 Airbnb开发和部署的房源嵌入技术
Airbnb开发和部署的房源嵌入技术
【导读】本文最早于 2018 年 5 月 13 日发表,主要介绍了机器学习的嵌入技术在 Airbnb 爱彼迎房源搜索排序和实时个性化推荐中的实践。Airbnb 爱彼迎的两位机器学习科学家凭借这项技术的实践获得了2018 年 KDD ADS track 的最佳论文,本文即是对这篇论文的精华概括。
Airbnb 平台包含数百万种不同的房源,用户可以通过浏览搜索结果页面来寻找想要的房源,我们通过复杂的机器学习模型使用上百种信号对搜索结果中的房源进行排序。 当用户查看一个房源时,他们有两种方式继续搜索:返回搜索结果页,或者查看房源详情页的「相似房源」(会推荐和当前房源相似的房源)。我们 99% 的房源预订来自于搜索排序和相似房源推荐。
在这篇博文中,我们将会介绍 Airbnb 开发和部署的房源嵌入(Listing Embedding)技术,以及如何用此来改进相似房源推荐和搜索排序中的实时个性化。 这种嵌入是从搜索会话(Session)中学到的 Airbnb 房源的一种矢量表示,并可用此来衡量房源之间的相似性。 房源嵌入能有效地编码很多房源特征,比如位置、价格、类型、建筑风格和房屋风格等等,并且只需要用 32 个浮点数。我们相信通过嵌入的方法来做个性化和推荐对所有的双边市场平台都非常有效。
嵌入的背景
将词语表示为高维稀疏向量 (high-dimensional, sparse vectors) 是用于语言建模的经典方法。不过,在许多自然语言处理 (NLP) 应用中,这一方法已经被基于神经网络的词嵌入并将词语用低维度 (low-dimentional) 来表示的新模型取代。新模型假设经常一起出现的词也具有更多的统计依赖性,会直接考虑词序及其共现 (co-occurrence) 来训练网络。 随着更容易扩展的单词表达连续词袋模型 (bag-of-words) 和 Skip-gram 模型的发展,在经过大文本数据训练之后,嵌入模型已被证明可以在多种语言处理任务中展现最佳性能。
最近,嵌入的概念已经从词的表示扩展到 NLP 领域之外的其他应用程序。来自网络搜索、电子商务和双边市场领域的研究人员已经意识到,就像可以通过将句子中的一系列单词视为上下文来训练单词嵌入一样,我们也可以通过处理用户的行为序列来训练嵌入用户操作,比如学习用户点击和购买的商品或浏览和点击的广告。 这样的嵌入已经被用于 web 上的各种推荐系统中。
房源嵌入
我们的数据集由 N 个用户的点击会话 (Session) 组成,其中每个会话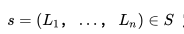 定义为一个由用户点击的 n 个房源 id 组成的的不间断序列;同时,只要用户连续两次点击之间的时间间隔超过30分钟,我们就会认为是一个新的会话。 基于该数据集,我们的目标是学习一个 32 维的实值表示方式
定义为一个由用户点击的 n 个房源 id 组成的的不间断序列;同时,只要用户连续两次点击之间的时间间隔超过30分钟,我们就会认为是一个新的会话。 基于该数据集,我们的目标是学习一个 32 维的实值表示方式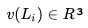 来包含平台上所有的房源,并使相似房源在嵌入空间中处于临近的位置。
来包含平台上所有的房源,并使相似房源在嵌入空间中处于临近的位置。
列表嵌入的维度被设置为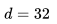 ,这样的设置可以平衡离线性能(在下一节中讨论)和在线搜索服务器内存中存储向量所需的空间,能够更好地进行实时相似度的计算。
,这样的设置可以平衡离线性能(在下一节中讨论)和在线搜索服务器内存中存储向量所需的空间,能够更好地进行实时相似度的计算。
目前有几种不同的嵌入训练方法,在这里,我们将专注于一种称为负抽样 (Negative Sampling) 的技术。 首先,它将嵌入初始化为随机向量,然后通过滑动窗口的方式读取所有的搜索会话,并通过随机梯度下降(stochastic gradient descent)来更新它们。 在每一步中,我们都会将中央房源的向量更新并将其推向正向相关房源的向量(用户在点击中心房源前后点击的其他房源,滑动窗口长度为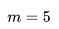 ),并通过随机抽样房源的方式将它从负向相关房源推开(因为这些房源很大几率与中央房源没有关系)。
),并通过随机抽样房源的方式将它从负向相关房源推开(因为这些房源很大几率与中央房源没有关系)。
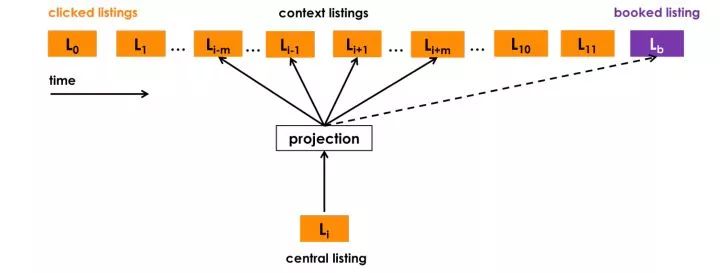
为简洁起见,我们将跳过具体训练过程的细节,并着重解释为了更好地适用我们的场景而做的一些修改:
使用最终预订的房源作为全局上下文 (Global Context):我们使用以用户预订了房源(上图中紫色标记)为告终的用户会话来做这个优化,在这个优化的每个步骤中我们不仅预测相邻的点击房源,还会预测最终预订的房源。 当窗口滑动时,一些房源会进入和离开窗口,而预订的房源始终作为全局上下文(图中虚线)保留在其中,并用于更新中央房源向量。
适配聚集搜索的情况:在线旅行预订网站的用户通常仅在他们的旅行目的地内进行搜索。 因此,对于给定的中心房源,正相关的房源主要包括来自相同目的地的房源,而负相关房源主要包括来自不同目的地的房源,因为它们是从整个房源列表中随机抽样的。 我们发现,这种不平衡会导致在一个目的地内相似性不是最优的。 为了解决这个问题,我们添加了一组从中央房源的目的地中抽样选择的随机负例样本集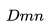
考虑到上述所有因素,最终的优化目标可以表述为
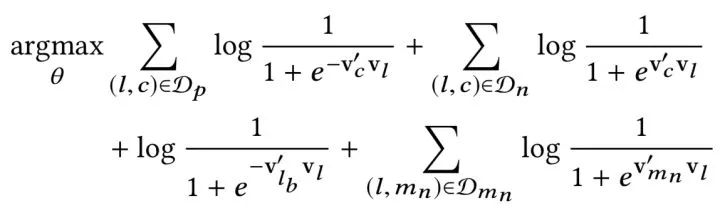
在这里
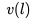
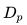
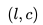
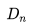
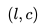
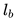
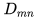
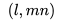
使用上面所描述的优化程序,我们通过使用超过 8 亿次的搜索点击会话,训练了 Airbnb 上 450 万个有效列表的房源嵌入,从而获得了高质量的房源展示。
冷启动嵌入:每天在 Airbnb 上都有新的房源提供。这些房源在新建时还不在我们的训练数据集中,所以没有嵌入信息。 要为新房源创建嵌入,我们会找到 3 个地理位置最接近、房源类别和价格区间相同的已存在的房源,并计算这些房源嵌入的向量平均值来作为新房源的嵌入值。
嵌入学习到的是什么?
我们用多种方式来评估嵌入捕获到的房源的特征。首先,为了评估地理位置相似性是否被包含,我们对用于学习的嵌入进行了 k 均值聚类 (k-means clustering)。下面的图显示了美国加州产生的 100 个聚类,确认了来自近似位置的房源聚集在一起。 接下来,我们评估了不同类型(整套房源,独立房间,共享房间)和价格范围的房源之间的平均余弦相似性 (cosine similarity) ,并确认相同类型和价格范围的房源之间的余弦相似性远高于不同类型和不同价格的房源之间的相似性。 因此我们可以得出结论,这两个房源特征也被很好的包括在训练好的嵌入中了。
虽然有一些房源特征我们可以从房源元数据中提取(例如价格),所以不需要被学习,但是其他类型的房源特征(例如建筑风格,样式和感觉)很难提取为房源特征的形式。 为了评估这些特性并能够在嵌入空间中进行快速简便的探索,我们内部开发了一个相似性探索工具 (Similarity Exploration Tool),并提供了一个视频进行演示。
视频链接:https://www.youtube.com/watch?v=1kJSAG91TrI&feature=youtu.be
该视频提供了许多嵌入示例,能够找到相同独特建筑风格的相似房源,包括船屋、树屋、城堡等。
线下评估
在对使用了嵌入的推荐系统进行线上搜索测试之前,我们进行了多次离线测试。同时我们还使用这些测试比较了多种不同参数训练出来的不同嵌入,以快速做优化,决定嵌入维度、算法修改的不同思路、训练数据的构造、超参数的选择等。
评估嵌入的一种方法是测试它们通过用户最近的点击来推荐的房源,有多大可能最终会产生预订。
更具体地说,假设我们获得了最近点击的房源和需要排序的房源候选列表,其中包括用户最终预订的房源;通过计算点击房源和候选房源在嵌入空间的余弦相似度,我们可以对候选房源进行排序,并观察最终被预订的房源在排序中的位置。
我们在下图中显示了一个此类评估的结果,搜索中的房源根据嵌入空间的相似性进行了重新排序,并且最终被预订房源的排序是按照每次预定前的点击的平均值来计算,追溯到预定前的 17 次点击。
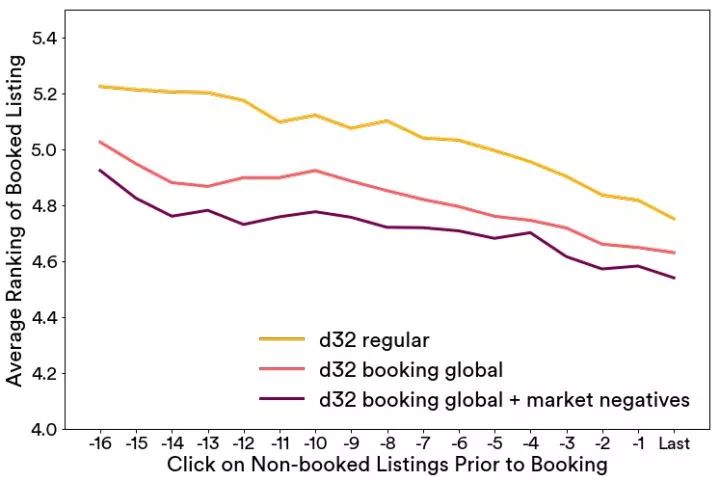
我们比较了几个嵌入版本:
d32 regular,没有对原始嵌入算法进行任何修改
d32 booking global,被预订房源作为全局上下文
d32 booking global + market negatives,被预订房源作为全局上下文,且加入了中央房源的目的地中抽样选择的随机负例样本作为负值(见上述目标优化公式)
从图中我们可以看出,第三个选项中的被预订房源一直都有较为靠前的排序,所以我们可以得出结论,这个选择要比其它两个更优。
基于嵌入的相似房源推荐
每个 Airbnb 房源详情页面都包含一个「相似房源」的轮播,推荐与当前房源相似并且可以在相同时间段内预订的房源。
在我们测试嵌入前,我们主要通过调用主搜索排序模型来搜索相同位置、价格区间和类型的房源以得出相似房源。
在有了嵌入之后,我们对此进行了 A/B 测试,将现有的相似房源算法与基于嵌入的解决方案进行了比较。在基于嵌入的解决方案中,相似房源是通过在房源嵌入空间中找到 k 个最近邻居 (k-nearest neighbors) 来生成的。 更确切地说,给定学习好了的房源嵌入,通过计算其向量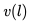 与来自相同目的地的所有房源的向量
与来自相同目的地的所有房源的向量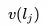 之间的余弦相似性,可以找到指定房源
之间的余弦相似性,可以找到指定房源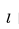 的所有可预订的相似房源(如果用户设置了入住和退房日期,房源需要在该时间段内可预订)。最终得到的
的所有可预订的相似房源(如果用户设置了入住和退房日期,房源需要在该时间段内可预订)。最终得到的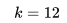 个最高相似性的房源组成了相似房源列表。
个最高相似性的房源组成了相似房源列表。
A/B 测试显示,基于嵌入的解决方案使「相似房源」点击率增加了21%,最终通过「相似房源」产生的预订增加了 4.9%。
基于嵌入的实时个性化搜索
到目前为止,我们已经看到嵌入可以有效地用于计算房源之间的相似性。 我们的下一个想法是在搜索排序中利用此功能进行一个会话内的实时个性化,目的是向用户更多展示他们喜欢的房源,更少展示他们不喜欢的房源。
为实现这一目标,我们为每个用户实时收集和维护(基于 Kafka)两组短期历史事件:
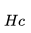 :用户在过去 2 周内点击的房源 ID
:用户在过去 2 周内点击的房源 ID
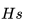 :用户在过去 2 周内跳过的房源 ID(我们将跳过的房源定义为排序较靠前的房源,但用户跳过了此房源并点击了排序较靠后的房源)
:用户在过去 2 周内跳过的房源 ID(我们将跳过的房源定义为排序较靠前的房源,但用户跳过了此房源并点击了排序较靠后的房源)
接下来,在用户进行搜索时,我们为搜索返回的每个候选房源做 2 个相似性计算:
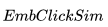
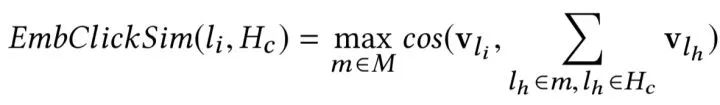
具体来说,我们计算来自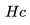 的目的地级质心之间的相似性并选择最大相似度。 例如,如果
的目的地级质心之间的相似性并选择最大相似度。 例如,如果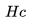 包含来自纽约和洛杉矶的房源,那么这两个目的地中每个目的地的房源嵌入将被平均以形成目的地级别的质心。
包含来自纽约和洛杉矶的房源,那么这两个目的地中每个目的地的房源嵌入将被平均以形成目的地级别的质心。
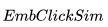
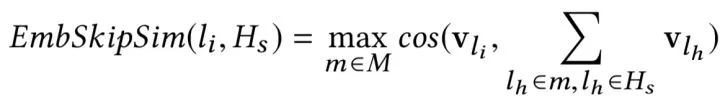
上面这两个相似性衡量的结果,会作为之后通过搜索排序机器学习模型对候选房源进行排序时考虑的附加信号。
我们首先会记录这两个嵌入相似性特征以及其他搜索排序特征,来为模型训练创建一个新的标记数据集,然后继续训练一个新的搜索排序模型,之后我们可以通过 A/B 测试来和当前线上的排序模型进行对比。
为了评估新模型是否如预期地学会了使用嵌入相似性特征,我们在下面绘制了它们的部分依赖图。这些图显示了如果我们固定住其他所有的特征值,只考虑我们正在测试的某个特征值,候选房源的排序分数会发生什么变化。
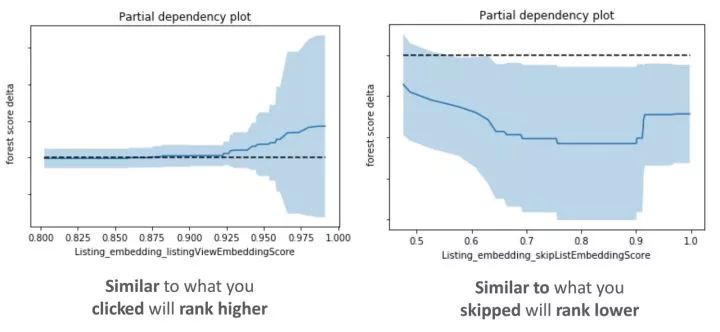
从左边的图中可以看出,较大的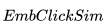 值(用户最近点击的房源的相似房源)会导致更高的模型得分。
值(用户最近点击的房源的相似房源)会导致更高的模型得分。
在右边的图中可以看出,较大的
所以部分依赖图的观察结果证实,特征行为符合我们之前预期的模型将学习的内容。除此之外,当新的嵌入特征在搜索排序模型特征中重要性排序很靠前的时候,我们的离线测试结果显示各项性能指标都有所改进。这些数据让我们做出了进行在线实验的决定,之后该实验取得了成功,我们在 2017 年夏季上线了将嵌入特征用于实时个性化生成推荐的功能。
-
神经网络
+关注
关注
42文章
4557浏览量
98604 -
机器学习
+关注
关注
66文章
8088浏览量
130500 -
Airbnb
+关注
关注
0文章
14浏览量
5341
原文标题:工程实践也能拿KDD最佳论文?解读Embeddings at Airbnb
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
《嵌入式Linux系统开发技术详解--基于ARM(完整版)》电子版
《嵌入式Linux系统开发技术详解--基于ARM(完整版)》 电子书免费资源分享
HSDPA和HSUPA在开发/部署这些新技术时存在哪类测试要求?
嵌入式Linux版本Qt5.4快速部署的相关资料分享
如何在RK3308嵌入式开发板上使用ncnn部署mobilenetv2_ssdlite模型呢
嵌入式部署或模式的相关资料分享
Embedded SIG | 多 OS 混合部署框架
部署基于嵌入的机器学习模型
Airbnb发展轨迹复盘:创业需要像打不死的小强
Airbnb机器学习和数据科学团队经验分享
嵌入式Linux开发环境部署

使用嵌入来做个性化的搜索推荐:来自Airbnb





 工商网监
工商网监
评论