 谷歌的研究人员提出了一种监督学习方法来实现语音特征的聚类
谷歌的研究人员提出了一种监督学习方法来实现语音特征的聚类
用过智能音箱的小伙伴可能会有过这样的经历,当你和朋友同时对它讲话时,它有时候同时面对两位小主的临幸会感觉很凌乱,不知道该听谁的,分不清到底是谁在向它发出指令谁才是它的主人。
其实这涉及到语音识别领域一个重要的问题Speaker diarization(即说话人分类技术),这一技术的目的在于从音频流中分离出不同人说话的语音,并将分离出的语音归并到所属的说话人上,其核心问题在于解决“who speak when”。这一技术对于理解对话、视频标注以及移动端语音识别具有重要的意义。
对于Speaker diarization来说,其处理过程一般分为四个步骤:
语音分割:将不同说话人的语音片段分割出来,在音频流中标记分割点;
音频特征抽取:利用诸如MFCC、说话人因子或i-vector等来从片段中抽取特征;
聚类:当检测到多个说话人并获取了对应语音片段的特征后需要利用聚类方法将相应的片段归类到对应的说话人中去。
重分割:优化聚类结果来提升说话人分类的精度。
近年来,基于神经网络的音频处理系统促进了这一领域的快速发展,但要训练一个在任意情况下能够准确快速识别分类说话人的模型并不是一件简单的事情。与标准的监督学习分类任务不同的是,说话人分类模型需要对新出现的说话人有着足够鲁棒的识别和分类性能,而在训练的过程中却无法囊括现实中各式各样的说话人。这在很大程度上限制了语音识别系统特别是在线系统的实时能力。
虽然已有很多工作在这个领域进行了努力,但目前整个Speaker diarization系统中依然存在着非监督学习的部分——聚类过程。聚类的表现对于整个系统有着重要的作用,但目前大多数算法都是无监督的方法,这使得我们无法通过语音样本的监督学习来改进这些算法。此外典型的聚类方法如k均值和谱聚类等非监督算法对于在线说话人识别时,应对不断输入的音频流很难有效聚类。
为了进一步提高模型的表现,谷歌的研究人员提出了一种监督学习方法来实现语音特征的聚类。在最近发表的论文“Fully Supervised Speaker Diarization”中,研究人员提出了一个名为unbounded interleaved-state recurrentneural network (UIS-RNN)的聚类算法来提高了模型的性能。在语音识别数据集上达到了7.6%的错误率,超过了其先前基于聚类方法(8.8%)和深度网络嵌入方法(9.9%)。
这一方法与通常聚类方法的主要区别在于研究人员使用了参数共享的循环神经网络为所有的说话人(embeddings)建模,并通过循环神经网络的不同状态来识别说话人,这就能将不同的语音片段与不同的人对应起来。
具体来看,每一个人的语音都可以看做权值共享的RNN的一个实例,由于生成的实例不受限所以可以适应多个说话人的场景。将RNN在不同输入下的状态对应到不同的说话人即可实现通过监督学习来实现语音片段的归并。通过完整的监督模型,可以得到语音中说话人的数量,并可以通过RNN携带时变的信息,这将会对在线系统的性能带来质的提升。
这一论文的主要贡献如下:
提出了无界间隔状态(. Unbounded interleaved-state )RNN,一个可以通过监督学习训练的对于时变数据分割和聚类的算法;
全监督的说话人分类系统;
数据集上误差提升到7.6%;
提高线上任务表现。
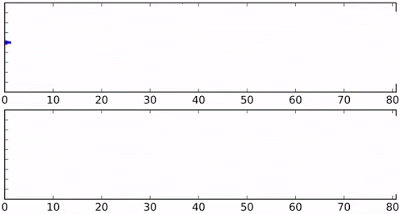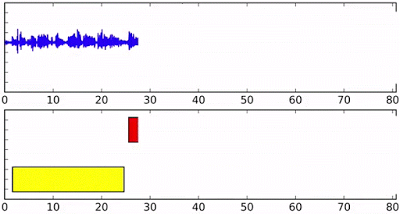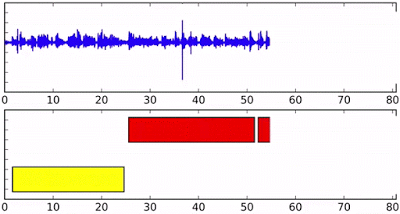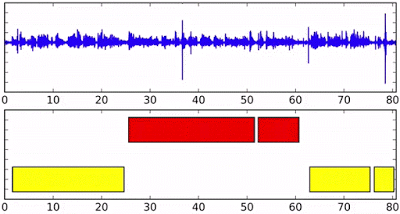
那么它具体是怎么工作的呢?假设我们有四个人同时对着这个AI说话(这是个例子,模型其实可以处理更多的人)。那么每个人将会得到一个自己的RNN实例,拥有相同的初始状态和参数。随着语音片段的特征不断被送入到网络中而更新状态。
例如下面的蓝色人在实例化后,他将一直保持RNN的状态,直到黄色的语音片段进入并开启新的RNN实例,这时在最顶部输出的状态就成为了黄色了。但后面如果蓝色继续说话,蓝色RNN状态也会相应的重新转移到蓝色上。下图最后的虚线显示了y7各种不同的状态。对于新出现的绿色说话人来说,将重新开启一个新的实例。
利用RNN对说话人语音进行表示,将能够利用RNN参数从不同的说话人和言语中学习到高层级的知识,这对于标记丰富的数据集来说将会得到更对更好的结果。利用带有时间戳的说话人标签数据,可以通过随机梯度下降法来训练模型,可用于新的说话人,并提高在线任务的表现。
在未来研究人员将会改进这一模型用于离线解码上下文信息的整合;同时还希望直接利用声学特征代替d-vectors作为音频特征,这样就能实现完整的端到端模型了。
其实,谷歌先前的工作为这一方法打下了坚实的基础。去年的论文“SPEAKER DIARIZATION WITH LSTM”中就提出了利用LSTM与d-vertor结合来提升模型的表现。
但这篇论文中使用的聚类算法依然是无监督的方法,这也为这次新工作的提出奠定了基础。
除此之外,研究人员们还尝试了利用视觉辅助的方法来识别谁在说话,并在论文“Looking to Listen at the Cocktail Party”中提出了利用视觉信息识别混合场景下说话人的方法:
相信不久后,家里的各种小可爱智能音响将可以清楚的分辨出谁是爸爸谁是妈妈,谁才是它的主人。对于嘈杂多人环境下语音指令的准确性和对话系统的交互表现有着重要的作用。同时对于音视频分析和音频高维语义信息的抽取学习将会有很大的促进作用。如果可以准确识别对话中每个人的对话、时长、分布,甚至可以分析出每个用户的语言习惯、说话节奏等高级特征,与其他技术结合将能够在行为识别、情感分析甚至语音加密等方面带来重要的影响。
-
谷歌
+关注
关注
27文章
5851浏览量
103246 -
神经网络
+关注
关注
42文章
4572浏览量
98714 -
数据集
+关注
关注
4文章
1178浏览量
24347
原文标题:听不清谁在讲话?谷歌新模型助力分辨声音的主人
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深非监督学习-Hierarchical clustering 层次聚类python的实现
一种基于聚类和竞争克隆机制的多智能体免疫算法
深度解析机器学习三类学习方法
利用机器学习来捕捉内部漏洞的工具运用无监督学习方法可发现入侵者
研究人员实现无创早期肺癌筛查,以机器学习为基础
最基础的半监督学习
半监督学习最基础的3个概念
半监督学习:比监督学习做的更好
华裔女博士提出:Facebook提出用于超参数调整的自我监督学习框架
机器学习中的无监督学习应用在哪些领域
融合零样本学习和小样本学习的弱监督学习方法综述






 工商网监
工商网监
评论