 在回归模型或分类模型中创建嵌套
在回归模型或分类模型中创建嵌套
如果您有一个稀疏分类变量(可以有多个可能的值的变量),将该变量嵌入到较低维度可能会非常有用。这种最广为人知的嵌入形式就是词嵌套(例如 word2vec 或 Glove 嵌套),即语言中的所有词汇都用一个包含约 50 个元素的向量表示。其理念是相似的词汇在 50 维空间中距离很近。您可以使用分类变量进行相同操作,即使用一个问题训练嵌套,然后再次使用该嵌套,而非对相关问题中的分类变量进行独热编码。嵌套的较低维度空间是连续的,所以该嵌套还可以充当聚类算法的输入 — 您可以找到分类变量的自然分组。
嵌套可以帮助您看到森林,而不仅仅是树木
要提供使用估算器训练的嵌套,您可以连同普通预测输出一起,发出分类变量的较低维度表征。嵌套权重保存在 SavedModel 中,并且有一个分享文件本身的选项。或者,您也可以为机器学习团队的客户端按需提供嵌套,这些客户端现在只是松散耦合到您选择的模型架构,所以这样可能更容易维护。每次有更新更好的版本替代您的模型时,客户端都会获得更新后的嵌套。
在本文中,我会向您展示如何:
在回归模型或分类模型中创建嵌套
以不同方法表示分类变量
使用特征列进行数学计算
分发嵌套及原始模型的输出
您可以在 GitHub 上找到本文中的完整代码,其中包含更多上下文。在这里,我只向您展示关键代码段。
用模型来预测自行车需求
我们来构建一个简单的需求预测模型,在已知星期几和当天是否下雨的前期下,预测自行车租赁站的租车数量。所需数据来自纽约市自行车租赁和NOAA 气象数据的公开数据集:
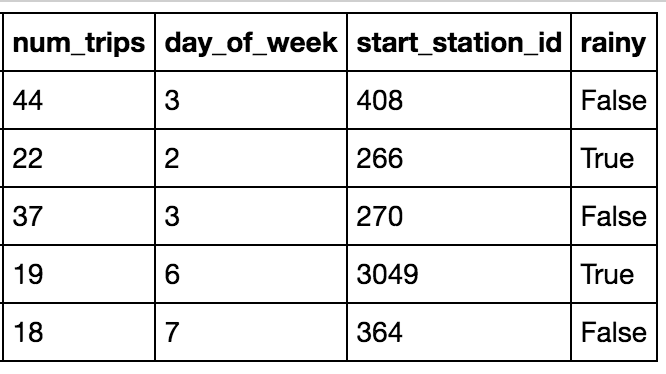
模型的输入如下:
星期几(1–7 的整数)
租赁站 ID(由于不知道完整词汇,这里我们使用哈希存储分区。该数据集有大约 650 个唯一值。我们会使用一个很大的哈希存储分区,但之后会将其嵌入到较低维度中)
是否下雨(真/假)
我们想要预测的标签为 num_trips。
我们可以通过在BigQuery中运行这个查询来创建数据集,从而加入自行车和天气数据集,并进行必要的聚合:
注:BigQuery 链接
https://cloud.google.com/bigquery/
1#standardsql
2WITH bicycle_rentals AS (
3SELECT
4COUNT(starttime) as num_trips,
5EXTRACT(DATE from starttime) as trip_date,
6MAX(EXTRACT(DAYOFWEEK from starttime)) as day_of_week,
7start_station_id
8FROM `bigquery-public-data.new_york.citibike_trips`
9GROUP BY trip_date, start_station_id
10),
11
12rainy_days AS
13(
14SELECT
15date,
16(MAX(prcp) > 5) AS rainy
17FROM (
18SELECT
19 wx.date AS date,
20IF (wx.element = 'PRCP', wx.value/10, NULL) AS prcp
21FROM
22`bigquery-public-data.ghcn_d.ghcnd_2016` AS wx
23WHERE
24wx.id = 'USW00094728'
25)
26GROUP BY
27 date
28 )
29
30SELECT
31num_trips,
32day_of_week,
33start_station_id,
34rainy
35FROM bicycle_rentals AS bk
36JOIN rainy_days AS wx
37ON wx.date = bk.trip_date
使用估算器编写模型
要编写模型,我们需要在 TensorFlow 中使用自定义估算器。虽然这只是一个线性模型,但我们不能使用 LinearRegressor,因为 LinearRegressor 会隐藏所有底层特征列运算。我们需要访问中间层输出(嵌套特征列的输出),这样我们就可以清晰地编写线性模型。
要使用自定义估算器,您需要编写一个模型函数,并将其传递给估算器构造函数:
1ef train_and_evaluate(output_dir, nsteps):
2estimator = tf.estimator.Estimator(
3model_fn = model_fn,
4model_dir = output_dir)
自定义估算器中的模型函数包括下列 5 个部分:
1.定义模型:
1def model_fn(features, labels, mode):
2# linear model
3station_col = tf.feature_column.categorical_column_with_hash_bucket('start_station_id', 5000, tf.int32)
4station_embed = tf.feature_column.embedding_column(station_col, 2) # embed dimension
5embed_layer = tf.feature_column.input_layer(features, station_embed) 6
7cat_cols = [
8tf.feature_column.categorical_column_with_identity('day_of_week', num_buckets = 8),
9tf.feature_column.categorical_column_with_vocabulary_list('rainy', ['false', 'true'])
10]
11cat_cols = [tf.feature_column.indicator_column(col) for col in cat_cols]
12other_inputs = tf.feature_column.input_layer(features, cat_cols)
13
14all_inputs = tf.concat([embed_layer, other_inputs], axis=1)
15predictions = tf.layers.dense(all_inputs, 1) # linear model
我们将选取租赁站列,并根据其哈希代码将其放入一个存储分区。使用这个技巧可以避免构建完整词汇。纽约只有大约 650 个自行车租赁站,所以拥有 5000 个哈希存储分区,我们就可以大大减少冲突的几率。然后,将租赁站 ID 嵌入到少数维度中,我们还会了解到哪些租赁站彼此相似,至少在雨天租车的情况下相似。最后,用二维向量表示每个租赁站的 ID。数字 2 控制较低维度空间代表分类变量中信息的准确程度。这里我随意选择了 2,但实际上,我们需要调节此超参数,以实现最佳性能。
其他两个分类列均使用其实际词汇创建,然后进行了独热编码(指示器列对数据进行了独热编码)。
这两组输入都经过级联,以创建一个宽输入层,然后通过一个输出节点传递到某个密集层。这样,您就在较低层级编写了一个线性模型。这相当于编写了一个 LinearRegressor,如下所示:
1station_embed =
2tf.feature_column.embedding_column(
tf.feature_column.categorical_column_with_hash_bucket('start_station_id', 5000, tf.int32), 2)
3feature_cols = [
4tf.feature_column.categorical_column_with_identity('day_of_week', num_buckets = 8),
5station_embed,
6tf.feature_column.categorical_column_with_vocabulary_list('rainy', ['false', 'true'])
7]
8estimator = tf.estimator.LinearRegressor(
9model_dir = output_dir,
10feature_columns = feature_cols)
请注意,LinearRegressor 会将 input_layer、indicator_column 等全部隐藏起来。但是,我想访问租赁站的嵌套,所以将其显示了出来。
2.使用回归模块设置估算器规范
对于回归问题,我们可以使用 Ftrl 优化器将均方误差最小化( LinearRegressor 默认使用此优化器,所以我也使用这个):
1my_head = tf.contrib.estimator.regression_head()
2spec = my_head.create_estimator_spec(
3features = features, mode = mode,
4labels = labels, logits = predictions,
5optimizer = tf.train.FtrlOptimizer(learning_rate = 0.1)
6)
3 — 4.创建输出字典
通常情况下,我们只会发送预测,但在这个例子中,我们想回送预测和嵌套:
1# 3. Create predictions
2predictions_dict = {
3"predicted": predictions,
4"station_embed": embed_layer
5}
6
7# 4. Create export outputs
8export_outputs = {
9"predict_export_outputs": tf.estimator.export.PredictOutput(outputs = predictions_dict)
10}
这里,我们使用自定义估算器的另一个原因在于它能够更改 export_outputs。
5.回送带有预测结果的 EstimatorSpec,并导出替换过的输出:
1# 5. Return EstimatorSpec
2return spec._replace(predictions = predictions_dict,
3export_outputs = export_outputs)
现在,我们照常训练模型。
调用预测
然后,可以使用TensorFlow Serving提供导出的模型,或者可以选择将其部署到Cloud ML Engine(实际是托管的 TF Serving),随后调用进行预测。您也可以使用gcloud调用本地模型(它可以针对此用途提供比saved_model_cli更方便的界面):
1EXPORTDIR=./model_trained/export/exporter/
2MODELDIR=$(ls $EXPORTDIR | tail -1)
3gcloud ml-engine local predict --model-dir=${EXPORTDIR}/${MODELDIR} --json-instances=./test.json
test.json 中有什么?
{“day_of_week”: 4, “start_station_id”: 435, “rainy”:“true”}
{“day_of_week”: 4, “start_station_id”: 521, “rainy”:“true”}
{“day_of_week”: 4, “start_station_id”: 3221, “rainy”:“true”}
{“day_of_week”: 4, “start_station_id”: 3237, “rainy”:“true”}
正如您看到的,我发送了 4 个实例,分别对应租赁站 435、521、3221 和 3237。
前面两个站位于曼哈顿,这一区域的租赁活动非常频繁(既为通勤族也为游客提供租赁服务)。后面两个站位于长岛,这个区域的自行车租赁并不普及(可能只在周末提供服务)。产生的输出包含预测的旅行数量(我们的标签)和租赁站的嵌套:

在本例中,嵌套的第一个维度在全部情况下几乎为零。所以,我们只需要一个维度嵌套。查看第二个维度,非常清楚地显示曼哈顿站有正值 (0.0081, 0.0011),而长岛站有负值 (-0.0025, -0.0031)。
这是我们单纯通过机器学习模型得到的信息,仅考察这两个地点在不同日期的自行车租赁情况!如果您的 TensorFlow 模型中有分类变量,可以试试从这些模型中分配嵌套。也许他们会带来新的数据分析!
-
数据集
+关注
关注
4文章
1178浏览量
24347 -
嵌套
+关注
关注
0文章
14浏览量
7800
原文标题:如何提供使用估算器训练的嵌套?
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
使用CUBEAI部署tflite模型到STM32F0中,模型创建失败怎么解决?
GPRS小区流量预测中时序模型的比较研究
Keras之ML~P:基于Keras中建立的回归预测的神经网络模型
Case-Control 关联分析模型
深度学习模型是如何创建的?
如何创建Proteus仿真模型
自回归滞后模型进行多变量时间序列预测案例分享
掌握logistic regression模型,有必要先了解线性回归模型和梯度下降法
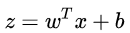
基于低秩表示的鲁棒线性回归模型
修补Edge Impulse为MCU创建图像、音频和运动分类模型






 工商网监
工商网监
评论