 赛灵思全新reVISION™ 堆栈如何更快速的开发机器学习应用
赛灵思全新reVISION™ 堆栈如何更快速的开发机器学习应用
既能软件定义,又能硬件优化,管你市场风云变幻,管你市场标准、用户需求如何莫测, 赛灵思All Programmable (全可编程芯片) 都能像变形金刚一样, 让用户的设计永居科技前沿!
然而……
由于可编程器件硬件编程模式的限制,全可编程的解决方案一直惠及的只是少数拥有硬件专业知识的工程设计者。尽管赛灵思通过高层次综合工具Vivado HLS 以及软件定义设计环境系列SDSoC/SDAccel 让上千用户也享受到了硬件加速设计的优势, 但是这些还是远远不能满足市场对全可编程技术的需求。
赛灵思全球同步发布最新软件定义reVISION™ 堆栈,宣布能够支持更广泛的很少或没有硬件设计专业知识的嵌入式软件和系统工程师,使其也能利用赛灵思的技术更轻松、更快速地开发视觉导向的机器学习应用。让我们来了解一下这个全新的reVISION吧 。
reVISION: 将全可编程技术扩展至广泛的视觉导向机器学习应用
机器学习的应用正迅速地扩展至越来越多的终端市场,在用户端、在云端或者在那些基于端处理与基于云的数据分析相结合的混合解决方案中。
面向云应用,赛灵思最近推出了可重配置加速堆栈(2016年11月推出),目标直指包括机器学习推断在内的各种计算加速应用。 面向端应用,赛灵思现在宣布凭借Xilinx® reVISION™ 堆栈大幅扩展至广泛的视觉导向机器学习应用。 全新的reVISION堆栈能够支持更广泛的很少或没有硬件设计专业知识的嵌入式软件和系统工程师,使其也能利用赛灵思的技术更轻松、更快速地开发视觉导向的机器学习应用。
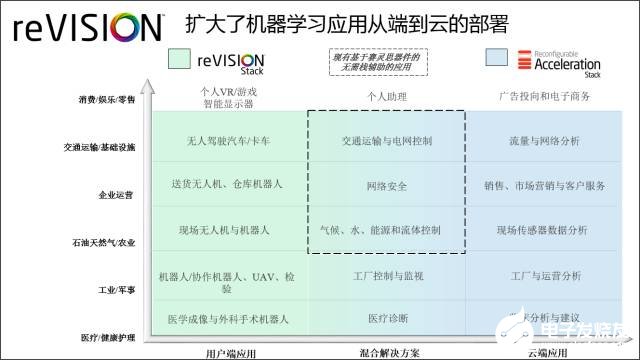
图1, 赛灵思扩大机器学习应用从端到云的部署 (来源:Machine Learning Landscape - Moor Insights & Strategy Research Paper)
广泛的赛灵思视觉和机器学习应用
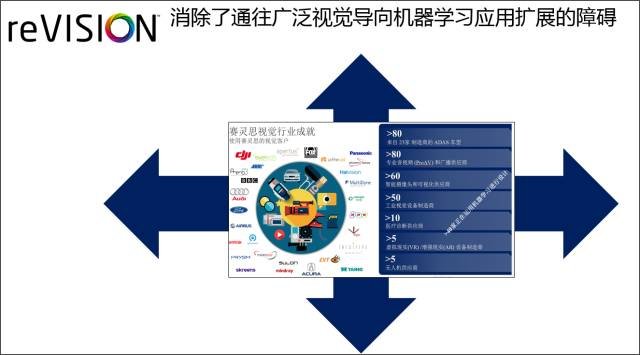
如图2 所示, 放眼全球,赛灵思已经成为众多企业构建先进嵌入式视觉系统的最佳选择。 截至今天,全球已经有23 家汽车制造商在 85 款不同车型的 ADAS 系统中部署了赛灵思先进的嵌入式视觉系统,另外还有数百家嵌入式视觉客户在其他数千种应用中也部署了赛灵思的先进嵌入式视觉系统。其中至少有40家已经在开发或部署机器学习技术以大幅提高系统的智能。现在,大多数的赛灵思视觉客户包括具有很强硬件专长的工程师们,都看准了 Zynq® All Programmable SoC 和 MPSoC 的应用。
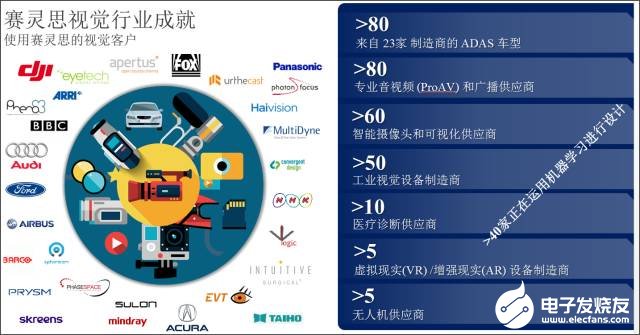
图 2:赛灵思嵌入式视觉行业成就
reVISION 的目标应用和使命
赛灵思正在为一些热门市场的应用提供支持。在这些市场中,差异化至关重要,系统必须响应迅速,最新算法和传感器必须能够被快速部署。这些应用包括“专业消费类”应用、汽车、工业、医疗、航空航天、军用以及高端前沿消费者应用。这些应用通常不包括部署在差异化较低的“够用就好”或者发展成熟的技术之上的非常大批量的消费类应用或者主流商品化应用在。
如图 3 所示,众多的传统嵌入式视觉应用通过采用机器视觉和传感器融合技术后都在发生巨变。

图3. 从嵌入式视觉到视觉导向的自主系统
下一代应用包括协作机器人、具有感应和躲避功能的无人机、增强现实、自动驾驶汽车、自动化监视和医疗诊断等。这些系统通常具有三大使命:
第一:系统不仅要会思考,而且还能对情境立即做出“响应”。这就要求一个从感应到处理、分析、决策、通信和控制整个流程中更一致的视图。同时还要高效实施、部署最新机器学习技术,满足8位及更深层面的精确性要求。注意,针对机器学习训练优化的技术继续偏离对机器学习推断优化的技术。 赛灵思已经专门为推断技术优化了其全可编程器件系列。
图4:下一代视觉导向系统的应用使命
第二:鉴于神经网络和相关算法的快速变化以及传感器的快速发展,必须实现灵活性,能通过软硬件的可重配置性升级系统。
第三:由于许多新系统都连接到了一起(物联网),因此需要既能与传统的已有设备通信,也能与未来推出的新设备通信,同时还要能够进行云端通信。赛灵思将此定义为任意互联。
赛灵思器件可以独特地支持以上所有三大使命, 且比其它替代方案拥有显著的和可测量的优势。 通过高效的推断和控制,赛灵思实现了传感器的最快响应时间,支持最新的神经网络,算法和传感器的可重构性,并支持与传统或新机器、网络和云的任意连接。
图5:赛灵思独特的应用优势
然而,赛灵思器件的这些优势原来只有那些拥有硬件或者RTL 设计专长的专业用户才能受益,对于更广泛的应用和支持使用行业标准库和框架进行软件定义编程,还存在巨大的障碍。 reVISION堆栈的诞生, 解决了这个通往广泛应用的障碍。
图6:广泛应用的障碍
赛灵思 reVISION 堆栈包括用于平台、算法和应用开发的丰富的开发资源,支持最流行的神经网络(诸如 AlexNet、GoogLeNet、SqueezeNet、SSD 和 FCN)以及库元素(如 CNN 网络层的预定义优化型实现方案,这也是构建定制神经网络 DNN/CNN 所需的)。配合丰富的满足加速要求的 OpenCV 功能,支持机器视觉处理。对应用层面的开发来说,赛灵思支持流行的框架,包括用于机器学习的 Caffe 和用于计算机视觉的 OpenVX(将于 2017 年下半年推出)。reVISION 堆栈还包括赛灵思和第三方提供的基于 Zynq SoC 和 MPSoC 的开发平台。
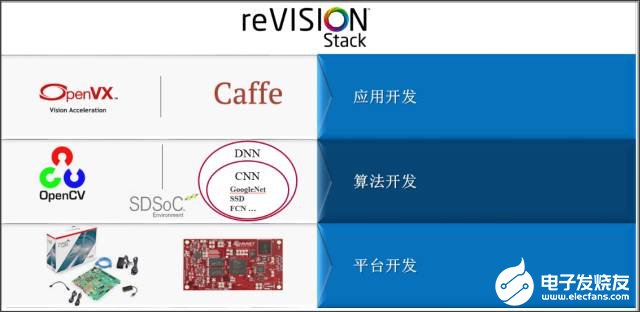
图7:赛灵思reVISION 堆栈
移除了通往广泛应用的障碍
reVISION 堆栈支持一大批广泛的设计团队无需深层的硬件专业技术,使用软件定义开发流程就能将机器学习和计算机算法的高效实现方案整合到响应迅速的系统中。
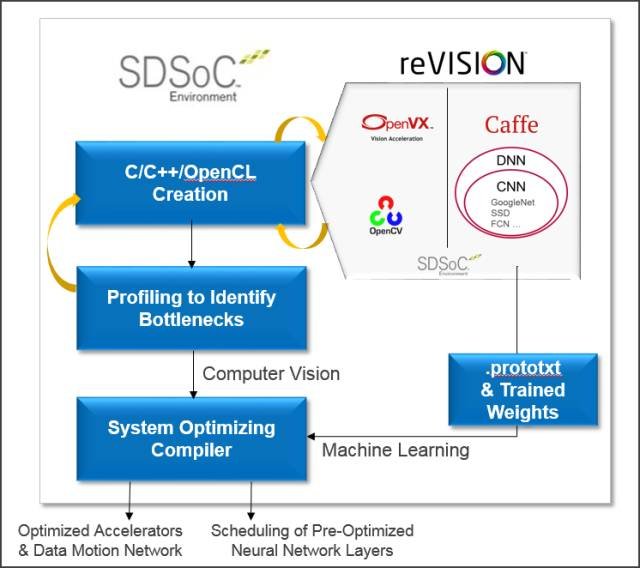
图8:reVISION 的软件定义设计流程
如图 8 所示,reVISION 开发流程从 熟悉的C、C++ 和/或 OpenCL 语言及相关编译器技术的基于 eclipse 的开发环境(即 SDSoC 开发环境)启动。在 SDSoC 环境中,软件工程师和系统工程师能以 reVISION 硬件平台为目标,并采用大量的加速就绪型计算机视觉库,很快还能采用OpenVX框架,从而快速构建应用。
对于机器学习,我们可用 Caffe 等流行的框架来培训神经网络,用 Caffe 生成的 .prototxt 文件对基于 ARM 的软件调度器进行配置,从而驱动专门为可编程逻辑预先优化的CNN 推断加速器。
对计算机视觉和其他专有算法来说,用户可对软件代码进行特征分析,发现瓶颈,并在代码中标出希望加速并进行“硬件优化”的特定功能。“系统优化编译器”则用来创建加速的实现方案,包括处理器/加速器接口(数据移动器)和软件驱动器。结合计算机视觉和机器学习功能,该编译器能创建优化的融合实现方案。
如图 9 左侧所示,专家级赛灵思用户采用传统 RTL 设计流程,与 ARM 软件开发人员合作,要花大量设计时间才能开发出高度差异化的机器学习和计算机视觉应用。
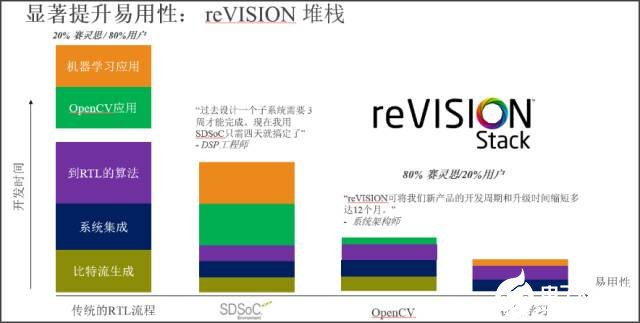
图9:reVISION 堆栈 —— 移除通往广泛应用的障碍
为进一步加快设计进程,减少对硬件专家的依赖,赛灵思大约在两年前推出了基于 C、C++ 和 OpenCL 语言的 SDSoC 开发环境。虽然这帮助其它上千名能够开发自己的基础平台、库和应用的用户大幅缩短了开发周期,但仍无法满足广泛机器学习应用推广与部署的要求,而且机器学习也带来了复杂问题。
如图 10 所示,赛灵思的全新 reVISION 堆栈使更多软件工程师和系统工程师无需掌握或只需掌握一点硬件设计专业技术,就能够更轻松快速地开发出智能嵌入式视觉系统,包括将机器学习和计算机视觉算法的超高效实现方案整合到高响应性系统中。

图10:赛灵思 reVISION 和 Nvidia Tegra X1 对比
从传感器到推断和控制的最快响应性
如上所述,软件定义的 reVISION 流程支持快速开发响应最快的系统。事实上,相比嵌入式 CPU 和典型 SoC 的性能参数,赛灵思的表现大大超越了英伟达 ( Nvidia) 这一强手。
将基于 Zynq SoC 的 reVISION流程与 Nvidia Tegra X1 进行基准对比可以看出,reVision流程讲机器学习的单位功耗图像捕获速度提升了6 倍,将计算机视觉处理的帧速率提升了 42 倍,而时延仅为 1/5(以毫秒为单位),这些数据对实时应用而言都是至关重要的。
如图 11 所示,拥有速度极快的确定性系统响应时间非常有用。我们从这个例子看到,一辆汽车采用赛灵思基于 Zynq SoC 的reVISION 与采用 Nvidia Tegra 的汽车一起识别潜在的碰撞事故并采取刹车,在速度为 65 mph 情况下,根据 Nvidia器件的具体实现方案,赛灵思的响应时间可以让汽车在5到33英尺的距离停下,从而轻松实现安全刹车,避免碰撞。
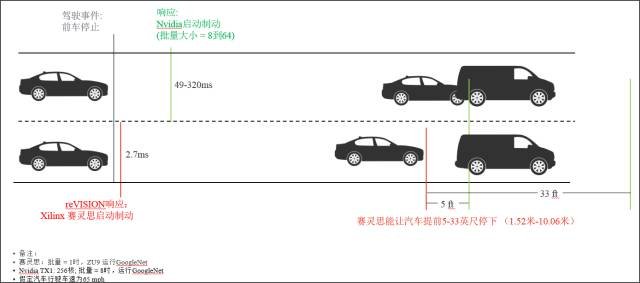
图11:响应时间为什么重要:赛灵思和 Nvidia Tegra X1 的对比
响应时间的的这些显著优点来源于Zynq SoC相对于嵌入式GPU和典型SoC的基本架构优势。 如图12所示,嵌入式GPU和典型SoC需要从传感器到视觉、机器学习和控制处理频繁访问外部存储器。 相比之下,Zynq SoC部署了使用可编程逻辑和显著多得多的内部存储器(高达Nvidia Tegra X1的19倍)实现的优化和流线型数据流。 这不仅实现了相对替代方案1/5的延迟,而且还实现了对于许多实时应用至关重要的确定性的响应能力。
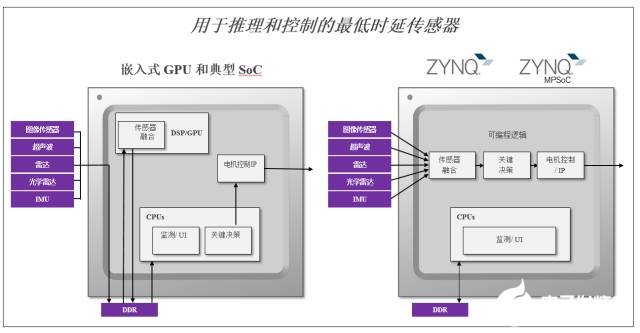
图12:赛灵思响应时间优势的来源
面向最新网络和传感器的可重配置性
响应时间很重要,而赛灵思解决方案还提供了非常独特的可重配置性优势。为了能够用尖端神经网络和机器学习推断效率部署最佳系统,工程师必须能够在整个产品的产品生命周期同时优化软硬件。如图 13 所示,机器学习领域最后两年的发展所带来的科技进步超越了过去 45 年的水平。许多新的神经网络随着新技术的出现不断发展,也大幅提高了的部署效率。不管今天制定什么标准,未来部署什么,都需要通过硬件可重配置性确保满足未来需求。只有赛灵思全可编程(All programmable)的器件才能提供这种级别的可重配置性。
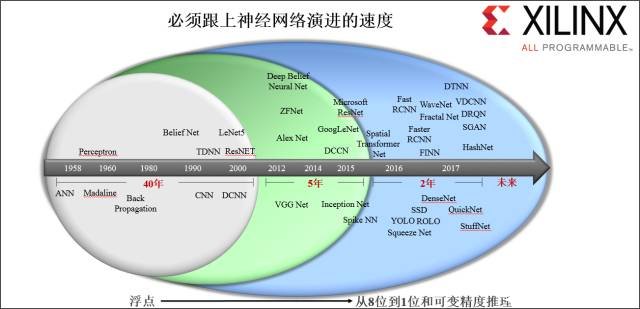
图13:随着机器学习技术的发展,为什么可重配置性非常重要?
如图14所示,对快速演进传感器技术的管理同样需要可重配置性。人工智能(AI)革命加速了传感器技术在不同领域的发展演进,也要求更高水平的传感器融合,以整合不同类型的传感器,以便在该环境了构建全面而完整的系统环境和对象视图。与机器学习类似,不管制定什么传感器配置标准、未来如何实现,都需要通过硬件可重配置性来满足未来需求。同样,只有赛灵思 All programmable 器件才能提供这种级别的可重配置性。
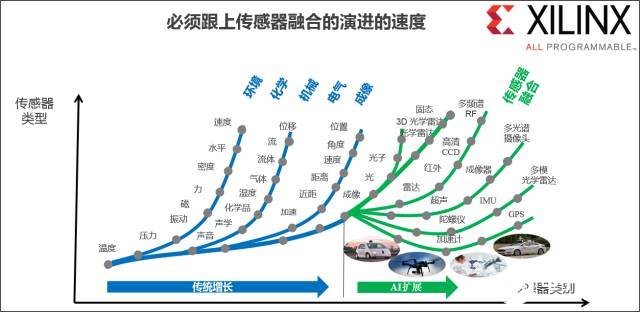
图14:为什么随着传感器的发展,可重配置性非常重要?
任意连接和传感器接口
如图 15 所示,基于 Zynq 的视觉平台提供了稳健可靠的任意连接能力和传感器接口优势。
Zynq 的传感器和连接性优势包括:
● 相对于目前市场中其它 SoC而言,带宽提升高达 12 倍,包括支持原生的 8K 和定制分辨率。
● 大幅增加了高低带宽传感器接口和通道,支持差异化传感器组合,包括RADAR、LiDAR、加速计和力扭矩传感器。
● 业界领先的最新数据传输和存储接口支持,为满足未来标准要求可方便地进行重新配置。
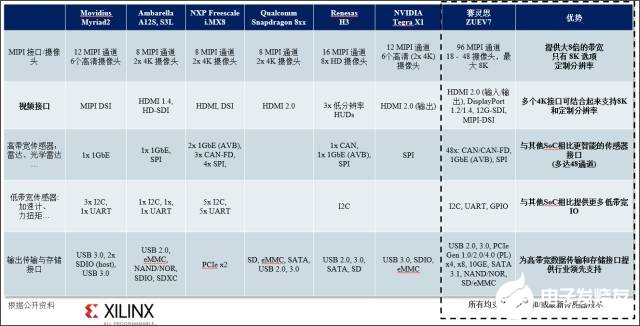
图 15: 传感器 &连接器 :Xilinx 与 Nvidia 和 典型SoC对比
与其它解决方案对比
通过将 Zynq 平台的独特优势和配备了各种库和业界标准框架支持的软件定义开发环境融为一体,reVISION 为视觉系统开发提供了最佳替代方案。如前所述,reVISION 的独特之处在于能实现智能应用的三大使命,以最新技术满足差异化和上市进程的重要要求,同时支持最快响应性、可重配置性、任意连接和软件定义编程。它同时还利用软件定义的编程模式移除了通往广泛应用的障碍。
如图 16 所示,在纵轴上只有 reVISION 能支持从传感器到机器学习推断和互联控制的优化,实现最佳系统响应时间。在横轴上,只有reVISION能为硬件优化的算法加速提供所需的可重配置性,并能升级更新到最新的传感器和连接性需求。虽然许多赛灵思器件客户的硬件专家已经能够实现这些优势,但是全新的reVISION堆栈通过使用行业标准库和框架实现软件定义的编程,消除了向更广泛应用的障碍。
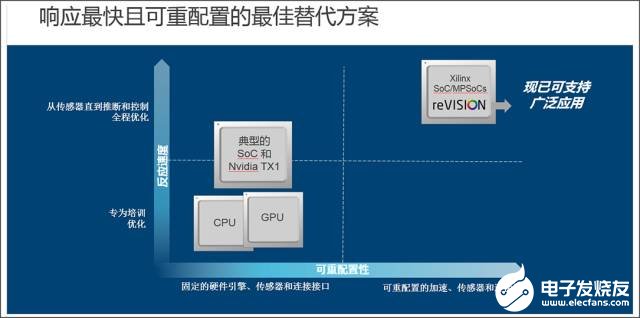
图16:赛灵思 —— 面向目标市场反应最快且可重配置的最佳选择
总结: reVISION
通过Xilinx reVISION™ 堆栈的推出, 赛灵思将技术扩展至广泛的视觉导向机器学习应用领域。reVISION™ 堆栈的推出进一步补充和完善了近期发布的可重配置加速堆栈,大幅扩展了赛灵思技术在机器学习应用领域从端到云的部署。全新的reVISION堆栈能够支持更广泛的很少甚至没有硬件专业知识的软件和系统工程师,使其可以更轻松、更快速地开发视觉导向的智能系统。一旦将机器学习、计算机视觉、传感器融合和连接的优势融为一体,这些工程师将从中大受裨益。
责任编辑:gt
-
赛灵思
+关注
关注
32文章
1794浏览量
130513 -
可编程
+关注
关注
2文章
759浏览量
39111 -
机器学习
+关注
关注
66文章
8116浏览量
130550
发布评论请先 登录
相关推荐
reVISION堆栈宣告Xilinx进入视觉导向机器学习终端市场





 工商网监
工商网监
评论