 构建中文网页分类器对网页进行文本分类
构建中文网页分类器对网页进行文本分类
网络原指用一个巨大的虚拟画面,把所有东西连接起来,也可以作为动词使用。在计算机领域中,网络就是用物理链路将各个孤立的工作站或主机相连在一起,组成数据链路,从而达到资源共享和通信的目的。凡将地理位置不同,并具有独立功能的多个计算机系统通过通信设备和线路而连接起来,且以功能完善的网络软件(网络协议、信息交换方式及网络操作系统等)实现网络资源共享的系统,可称为计算机网络。网络的迅速发展,使人们不仅面临信息爆炸,同时也面临着如何从浩如烟海的信息中获取自己所需信息的难题。如何有效地组织和处理海量的信息,并过滤和管理网络资源,已成为必须面对的问题。
为了网页信息的有效组织和检索,人们开发了各种网络信息搜索器,在一定程度上确实提高了网络信息的利用率。与文本分类技术相比较,网页分类更加复杂,这是由网页的结构特征决定的,但是网页的信息主要是通过文本的方式向人们传递的,所以在对网页分类之前,首先要对其中的文本进行提取,对所提取的文本分类,最终使网页分类问题转化为文本分类问题。
目前,文本分类技术的研究比较活跃,已经出现了多种文本分类算法,并且被广泛应用于多个领域:信息检索、搜索引擎、文本数据库等。文本分类算法基本是基于概率统计模型,本文就是基于互信息(MI)提出一种改进的特征提取方法,并根据TFIDF提出一种新的特征权值计算方法构建中文网页分类器。
1 网页预处理
网页分类之前首先要进行预处理,实际上就是HTML解析,把解析出来的内容用于文本分类,选取网页中的下面这些文本用于分类:
(1)锚文本。锚文本是网页中用于指示所连接网页内容的提示,由于后面要对提取的文本进行分类,所以只提取文字形式的锚文本。
(2)title文本。这样的文本可能是网页中最重要的标签,必须取得。
(3)meta标签。其重要的功能就是设置关键字,网页的制作者往往都设置了关键字,来提高网页的搜索点击率。可以利用meta标签中的有关文本内容进行网页分类。
(4)主文本。上面这些信息获取之后,网页中剩余的文本信息还在各种HTML标签中,在HTML源文件中,主文本有可能不是连续出现的。主文本一般是网页中文字最集中的较长的字符串,查看源文件,那些比较长的字符串是整个出现在1个标签中的。
文本首先要确定的问题就是表示文本的基本单位,用于表示文本的基本单位通常称为文本的特征或特征项。中文文本不同于英文文本,英文文本以空格为分隔符,非常明确。而中文文本需要对其进行分词处理才能得出每个特征。本文采用中科院计算技术研究所汉语词法分析系统ICTCLAS3.0进行分词。如果把这些对文本分类没有意义的虚词作为特征,将会带来很大噪音,降低文本分类的效率和准确率。因此,在提取文本特征时,应首先考虑剔除这些对文本分类没有用处的虚词,而在实词中,又以名词和动词对于文本的类别特性的表现力最强。
2 特征提取
特征提取就是提取出最能代表某篇文章或某类的特征项,以达到降维的效果从而减少文本分类的计算量。典型特征提取方法:信息增益(Information Gain),互信息(MI)、文档频度(DF)。传统的MI特征提取方法:
计算出所有特征词的统计值后,从大到小进行排序,然后根据需要从上到下选取一定数量的特征词构建文本分类的特征词库。
3 特征加权及向量化
TFIDF算法及其改进型[5]有多种公式,本文使用一种新的改进的TF-IDF公式来计算特征词的权重。TF-IDF公式有很多变种,比较常见的TF-IDF公式:

:
-
HTML
+关注
关注
0文章
273浏览量
29270 -
分类器
+关注
关注
0文章
152浏览量
13111 -
文本
+关注
关注
0文章
118浏览量
16919
发布评论请先 登录
相关推荐
pyhanlp文本分类与情感分析
NLPIR平台在文本分类方面的技术解析
基于文章标题信息的汉语自动文本分类
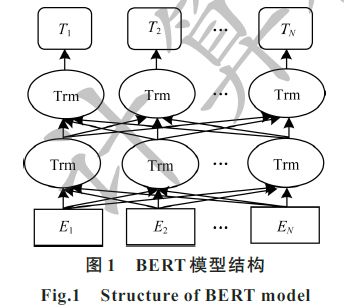
结合BERT模型的中文文本分类算法





 工商网监
工商网监
评论