 图像生成领域的一个巨大进展:SAGAN
图像生成领域的一个巨大进展:SAGAN
编者按:几个月前,论智介绍了图像生成领域的一个巨大进展:SAGAN。在那篇论文中,罗格斯大学和Google Brain的研究人员大胆把NLP中的self-attention模型引入GAN,解决了特征记忆问题,把图像生成的初始分数(IS)从36.8一下提到了52.52。而近日,一篇ICLR 2019的Open Review论文(赫瑞-瓦特大学&DeepMind)带来了更震撼结果,他们把IS一下子提高了一百多分,从52.52提升到了166.3。
摘要
尽管学界在生成图像建模上取得了不小进展,但从像ImageNet这样的复杂数据集中成功生成高分辨率、多样化的样本仍然是一个难以实现的目标。为此,我们以至今最大规模训练了生成对抗网络(GAN),并研究了这种规模所特有的不稳定性。研究发现,通过在生成器上使用正交正则化,我们可以让它适应简单的“截断技巧”,即允许利用“截断”潜在空间来精确控制样本保真度和多样性之间的权衡。
我们的修改使模型的性能达到了新高度。当我们在ImageNet上用128×128分辨率的图像进行训练时,我们的模型(BigGAN)的IS为166.3,FID为9.6,而之前的最佳记录是IS 52.52,FID 18.65。
简介
近年来,生成图像建模领域出现了不少成果,其中最前沿的是GAN,它能直接从数据中学习,生成高保真、多样化的图像。虽然GAN的训练是动态的,而且对各方面的设置都很敏感(从优化参数到模型架构),但大量研究已经证实,这种方法可以在各种环境中稳定训练。
尽管取得了这些进步,当前生成图像模型在ImageNet数据集上的表现还是很一般,最高IS只有52.52,而真实图像数据的得分高达233。
在这篇论文中,研究人员通过一系列修改,缩小了GAN生成的图像和ImageNet中的真实图像之间的差异,他们做出的贡献主要有以下三点:
证明GAN能从大规模训练中受益。通过对体系结构做了两个简单修改,他们在训练过程中使用的参数量是现有研究的2-4倍,batch size是8倍,但模型性能有显著提高。
作为改进的副作用,新模型非常适合“截断技巧”,即精确控制样本保真度和多样性之间的权衡。
发现大规模GAN的特有不稳定性,并根据经验进行表征。根据分析所得,他们认为把新方法和现有技术结合可以缓解这种不稳定性,但如果要实现完全的稳定训练,这会大大有损性能。
主要改进
本文提出的BigGAN遵循了SAGAN的基本架构,它基于ResNet,但判别器D中的通道和一般ResNet不同,每个模块的第一个卷积层的filter数量等于输出的filter数,而不是输入数。

在128×128 ImageNet数据上的架构
研究人员首先简单增加了基线模型的batch size,这样做的效果如下表所示。随着batch size逐渐变为基线的2倍、4倍、8倍,模型的FID不断下降,IS不断增加,至8倍时,BigGAN的IS较SAGAN已经提高了约46%。对于这个结果,他们提出的一个猜想是更大的batch size意味着每个batch覆盖的模式更多,这为两个神经网络提供了更好的梯度。
但这么做也有缺点,就是虽然模型能在更少的迭代中达到更好的最终性能,但它很不稳定,甚至会在训练时崩溃。
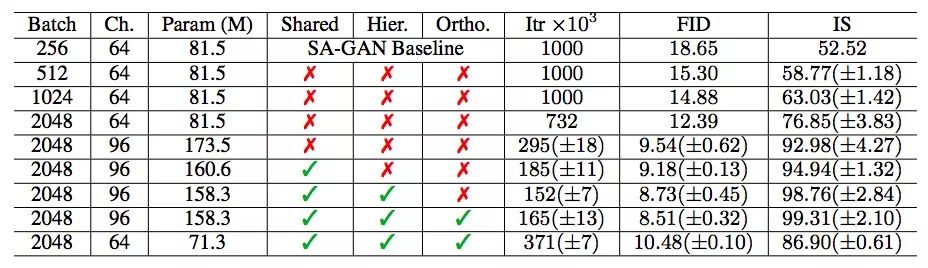
各batch size下BigGAN的IS(越高越好)和FID(越低越好)
之后,他们又把神经网络每一层的通道数在原有基础上增加了50%,这时每个神经网络的参数数量也几乎翻了一倍。当BigGAN的参数数量是SAGAN的两倍时,它的IS较后者提高了约21%。对此,他们给出的解释是,相对于数据集的复杂性,模型的容量增加了。而增加神经网络深度不会产生相似效果,反而会降低最终性能。
考虑到生成器G中conditional BatchNorm layer的类嵌入c包含大量权重,他们不再为每个嵌入分别设置一个层,而是使用了一个共享嵌入,由它投影到每一层。这降低了计算和存储成本,并把训练速度提高了37%。同时,他们使用了分层潜在空间的变体,把噪声向量z馈送进生成器的多个层,直接影响不同分辨率和层次结构级别的特征。
(a)常规生成器架构;(b)生成器中的残差块
生成效果
BigGAN生成的各个类别的图像
BigGAN生成的256×256的图像
BigGAN生成的512×512的图像
上面是论文呈现的一些生成图像。虽然其他GAN也能精选一些不错的图,但对比细节,BigGAN在质地、光影、外形等方面的表现都优于以往成果。而且就SAGAN强调的腿部生成效果来看,上图中公鸡的腿不突兀、更自然,和真实图像难以区分。
-
神经网络
+关注
关注
42文章
4568浏览量
98702 -
图像
+关注
关注
2文章
1063浏览量
40034 -
GaN
+关注
关注
19文章
1761浏览量
67837
原文标题:DeepMind:从52.52到166.3,图像生成再现巨大突破
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于扩散模型的图像生成过程

低质量图像的生成与增强的区别 图像生成领域中存在的难点

请问labview vision 做了一个改变图像尺寸的每次生成的图片都是黑的是为什么?
关于使用LabVIEW生成彩色图像的问题
总结可微图像参数表示的最新进展
图像生成领域的一个巨大进展,BigGAN的效果真的有那么好吗?
三星在图像传感器领域的进展介绍
基于生成式对抗网络的端到端图像去雾模型

一种基于改进的DCGAN生成SAR图像的方法

如何去解决文本到图像生成的跨模态对比损失问题?





 工商网监
工商网监
评论