的重点在于说明一但拥有此种设备会带来多大好处,至于如何实现这种设备那是纯粹的engineering efforts,不再过多考虑。
总之,一但拥有这种设备,就可以实现请求的保序发送:
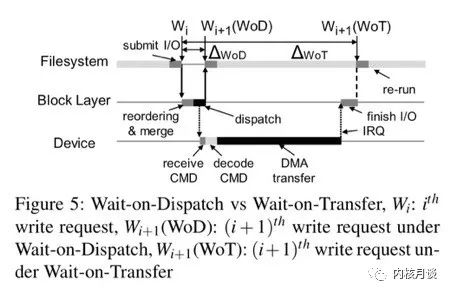
“保序发送是本文的重要创新之处,上层的文件系统对于需要保序的请求可以带上barrier标志,只要注意在发送时不把它们重排序就行,不再需要等待flush。由下边的存储设备来保证带barrier标志请求的持久化顺序与它们的发送顺序相同。我们把这种机制叫做wait-on-dispatch”
显然,wait-on-dispatch比wait-on-transfer的成本要小很多,如下图所示:
scsi layer
我们沿着从下往上的方向继续向上层走,当设备实现了barrier支持之后,紧接着需要修改的是scsi层。在这里作者利用了scsi层已有的command priority level机制,按照scsi规范,命令可以分成三种:head of the queue(收到命令时要把它插入到队列头上)、ordered(收到命令时要把它插入到队列尾部)、simple(命令可以插入到队列中任意位置,但不能放在head of the queue命令或ordered命令的前边)。因此,只需要把barrier命令打上ordered属性发送,把其他写请求打上simple属性发送,就天然地可以在scsi层上保证barrier语义了。
“在目前的块设备层实现中,ordered命令很少使用,这是因为当整个IO stack尚且不能做到保序发送时,单独在scsi层控制命令的发送顺序没有什么意义。然而,当我们在全路径上引入barrier语义后,scsi层的ordered命令就开始扮演重要的角色了”
epoch-based IO scheduler
在解决了scsi层的问题后,作者沿着IO路径继续往上走,对IO调度器加以修改,引入了所谓的epoch-based scheduling:
需要保序的写操作,带有REQ_ORDERED标志
一对REQ_BARRIER之间的所有RED_ORDERED写构成一个epoch
两个epoch之间整体上的提交是保序的,即第一个epoch的所有写请求提交结束后,才提交第二个epoch里的写请求
一个epoch内部的REQ_ORDERED写之间可以自由重排序
不带REQ_ORDERED的写请求可以任意自由跨epoch重排序
这样作者就进一步解决了barrier杀伤力过大的问题—只有明确表示需要保序的写请求,其提交顺序才受barrier约束。
Barrier-enabled filesystem
IO调度器理顺之后,作者继续向上走,开始修改文件系统,提出了barrier-enabled filesystem(BFS)的概念,BFS引入了两个新的原语:fbarrier()和fdatabarrier(),它们分别是fsync()和fdatasyn()在保序这个意义上的对应产物,即是说,当你调用它们时,它们会确保排在调用点之前的所有写操作(或者所有数据写操作)一定比排在它们之后的所有写操作先完成持久化,然而对于具体何时会完成持久化不做保证。另外,作者也修改了ext4的journal以使它利用上新的barrier机制:
“利用底层设备提供的保序语义,我们就可以把一次journal提交过程中的控制平面活动(写请求的提交)和数据平面活动(数据及journal的持久化)分开处理,我们建立两个线程,一个负责保序提交请求,另一个负责等待它们完成。我们把这种机制叫做Dual Mode Journaling”
效果评估
原文中的第6小节也包括了块设备层和文件系统层的性能测试,不过我们这里直接关注最终的应用性能提升。
对于服务器负载,作者跑了varmail(varmail发的fsync非常多),还有MySQL上的OLTP-insert测试。作者把这里的对比测试细分成了两种情况,第一种是所谓的durability guarantee测试,在这个测试里应用代码完全不改,用BarrierFS和标准的EXT4做对比,这是为了说明利用了barrier语义后fsync()本身的性能提升;第二种是所谓的ordering guarantee测试,在这个测试里作者跑了BarrierFS、OptFS和EXT4三种文件系统(前两种支持barrier语义),并在前两种文件系统上把应用的fsync()换成fdatabarrier()和osync()(osync是OptFS里的barrier操作),对于EXT4则加上nobarrier参数。这一测试是为了说明wait-on-dispatch比wait-on-transfer的优越之处,注意这里作者实际上做了一个不切实际的假定,须知有时应用调用fsync()时确实是想保证其持久性的,并非每一处fsync()都可以换成fdatabarrier(),具体要如何修改应用必须结合应用的具体上下文。第二个测试的结果只能说明结合应用具体场景,去掉overkill的持久化约束后性能提升的上限会是多少。
在durability guarantee测试中,BarrierFS为varmail带来了10%-60%的性能提升,为MySQL带来了12%的性能提升;在ordering guarantee测试中,BarrierFS带来了36倍性能提升,为MySQL带来了43倍性能提升。
对于移动设备负载,作者测试了Sqlite,durability guarantee带来了75%性能提升,ordering guarantee带来了2.8倍性能提升。
结语
“为高并发Flash设备设计一个支持barrier语义的IO stack会带来极大的性能优势 …… 这种barrier语义已经日渐成为一种必须品,我们建议从移动端到服务端的各种Flash设备厂商考虑支持barrier语义”
-
控制器
+关注
关注
112文章
15206浏览量
171121 -
存储设备
+关注
关注
0文章
136浏览量
18483 -
阿里云
+关注
关注
3文章
883浏览量
42607
原文标题:Barrier-enabled IO stack for Flash storage
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论