 讲解美团大脑的设计、构建以及挑战
讲解美团大脑的设计、构建以及挑战
作为人工智能时代最重要的知识表示方式之一,知识图谱能够打破不同场景下的数据隔离,为搜索、推荐、问答、解释与决策等应用提供基础支撑。
比如美团大脑就围绕吃喝玩乐场景构建的生活娱乐领域的超大规模知识图谱,为用户和商家建立起全方位的链接,对应用场景下的用户偏好和商家定位进行更深度的理解,从而能够提供更好的智能化服务。
近日,AI科技大本营邀请到了美团 AILabNLP 中心负责人、大众点评搜索智能中心负责人——王仲远博士,为大家讲解美团大脑的设计、构建以及挑战,以及美团大脑在美团点评内的具体应用。
AI科技大本营将主要内容整理如下:
▌知识图谱的重要性
这些年来人工智能正在快速地改变人们的生活,我们可以看到各家科技公司都纷纷推出人工智能产品或者系统,比如说在 2016 年的时候,谷歌推出的 AlphaGo ,一问世便横扫围棋界,完胜人类的冠军。又比如说亚马逊推出的 Amazon Go 无人超市,用户只需下载一个 App,直接走进这家超市,拿走商品,无需排队结账便可离开,这是人工智能时代的新零售体验。
又比如说老牌的科技公司微软推出的 Skype Translator,它能够帮助不同国家、不同地区的人进行实时的语音交流。再比如说世界上最大的科技公司苹果推出的 Siri 智能助理,让每一个用苹果手机的用户都能够非常便捷地完成各项的任务。所有这些人工智能产品的出现都依赖于背后各个领域突飞猛进的进展,比如说机器学习、计算机视觉、语音识别、自然语言处理等等。
作为一家领先的生活服务电子商务平台,美团点评在人工智能方面也积极地布局。今年 2 月份,AI 平台部 NLP 中心正式成立,我们的愿景是用人工智能帮大家吃得更好,生活更好。语言是人类智慧的结晶,而自然语言处理是人工智能中最为困难的问题之一,其核心是让机器像人类一样理解和使用语言。
我们希望在不远的将来,当用户发表一条评价的时候,能够让机器阅读这条评价,充分理解用户的喜怒哀乐。当用户进入大众点评的一个商家页面时,面对成千上万条用户评论,我们希望机器能够代替用户快速地阅读这些评论,总结商家的情况,供用户进行参考。未来,当用户有任何餐饮、娱乐方面的决策需求的时候,我们能够提供人工智能助理服务,帮助用户快速决策。
所有这一切都依赖于人工智能背后两大技术驱动力:深度学习和知识图谱。我将这两个技术做了一个简单的比较。
我们将深度学习归纳为隐性的模型,它通常是面向某一个具体任务,比如说下围棋、识别猫、人脸识别、语音识别等等,通常而言它需要海量的训练数据,以及非常强大的计算机,同时它也有非常多的局限性,比如说难以进行任务上的迁移,同时可解释性比较差。
另一方面,知识图谱是人工智能的另外一大技术驱动力,它能够广泛地适用于不同的任务,相比深度学习,知识图谱的可解释性非常强,类似于人类的思考。
我们可以通过上面的例子来观察深度学习技术和人类是如何识别猫的,以及它们的过程有哪些区别。
2012 年,Google X 实验室宣布使用深度学习技术,让机器成功识别了图片中的猫。它们使用了 1000 台服务器,16000 个处理器,连接成一个 10 亿节点的人工智能大脑。这个系统阅读了 1000 万张从 YouTube 上抽取的图片,最终成功识别出这个图片里有没有猫。
我们再来看看人类是如何做的。对于一个 3 岁的小朋友,我们只需要给他看几张猫的图片,他就能够识别出不同图片中的猫,而这背后其实就是大脑对于这些知识的推理。
2011 年的时候,Science 上有一篇非常出名的论文,叫 How to Grow a Mind。这篇论文的作者来自于 MIT、CMU、UC Berkeley、Stanford 等美国牛校的教授。在这篇论文里,最重要的一个结论就是,如果我们的思维能够跳出给定的数据,那么必须有 another source of information 来 make up the difference。
这里的知识语言是什么?对于人类来讲,其实就是我们从小到大接受的学校教育,报纸上、电视上看到的信息,通过社交媒体,通过与其他人交流,不断积累起来的知识。
这些年来,不管是学术界还是工业界都纷纷构建知识图谱,有面向全领域的知识图谱,也有面向垂直领域的知识图谱。其实早在文艺复兴时期,培根就提出了“知识就是力量”,在当今人工智能时代,各大科技公司更是纷纷提出知识图谱就是人工智能的基础。
全球的互联网公司都在积极布局知识图谱。早在 2010 年微软就开始构建知识图谱,包括 Satori 和 Probase。2012 年,Google 正式发布了 Google Knowledge Graph。到目前为止,整个 Google Knowledge Graph 的规模在 700 亿左右。目前微软和 Google 拥有全世界最大的通用知识图谱,Facebook 拥有全世界最大的社交知识图谱,而阿里巴巴和亚马逊则构建了商品知识图谱。
如果按照人类理解问题和回答问题这一过程来进行区分,我们可以将知识图谱分成两类。我们来看这样一个例子,如果用户看到这样一个问题,“Who was the U.S. President when the Angels won the World Series?”我想所有的用户都能够理解这个问题,也就是当 Angels 队赢了 World Series 的时候,谁是美国的总统?
这是一个问题理解的过程,它所需要的知识通常我们叫它 common sense knowledge(常识性知识)。另外一方面,我想很多网友们应该回答不出这个问题,因为它需要另外一个百科全书式的知识。
因此,我们将知识图谱分成两大类,一类叫Common Sense Knowledge Graph(常识知识图谱),另外一类叫Encyclopedia Knowledge Graph(百科全书知识图谱)。这两类知识图谱有很明显的区别。针对 Common Sense Knowledge Graph,通常而言我们会挖掘这些词之间的 linguistic knowledge;对于 Encyclopedia Knowledge Graph,我们通常会在乎它的 Entities,和这些 Entities 之间的 Facts。
对于 Common Sense Knowledge Graph,一般而言我们比较在乎的 relation 包括 isA relation,isPropertyOf relation。对于 Encyclopedia Knowledge Graph,通常我们会预定义一些谓词,比如说DayOfbirth,LocatedIn,SpouseOf。
对于Common Sense Knowledge Graph 通常带有一定概率,但是 Encyclopedia Knowledge Graph 通常非黑即白,那么构建这种知识图谱的时候我们在乎的是 Precision(准确率)。
Common Sense Knowledge Graph 比较有代表性的工作包括 WordNet、KnowItAll、NELL,以及 Microsoft Concept Graph。而 Encyclopedia Knowledge Graph 则有 Freepase、Yago、Google Knowledge Graph,以及正在构建中的“美团大脑”。
在今天的课程中,我会跟大家介绍两个代表性工作,分别是 Common Sense Knowledge Graph:Probase,以及我们正在做的美团大脑,它是一个 Encyclopedia Knowledge Graph。
▌常识性知识图谱(Common Sense Knowledge Graph)
Microsoft Concept Graph 于 2016 年 11 月正式发布,但是它早在 2010 年就已经开始进行研究,是一个非常大的图谱。在这个图谱里面有上百万个 Nodes(节点),这些 Nodes 有Concepts(概念),比如说 Spanish Artists(西班牙艺术家);有 Entities(实体),比如说 Picasso(毕加索);有 Attributes(属性),比如 Birthday(生日);有 Verbs(动词),有 Adjectives(形容词),比如说 Eat、Sweet。也有很多很多的边,最重要的边,是这种 isA 边,比如说 Picasso,还有 isPropertyOf边。对于其他的 relation,我们会统称为 Co-occurance 。
这是我们在微软亚洲研究院期间对 Common Sense Knowledge Graph 的 Research Roadmap(研究路线图)。当我们构建出 Common Sense Knowledge Graph 之后,重要的是在上面构建各种各样的模型。我们提出了一些模型叫 Conceptualization(概念化模型),它能够支持 Term Similarity、Short Text Similarity 以及 Head-Modifier Detection,最终支持各种应用,比如NER,文本标注,Ads,Query Recommendation,Text Understanding。
到底什么是 short text understanding?常识怎么用在 text understanding 里?下面我们可以看一些具体的例子。
当大家看到上面中间的文本的时,我想所有人都能够认出这应该是一个日期,但是大家没办法知道这个日期代表什么样的含义。但如果我再多给一些上下文信息,比如 Picasso、Spanish,大家对这个日期就会有一些常识性的推理。我们会猜测这个日期很可能是 Picasso 的出生日期,或者是去世日期,这就是常识。
比如说当我们给定 China 和 India 这两个 entity 的时候,我们的大脑就会做出一些常识性的推理,我们会认为这两个 entity 在描述 country。如果再多给一个 entity:Brazil,这时候我们通常会想到 emerging market。如果再加上 Russia,通常大家可能就会想的是金砖四国或者金砖五国。所有这一切就是常识性的推理。
再比如当我们看到 engineer 和 apple 的时候,我们会对 apple 做一些推理,认为它就是一个 IT company,但是如果再多给一些上下文信息,在这个句子里面由于 eating 的出现,我相信大家的大脑也会一样地做出常识推理,认为这个 apple 不再是代表 company,而是代表 fruit。
所以这就是我们提出来的 Conceptualization Model,它是一个 explicit representation。我们希望它能够将 text,尤其是 short text,映射到 millions concepts,这样的 representation 能够比较容易让用户进行理解,同时能够应用到不同场景当中。
在这一页的 PPT 里面,我们展示了 Conceptualization 的结果。当输入是 pear 和 apple 的时候,那么我们会将这个 apple 映射到 fruit。但是如果是 ipad apple 的时候,我们会将它映射到 company,同时大家注意这并不是唯一的结果,我们实际上是会被映射到一个 concept vector。这个 concept vector 有多大?它是百万级维度的 vector,同时也是一个非常sparse的一个 vector。
通过这样的一个 Conceptualization Model,我们能够解决什么样的文本理解问题?我们可以看这样一个例子。比如说给定一个非常短的一个文本,Python,它只是一个 single instance,那么我们会希望将它映射到至少两大类的 concept 上,一种可能是 programming language,另外一种是 snake。当它有一些 context,比如说 Python tutorial 的时候,那么这个时候 Python 指的应该是 programming language。另外如果当它有其他的 adjective、verb,比如 dangerous 的时候,这时候我们就会将 Python 理解为 snake。
同时如果在一个文本里面包含了多个的 entity,比如说 DNN Tool,Python,那么我们希望能够检测出在这个文本里面哪一个是比较重要的 entity,哪一个是用来做限制的 entity。
下面我将简单地介绍一下具体是怎么去做的。当我们在 Google 里搜一个 single instance 的时候,通常在右侧会出现这个 Knowledge Panel。对于 Microsoft 这样一个 instance,我们可以看到这个红色框所框出来的 concept,Microsoft 指向的是 technology company,这背后是怎么去做的?
我们可以看到,Microsoft 实际上会指向非常非常多的 concept,比如说 company,software company,technology leader 等等。我们将它映射到哪一个 concept 上最合适?
如果我们将它映射到 company 这个 concept 上,很显然它是对的,但是我们却没办法将 Microsoft 和 KFC、BMW 这样其他类型的产品区分开来。另外一方面,如果我们将 Microsoft 映射到 largest desktop OS vendor 上,那么这是一个非常 specific 的一个concept,这样也不太好,为什么?因为这个 concept 太 specific,太 detail,它可能只包含了 Microsoft 这样一个 entity,那么它就失去了 concept 的抽象能力。
所以我们希望将 Microsoft 映射到一个既不是特别 general(抽象),又不是一个特别 specific(具体)的 concept 上。在语言学上,我们将这种映射称之为 Basic-level,我们将整个映射过程命名为 Basic-level Conceptualization。
我们提出了一种计算 Basic-level Conceptualization 的方法,其实它非常简单但有非常有效。就是将两种的typicality做了一些融合,同时我们也证明了它们跟 PMI 和 Commute Time 之间的一些关联。并且在一个大规模的数据集上,我们通过 Precision 和 NDCG 对它们进行了评价。最后证明,我们所提出来的scoring方法,它在 NDCG 和 Precision 上都能达到比较好的结果。最重要的是,它在理论上是能够对 Basic-Level 进行很好的解释。

下面我们来看一下当 instance 有了一些 context 之后,我们应该怎么去进行处理。我们通过一个例子来简单地解释一下这背后最主要的思想。
比如说 ipad,apple,其中 ipad 基本上是没有歧异的,它会映射到 device、product。但是对于 apple 而言,它可能会映射到至少两类的 concept 上,比如说 fruit,company。那么我们怎么用 ipad 对 apple 做消歧呢?
方法其实也挺直观的。我们会通过大量的统计去发现像 ipad 这样的 entity,通常会跟company、product 共同出现。比如说 ipad 有可能会跟三星共同出现,有可能会跟 google 共同出现,那么我们就发现它会经常跟 brand,company,product共同出现。于是我们就利用新挖掘出来的 knowledge 对 apple 做消歧,这就是背后最主要的思想。
除了刚才这样一个general context 以外,在很多时候这些 text 可能还会包含很多一些特殊的类型,比如说verb、adjective。具体而言,我们希望在看到 watch harry potter 时,能够知道 harry potter 是 movie,当我们看到 read harry potter 时,能够知道 harry potter 是 book。同样的,harry potter 还有可能是一个角色名称或者一个游戏名称。
那么我们来看一看应该怎样去解决这样一件事情。当我们看到 watch harry potter 的时候,我们首先要知道,harry potter 有可能是一本 book,也有可能是一部 movie。我们可以算出的一个先验概率,这通常要通过大规模的统计。同时我们要知道,watch 它有可能是一个名词,同时它也有可能是一个动词,并且我们还需要去挖掘,当 watch 作为动词的时候,它和 movie 有非常紧密的关联。
所以我们本质上是要去做一些概率上的推理。在论文中我们就会将条件概率做非常细粒度的分解,最后做概率计算。
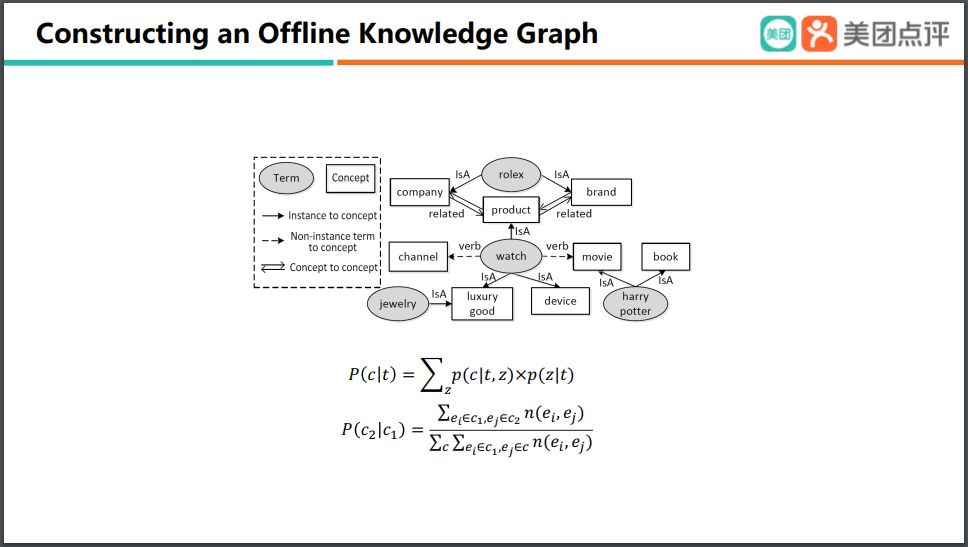
通过概率计算的方法,我们实际上就可以构建出一个非常非常大的离线的的知识图谱,那么我们在这个上面就可以有很多的 term,以及它们所属的一些 type,以及不同term之间的一些关联。
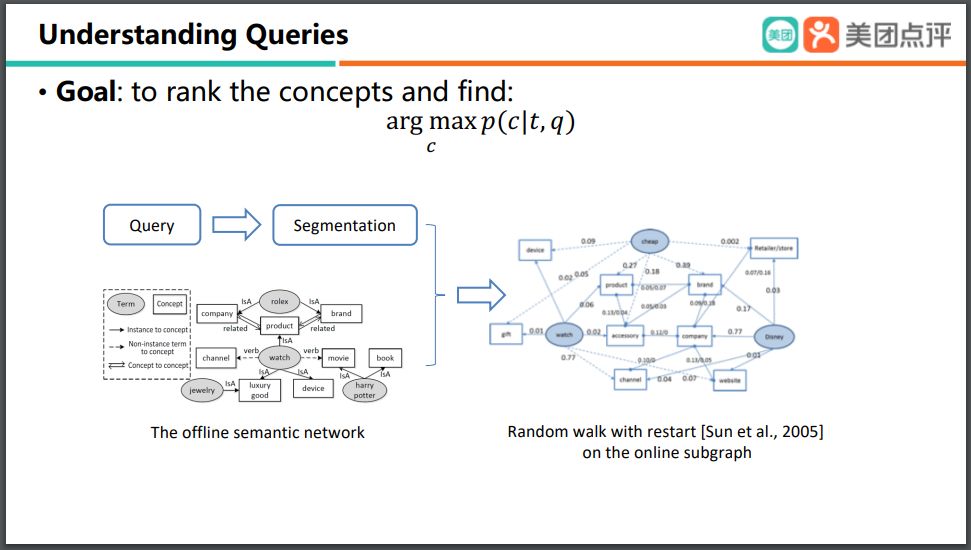
当我们用这样一个非常大的离线知识图谱来做 text understanding 的时候,我们可以首先将这个 text 进行分割处理,在分割之后,我们实际上是可以从这个非常大的离线知识图谱截取出它的一个子图。最后我们使用了 Random walk with restart 的模型,来对这样一个在线的 subgraph 进行分类。
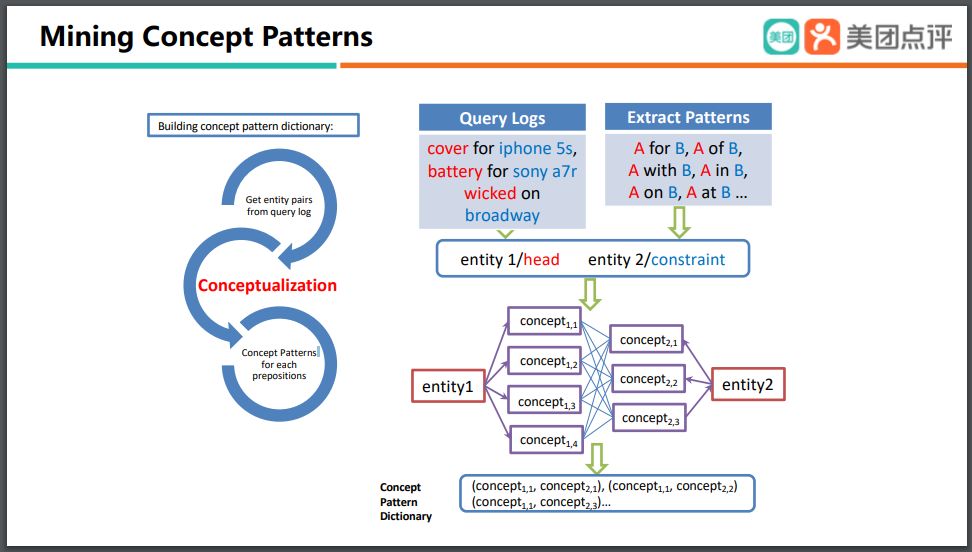
我们再来看,如果一个文本里包含了 multiple entities,要怎样处理?我们需要做知识挖掘,怎么做?首先我们可以得到非常多的 query log,然后我们也可以去预定一些 pattern,通过这种 Pattern 的定义,可以抽取出非常多 entity 之间 head 和 modifier 这样的 relation,那么在接下来我们可以将这些 entity 映射到 concept 上,之后得到一个 pattern。

在这个过程之中,我们要将 entity 映射到 concept 上,那么这就是前面所提到的Conceptualization。我们希望之后的映射不能太 general,避免 concept pattern 冲突。
但是它也不能太 specific,因为如果太 specific,可能就会缺少表达能力。最坏的情况,它有可能就会退化到 entity level,而 entity 至少都是百万的规模,那么整个 concept patterns 就有可能变成百万乘以百万的级别,显然是不可用的。
所以我们就用到了前面介绍的 Basic-level Conceptualization 的方法,将它映射到一个既不是特别 general,也不是特别 specific 的 concept 上。
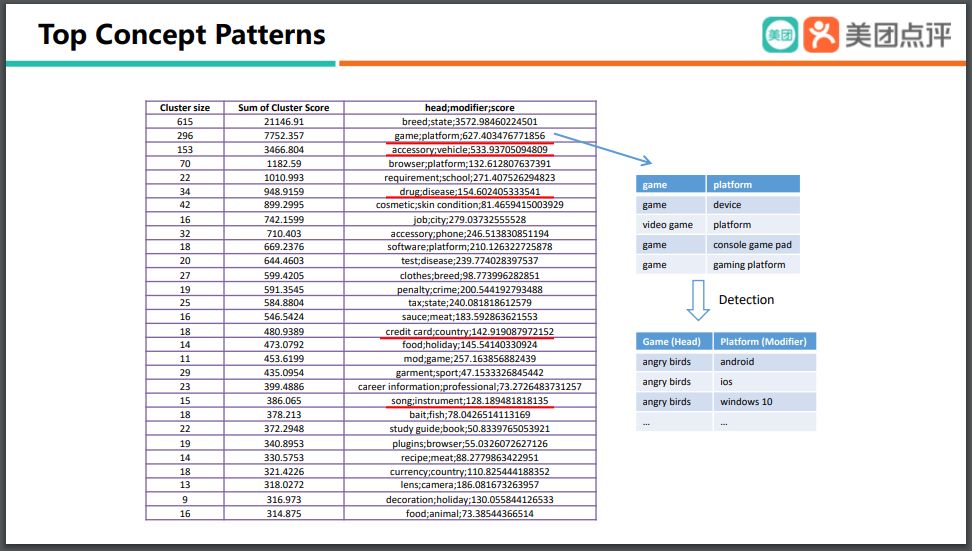
大家可以看一下我们能够挖掘出来的一些 Top 的 concept patterns,比如说 game 和platform,就是一个 concept 和一个 pattern。它有什么用?举一个具体的例子,当用户在搜 angry birds、ios 的时候,我们就可以知道用户想找的是 angry birds 这款游戏,而 ios 是用来限制这款游戏的一个 platform。苹果公司每年都会推出新版本的 ios,那么我们挖掘出这样的 concept pattern之后,不管苹果出到 ios 15或者 ios 16,那么我们只需要将它们映射到 platform,那么我们的 concept patterns 就仍然有效,这样可以很容易地进行知识扩展。
所以 Common Sense Knowledge Mining 以及 Conceptualization Modeling,可以用在很多很多的应用上,它可以用来算 Short text similarity,所以它可以用来做 classification,clustering,也可以用来做广告的 semantic match,Q/A system,Chatbot 等等。
▌美团大脑——百科全书式知识图谱(Encyclopedia Knowledge Graph)
在介绍完 Common Sense Knowledge Graph 之后,给大家介绍一下 Encyclopedia Knowledge Graph。这是美团的知识图谱项目——美团大脑。
美团大脑是什么?美团大脑是我们正在构建中的一个全球最大的餐饮娱乐知识图谱。我们希望能够充分地挖掘关联美团点评各个业务场景里的公开数据,比如说我们有累计 40 亿的用户评价,超过 10 万条个性化标签,遍布全球的 3000 多万商户以及超过 1.4 亿的店菜,我们还定义了 20 级细粒度的情感分析。
我们希望能够充分挖掘出这些元素之间的关联,构建出一个知识的大脑,用它来提供更加智能的服务。
那么下面我简单地介绍一下美团大脑是如何进行构建的。我们会使用 Language Model(统计语言模型)、Topic Model(主题生成模型) 以及 Deep Learning Model(深度学习模型) 等各种模型,希望能够做到商家标签的挖掘,菜品标签的挖掘和情感分析的挖掘等等。
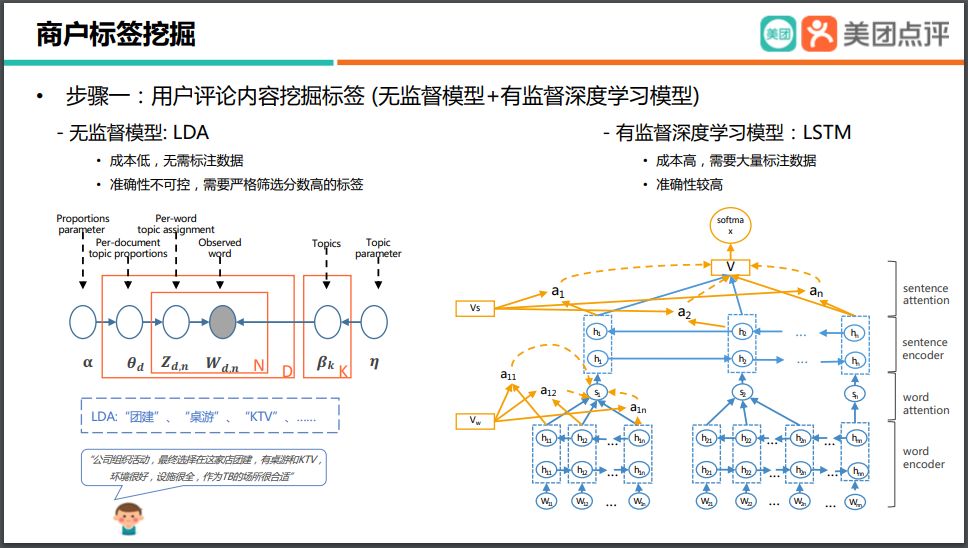
为了挖掘商户标签,首先我们要让机器去阅读评论。我们使用了无监督和有监督的深度学习模型。
无监督模型我们主要用了LDA,它的特点是成本比较低,无需标注的数据。当然,它准确性会比较不可控,同时对挖掘出来的标签我们还需要进行人工的筛选。至于有监督的深度学习模型,那么我们用了 LSTM,它的特点是需要比较大量的标注数据。
通过这两种模型挖掘出来的标签,我们会再加上知识图谱里面的一些推理,最终构建出商户的标签。
如果这个商户有很多的评价,都是围绕着宝宝椅、带娃吃饭、儿童套餐等话题,那么我们就可以得出很多关于这个商户的标签。比如说我们可以知道它是一个亲子餐厅,它的环境比较别致,它的服务比较热情。
下面介绍一下我们如何对菜品进行标签的挖掘?我们使用了 Bi-LSTM 以及 CRF 模型。比如说从这个评论里面我们就可以抽取出这样的 entity,再通过与其他的一些菜谱网站做一些关联,我们就可以得到它的食材、烹饪方法、口味等信息,这样我们就为每一个店菜挖掘出了非常丰富的口味标签、食材标签等各种各样的标签。
下面再简单介绍一下我们如何进行评论数据的情感挖掘。我们用的是 CNN+LSTM 的模型,对于每一个用户的评价我们都能够分析出他的一些情感的倾向。同时我们也正在做细粒度的情感分析,我们希望能够通过用户短短的评价,分析出他在不同的维度,比如说交通、环境、卫生、菜品、口味等方面的不同的情感分析的结果。这种细粒度的情感分析果,目前在全世界都没有很好的解决办法。
下面介绍一下我们的知识图谱是如何进行落地的。目前业界知识图谱已经有非常多的成熟应用,比如搜索、推荐、问答机器人、智能助理,包括在穿戴设备、反欺诈、临床决策上都有非常好的应用。同时业界也有很多的探索,包括智能的商业模式、智能的市场洞察、智能的会员体系等等。
如何用知识图谱来改进我们的搜索?如果大家现在打开大众点评,当大家搜索某一个菜品时,比如说麻辣小龙虾,其实我们的机器是已经帮大家提前阅读了所有的评价,然后分析出提供这道菜品的商家,我们还会用用户评论的情感分析结果来改进搜索排序。
此外,我们也将它用在了商圈的个性化推荐。当大家打开大众点评时,如果你现在位于某一个商场或者商圈,那么大家很快就能够看到这个商场或者商圈的页面入口。当用户进入这个商场和商户的页面时,通过知识图谱我们就能够提供千人千面的个性化排序和个性化推荐。
在这背后其实使用了一个水波的深度学习模型,关于这个深度学习模型更详细的介绍,大家可以参见我们在 CIKM 上的一篇论文。
所有的这一切其实还有很多的技术突破等待我们的解决。比如整个美团大脑的知识图谱在百亿的量级,是世界上最大的餐饮娱乐知识图谱。为了支撑这个知识图谱,我们需要去研究千亿级别的图存储和计算引擎技术。我们也正在搭建一个超大规模的 GPU 集群,来支持海量数据的深度学习算法。未来当所有的这些技术都 ready 之后,我们希望能够为所有用户提供智慧餐厅和智能助理的体验。
-
人工智能
+关注
关注
1776文章
43766浏览量
230551 -
美团
+关注
关注
0文章
123浏览量
10142 -
知识图谱
+关注
关注
2文章
131浏览量
7593
原文标题:美团大脑:知识图谱的建模方法及其应用 | 公开课笔记
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
鸿蒙开发【编译构建】讲解
大模型数据集:构建、挑战与未来趋势
英飞凌EiceDRIVER™技术以及应对SiC MOSFET驱动的挑战

LOAM源代码中坐标变换部分的详细讲解

HarmonyOS SDK,赋能开发者实现更具象、个性化开发诉求
智能制造设备如何拥有最强大脑?机器视觉+AI
LoRa技术在实际应用中可能遇到的问题和挑战以及解决方案

工信部围绕“工业大脑”“城市大脑”征集先进计算典型应用案例
基于IC14518构建的频率计电路图讲解





 工商网监
工商网监
评论