 如何针对涂鸦识别问题构建基于RNN的识别器
如何针对涂鸦识别问题构建基于RNN的识别器
Quick, Draw!是一款游戏;在这个游戏中,玩家要接受一项挑战:绘制几个图形,看看计算机能否识别玩家绘制的是什么。
Quick, Draw!的识别操作 由一个分类器执行,它接收用户输入(用 (x, y) 中的点笔画序列表示),然后识别用户尝试涂鸦的图形所属的类别。
在本教程中,我们将展示如何针对此问题构建基于 RNN 的识别器。该模型将结合使用卷积层、LSTM 层和 softmax 输出层对涂鸦进行分类:
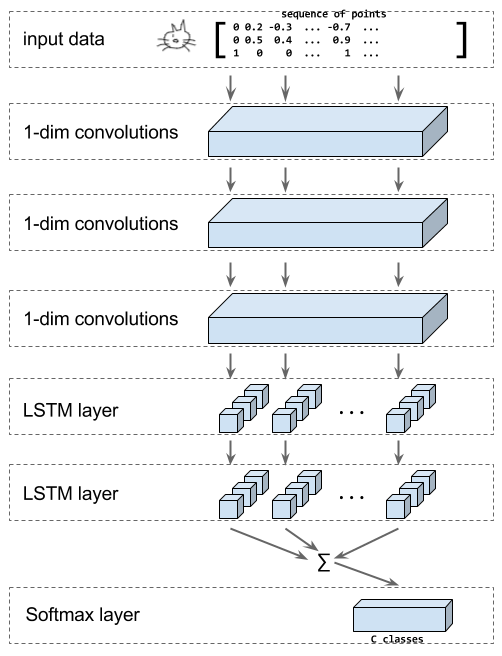
上图显示了我们将在本教程中构建的模型的结构。输入为一个涂鸦,用 (x, y, n) 中的点笔画序列表示,其中 n 表示点是否为新笔画的第一个点。
然后,模型将应用一系列一维卷积,接下来,会应用 LSTM 层,并将所有 LSTM 步的输出之和馈送到 softmax 层,以便根据我们已知的涂鸦类别来决定涂鸦的分类。
本教程使用的数据来自真实的Quick, Draw!游戏,这些数据是公开提供的。此数据集包含 5000 万幅涂鸦,涵盖 345 个类别。
运行教程代码
要尝试本教程的代码,请执行以下操作:
安装 TensorFlow(如果尚未安装的话)
下载教程代码
下载数据(TFRecord格式),然后解压缩。如需详细了解如何获取原始 Quick, Draw!数据以及如何将数据转换为TFRecord文件,请参阅下文
使用以下命令执行教程代码,以训练本教程中所述的基于 RNN 的模型。请务必调整路径,使其指向第 3 步中下载的解压缩数据
python train_model.py \ --training_data=rnn_tutorial_data/training.tfrecord-?????-of-????? \ --eval_data=rnn_tutorial_data/eval.tfrecord-?????-of-????? \ --classes_file=rnn_tutorial_data/training.tfrecord.classes
教程详情
下载数据
我们将本教程中要使用的数据放在了包含TFExamples的TFRecord文件中。您可以从以下位置下载这些数据:http://download.tensorflow.org/data/quickdraw_tutorial_dataset_v1.tar.gz(大约 1GB)。
或者,您也可以从 Google Cloud 下载ndjson格式的原始数据,并将这些数据转换为包含TFExamples的TFRecord文件,如下一部分中所述。
可选:下载完整的 QuickDraw 数据
完整的Quick, Draw!数据集可在 Google Cloud Storage 上找到,此数据集是按类别划分的ndjson文件。您可以在 Cloud Console 中浏览文件列表。
要下载数据,我们建议使用gsutil下载整个数据集。请注意,原始 .ndjson 文件需要下载约 22GB 的数据。
然后,使用以下命令检查 gsutil 安装是否成功以及您是否可以访问数据存储分区:
gsutil ls -r "gs://quickdraw_dataset/full/simplified/*"
系统会输出一长串文件,如下所示:
gs://quickdraw_dataset/full/simplified/The Eiffel Tower.ndjsongs://quickdraw_dataset/full/simplified/The Great Wall of China.ndjsongs://quickdraw_dataset/full/simplified/The Mona Lisa.ndjsongs://quickdraw_dataset/full/simplified/aircraft carrier.ndjson...
之后,创建一个文件夹并在其中下载数据集。
mkdir rnn_tutorial_datacd rnn_tutorial_datagsutil -m cp "gs://quickdraw_dataset/full/simplified/*" .
下载过程需要花费一段时间,且下载的数据量略超 23GB。
可选:转换数据
要将ndjson文件转换为TFRecord文件(包含tf.train.Example样本),请运行以下命令。
python create_dataset.py --ndjson_path rnn_tutorial_data \ --output_path rnn_tutorial_data
此命令会将数据存储在TFRecord文件的 10 个分片中,每个类别有 10000 项用于训练数据,有 1000 项用于评估数据。
下文详细说明了该转换过程。
原始 QuickDraw 数据的格式为ndjson文件,其中每行包含一个如下所示的 JSON 对象:
{"word":"cat","countrycode":"VE","timestamp":"2017-03-02 23:25:10.07453 UTC","recognized":true,"key_id":"5201136883597312","drawing":[ [ [130,113,99,109,76,64,55,48,48,51,59,86,133,154,170,203,214,217,215,208,186,176,162,157,132], [72,40,27,79,82,88,100,120,134,152,165,184,189,186,179,152,131,114,100,89,76,0,31,65,70] ],[ [76,28,7], [136,128,128] ],[ [76,23,0], [160,164,175] ],[ [87,52,37], [175,191,204] ],[ [174,220,246,251], [134,132,136,139] ],[ [175,255], [147,168] ],[ [171,208,215], [164,198,210] ],[ [130,110,108,111,130,139,139,119], [129,134,137,144,148,144,136,130] ],[ [107,106], [96,113] ]]}
在构建我们的分类器时,我们只关注 “word” 和 “drawing” 字段。在解析 ndjson 文件时,我们使用一个函数逐行处理它们,该函数可将drawing字段中的笔画转换为大小为[number of points, 3](包含连续点的差异)的张量。此函数还会以字符串形式返回类别名称。
def parse_line(ndjson_line): """Parse an ndjson line and return ink (as np array) and classname.""" sample = json.loads(ndjson_line) class_name = sample["word"] inkarray = sample["drawing"] stroke_lengths = [len(stroke[0]) for stroke in inkarray] total_points = sum(stroke_lengths) np_ink = np.zeros((total_points, 3), dtype=np.float32) current_t = 0 for stroke in inkarray: for i in [0, 1]: np_ink[current_t:(current_t + len(stroke[0])), i] = stroke[i] current_t += len(stroke[0]) np_ink[current_t - 1, 2] = 1 # stroke_end # Preprocessing. # 1. Size normalization. lower = np.min(np_ink[:, 0:2], axis=0) upper = np.max(np_ink[:, 0:2], axis=0) scale = upper - lower scale[scale == 0] = 1 np_ink[:, 0:2] = (np_ink[:, 0:2] - lower) / scale # 2. Compute deltas. np_ink = np_ink[1:, 0:2] - np_ink[0:-1, 0:2] return np_ink, class_name
由于我们希望数据在写入时进行随机处理,因此我们以随机顺序从每个类别文件中读取数据并写入随机分片。
对于训练数据,我们读取每个类别的前 10000 项;对于评估数据,我们读取每个类别接下来的 1000 项。
然后,将这些数据变形为[num_training_samples, max_length, 3]形状的张量。接下来,我们用屏幕坐标确定原始涂鸦的边界框并标准化涂鸦的尺寸,使涂鸦具有单位高度。
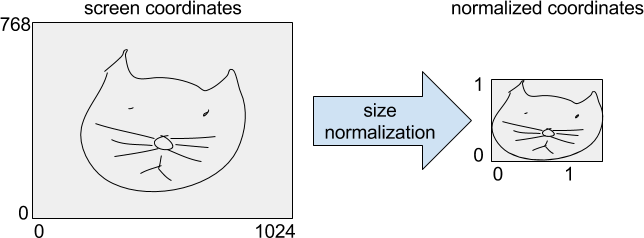
最后,我们计算连续点之间的差异,并将它们存储为VarLenFeature(位于tensorflow.Example中的ink键下)。另外,我们将class_index存储为单一条目FixedLengthFeature,将ink的shape存储为长度为 2 的FixedLengthFeature。
定义模型
要定义模型,我们需要创建一个新的Estimator。如需详细了解 Estimator,建议您阅读此教程。
要构建模型,我们需要执行以下操作:
将输入调整回原始形状,其中小批次通过填充达到其内容的最大长度。除了 ink 数据之外,我们还拥有每个样本的长度和目标类别。这可通过函数_get_input_tensors实现
将输入传递给_add_conv_layers中的一系列卷积层
将卷积的输出传递到_add_rnn_layers中的一系列双向 LSTM 层。最后,将每个时间步的输出相加,针对输入生成一个固定长度的紧凑嵌入
在_add_fc_layers中使用 softmax 层对此嵌入进行分类
代码如下所示:
inks, lengths, targets = _get_input_tensors(features, targets)convolved = _add_conv_layers(inks)final_state = _add_rnn_layers(convolved, lengths)logits =_add_fc_layers(final_state)
_get_input_tensors
要获得输入特征,我们先从特征字典获得形状,然后创建大小为[batch_size](包含输入序列的长度)的一维张量。ink 作为稀疏张量存储在特征字典中,我们将其转换为密集张量,然后变形为[batch_size, ?, 3]。最后,如果传入目标,我们需要确保它们存储为大小为[batch_size]的一维张量。
代码如下所示:
shapes = features["shape"]lengths = tf.squeeze( tf.slice(shapes, begin=[0, 0], size=[params["batch_size"], 1]))inks = tf.reshape( tf.sparse_tensor_to_dense(features["ink"]), [params["batch_size"], -1, 3])if targets is not None: targets = tf.squeeze(targets)
_add_conv_layers
您可以通过params字典中的参数num_conv和conv_len配置所需的卷积层数量和过滤器长度。
输入是一个每个点维数都是 3 的序列。我们将使用一维卷积,将 3 个输入特征视为通道。这意味着输入为[batch_size, length, 3]张量,而输出为[batch_size, length, number_of_filters]张量。
convolved = inksfor i in range(len(params.num_conv)): convolved_input = convolved if params.batch_norm: convolved_input = tf.layers.batch_normalization( convolved_input, training=(mode == tf.estimator.ModeKeys.TRAIN)) # Add dropout layer if enabled and not first convolution layer. if i > 0 and params.dropout: convolved_input = tf.layers.dropout( convolved_input, rate=params.dropout, training=(mode == tf.estimator.ModeKeys.TRAIN)) convolved = tf.layers.conv1d( convolved_input, filters=params.num_conv[i], kernel_size=params.conv_len[i], activation=None, strides=1, padding="same", name="conv1d_%d" % i)return convolved, lengths
_add_rnn_layers
我们将卷积的输出传递给双向 LSTM 层,对此我们使用 contrib 的辅助函数。
outputs, _, _ = contrib_rnn.stack_bidirectional_dynamic_rnn( cells_fw=[cell(params.num_nodes) for _ in range(params.num_layers)], cells_bw=[cell(params.num_nodes) for _ in range(params.num_layers)], inputs=convolved, sequence_length=lengths, dtype=tf.float32, scope="rnn_classification")
请参阅代码以了解详情以及如何使用CUDA加速实现。
要创建一个固定长度的紧凑嵌入,我们需要将 LSTM 的输出相加。我们首先将其中的序列不含数据的批次区域设为 0。
mask = tf.tile( tf.expand_dims(tf.sequence_mask(lengths, tf.shape(outputs)[1]), 2), [1, 1, tf.shape(outputs)[2]])zero_outside = tf.where(mask, outputs, tf.zeros_like(outputs))outputs = tf.reduce_sum(zero_outside, axis=1)
_add_fc_layers
将输入的嵌入传递至全连接层,之后将此层用作 softmax 层。
tf.layers.dense(final_state, params.num_classes)
损失、预测和优化器
最后,我们需要添加一个损失函数、一个训练操作和预测来创建ModelFn:
cross_entropy = tf.reduce_mean( tf.nn.sparse_softmax_cross_entropy_with_logits( labels=targets, logits=logits))# Add the optimizer.train_op = tf.contrib.layers.optimize_loss( loss=cross_entropy, global_step=tf.train.get_global_step(), learning_rate=params.learning_rate, optimizer="Adam", # some gradient clipping stabilizes training in the beginning. clip_gradients=params.gradient_clipping_norm, summaries=["learning_rate", "loss", "gradients", "gradient_norm"])predictions = tf.argmax(logits, axis=1)return model_fn_lib.ModelFnOps( mode=mode, predictions={"logits": logits, "predictions": predictions}, loss=cross_entropy, train_op=train_op, eval_metric_ops={"accuracy": tf.metrics.accuracy(targets, predictions)})
训练和评估模型
要训练和评估模型,我们可以借助EstimatorAPI 的功能,并使用ExperimentAPI 轻松运行训练和评估操作:
estimator = tf.estimator.Estimator( model_fn=model_fn, model_dir=output_dir, config=config, params=model_params) # Train the model. tf.contrib.learn.Experiment( estimator=estimator, train_input_fn=get_input_fn( mode=tf.contrib.learn.ModeKeys.TRAIN, tfrecord_pattern=FLAGS.training_data, batch_size=FLAGS.batch_size), train_steps=FLAGS.steps, eval_input_fn=get_input_fn( mode=tf.contrib.learn.ModeKeys.EVAL, tfrecord_pattern=FLAGS.eval_data, batch_size=FLAGS.batch_size), min_eval_frequency=1000)
请注意,本教程只是用一个相对较小的数据集进行简单演示,目的是让您熟悉递归神经网络和 Estimator 的 API。如果在大型数据集上尝试,这些模型可能会更强大。
当模型完成 100 万个训练步后,分数最高的候选项的准确率预计会达到 70% 左右。请注意,这种程度的准确率足以构建 Quick, Draw! 游戏,由于该游戏的动态特性,用户可以在系统准备好识别之前调整涂鸦。此外,如果目标类别显示的分数高于固定阈值,该游戏不会仅使用分数最高的候选项,而且会将某个涂鸦视为正确的涂鸦。
-
神经网络
+关注
关注
42文章
4570浏览量
98707 -
识别器
+关注
关注
0文章
19浏览量
7545
原文标题:Quick, Draw! 涂鸦分类递归神经网络
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
语音识别问题
请教 LD3320 语音识别问题
DHCP识别问题如何解决
JFM7K325T的JTAG识别连接问题
如何解决网络无法识别问题
离线语音识别和控制的工作原理及应用
USB硬盘的系统识别问题
贴片电容坏了怎么识别
USB智能识别IC可解决传统USB口的识别问题
HID_CDC复合设备在WIN10的识别问题






 工商网监
工商网监
评论