 张民:人工智能、自然语言和自然语言处理
张民:人工智能、自然语言和自然语言处理
7月28-29日,由中国人工智能学会和深圳市罗湖区人民政府共同主办,马上科普承办的“2018 中国人工智能大会(CCAI 2018)”完美收官。
大会第一天下午,苏州大学特聘教授、国家杰出青年科学基金获得者张民作题为《自然语言处理方法与应用》的主题讲座。与参会者共同分享自然语言处理方法,以及应用和进展。
以下是根据速记整理的大会讲座实录。
苏州大学特聘教授、国家杰出青年科学基金获得者张民
张民:感谢大会的邀请,使我有机会和大家分享自然语言处理方法,以及应用和进展。这也是给了我一个非常大的机会和动力,让我自己去总结、自己去深度挖掘、去想,做了这么多年,到底什么叫自然语言处理,有什么样的方法,都是怎样研究的,进展在哪里。更重要的是,用什么样的方法能和在座的各位进行交流和沟通。
大家听了很多次报告,这是其中一次,我在上面讲,用自然语言的方式把想讲的东西表达出来,大家在下面听。大家有没有仔细想过,你是怎样理解我讲的这些话,你学到了什么,你学完之后又采取了哪些动作,对你有哪些影响,这个过程就是一个很典型的自然语言处理过程。
我主要分四部分进行讲解。既然是人工智能大会,自然语言处理本身也是人工智能非常重要的分支,我用一点时间给大家介绍一下什么是人工智能、什么是自然语言、什么是自然语言处理。然后再介绍自然语言处理方法、应用,以及在人工智能时代自然语言处理的特点。最后给大家一个结论。
1.
人工智能、自然语言和自然语言处理
人类社会的发展是从农业社会到工业社会,到现在是信息社会。提到信息社会会想到信息爆炸,有各种各样的名词出现,比如我们现在处于大数据时代、信息时代,有数字经济,现在人工智能又这么热。大家有时是不是很迷惑,到底我们处于什么样的时代?其实所有这些从数据到信息、到知识、到智能都是信息时代的标志,它们之间到底有什么区别?数据是什么?信息是什么?知识是什么?智能是什么?
数据就是对事实的记录,对我们所看到的主观世界或客观世界事物的数量、属性、位置及其相互关系的抽象表示,以适合在这个领域中用人工或自然的方式进行保存、传递和处理。举个简单的例子,深圳今天的室外温度很热,37℃,数据是什么?数据就是气温,37℃。这就是一个数据,对深圳属性描述、气温、气压是多少。仅有数据得不到任何信息,如果我说气温-20℃,什么意思?大家不知道。
信息就是在数据基础上进行加工,能够传达你想听到的和我所讲的。你听到我讲的以后,就知道我讲的什么意思了。信息是具有时效性的有一定含义的、有逻辑的、经过加工处理的、对决策有价值的数据流,也就是加工后有逻辑的数据。还是用天气做例子, “2018年7月28日,中午,深圳的天气是37℃”,这就是一条信息。如果只说温度37℃,不知道什么意思。
知识是什么?小时候学的数学、化学、物理的定义和证明就是知识,知识就是在信息基础上进行抽象、凝练、总结、归纳、演绎,使其有价值的部分沉淀下来,可以结构化、传承、抽象,有价值的信息就转变成知识。
人工智能
什么叫智能?智能包括两部分,一部分是智,一部分是能;智就是智慧,能就是能力。用一句话总结,智能就是用知识来解决问题的能力。仅有数据不行,数据什么都不是;只有信息也不行,因为信息实在太丰富了;然后就必须要有知识;但有知识也不行,有知识必须要有能力;把知识运用起来,这时我们就把它叫做智能。这就是知识和智能关系。
现在人工智能已上升到国家发展战略,科技部、教育部、基金委、工信部和产业、科研机构、大学都在谈人工智能。从50年代、60年代、70年代到现在,会发现人工智能热时,大家喊人类要毁灭,人工智能要替代人类,说你要失业了。如果人工智能不火时,说是骗子,骗了国家、用户的钱,没帮助我们解决问题。但是冷静下来想,目前我们研究人工智能虽然取得了很大的进步,但是从人工智能的科学问题和智能的本质角度还差得很远。如果拿人的年龄作比喻,人工智能最多是一两岁。所以,第一,我们不是骗子;第二,人类也不会因为人工智能毁灭,还有很长的路要走。
中国人工智能学会理事长李德毅院士讲过一句话,他说,讲不清楚的人工智能内涵的人,都是在忽悠。李院士给人工智能下的定义(见图1),我非常认可。这个定义就是人工智能的内涵,包括脑认知基础、机器感知与模式识别、自然语言处理与理解和知识工程四部分。脑认知技术是基础,然后是知识工程。知识工程做什么?要做的就是怎样去把人类社会的知识用计算机表达出来,怎样数学化建模。人工智能最终体现两方面,一个是感知;一个是认知。语音识别和图像处理属于典型的感知问题;而自然语言处理和理解,是一个认知的过程。自然语言理解被认为是认知智能的核心难题。人工智能的外延是什么?按照李院士的定义来说,包括两部分,一个是机器人;一个是智能系统。机器人包括很多,如工业机器人、农业机器人和国防机器人等;智能系统也包括很多,如智能商务、智能制造和智慧金融等,这就是人工智能的外延。
图1 人工智能的内涵和外延(李德毅院士)
自然语言处理和理解
我们知道对一个智能生物体来讲主要包括感知、认知和进化三部分。进化在人工智能领域研究得非常少。图2示出了人的进化过程,左边是一只老虎,图上放了三个术语。第一点,人类经过了亿万年的进化,从食物链中端进化到食物链的顶端。这里不讲人类有没有控制世界、破坏世界(那是一个哲学问题),只是从生物链角度,我们站到食物链的顶端,享受人类世界的文明成果,可以作报告,可以谈论人工智能问题,可以谈论哲学问题,不用担心被老虎吃掉。但是,如果以人的能力,从一个人的角度来讲,肯定打不过老虎(除了武松之外)。第二点,大家都讲,脑的容量越大就越聪明。有时候我给女儿讲故事,我反问她,大脑容量越大越聪明对不对?她说,爸爸,你的脑容量大还是老虎脑容量大?我没研究过,估计老虎脑容量比较大(老虎大脑比人脑重约6倍),但是人比老虎聪明。为什么人类能够进化,处在食物链的顶端,和动物唯一的的区别就是有语言。人类通过语言进行沟通、合作,打不过老虎没关系,在地上挖一个坑,上面放一块肉,老虎咬那块肉肯定会掉下去,结果不言而喻。所以,语言非常重要,语言区别于人与动物。
图2 自然语言与人的进化过程
人工智能最核心的一部分就是自然语言处理和理解。
什么是语言?从计算机角度来讲,语言就是一个符号系统。一个符号系统有几个特点:
第一必须有字母、有词;
第二,必须有规则;
第三,必须有起始符号;
第四,必须有终止状态。
这就是语言的基本定义。
语言的种类
(1)动物语言
如果从语言种类来讲分为动物语言、人工语言和自然语言三种。动物语言和自然语言有什么区别?动物语言有几个特点,第一,只有声音,没有文字。第二,只有单词,最多表达20多种状态,这20多个单词不可以进行组合,而且动物语言表达状态都是最基本的、单一的,比如饿了、饱了、敌人来了、遇到危险了。第三,与生俱来的,不是后天学出来的。一只在中国的老虎和一只在美国的老虎从来没见过,它俩的语言可以交流;不像人,美国人和中国人从没见过,不可以用语言进行交流的。第四,动物语言和人不一样,不可以记录现实,也不可以对现在进行描述,也不能展望未来。从来没有老虎妈妈和老虎宝宝讲,将来怎样。
(2)人工语言
人工语言和动物语言与自然语言的区别。人工语言是由人创造的。首先人工语言目的是为了沟通;第二是一些非常有情怀的人做人工语言;第三,人工语言不像人类语言可以进行演变。一个代表性的例子就是世界语,由波兰人柴门霍夫发明的,在上世纪80年代非常流行。随着全球各国逐渐开放,世界语言不流行了,逐渐被英语取代。
人工语言发明的原因有多种,比如,人类之间交流、沟通使用;著作者爱好;艺术语言、文学作品的沟通……人工语言我比较推崇的,一个是《魔戒》作者创造的。还有就是《失落的帝国》中古代语言的亚特兰帝斯语。如果看过这部电影,会看到其导演费了很大的精力,请了历史学家、作家、语言学家坐在一起,为这部电影创造语言。你会发现这些人在讲的时候不是乱讲,是有规律的,而且可以进行沟通。
(3)自然语言
什么是自然语言?自然语言的定义、起源、种类和分布到底是什么?自然语言的定义非常多,大概有几十种定义,无论是做语言学的,还是做文学的,你会发现每种定义都是从某个侧面对自然语言某些特征的描述,都会有漏洞,都会有它描述不到的地方。到目前为止,还找不到一个大家公认的,一个科学的、能被广泛接受的自然语言定义。
自然语言的起源有几种说法。第一个是神授说。不同的宗教,对语言的起源给出不同的定义。比如,基督教认为是耶稣创造的;我国广西壮族自治区少数民族认为是山神创造的;印度教也有印度教的说法,认为是吠陀创造的。第二个是人创说。既然人讲自然语言,自然语言就是人创造出来的。在我国有一个非常标准的定义,即恩格斯说的定义,他说:语言是从劳动中并和劳动中一起产生的。不管理不理解,恩格斯讲的都是对的;但是他不是乱讲的,为什么说劳动创造语言?恩格斯在讲这句话之前先给三个条件:①人类的思维能力要发展到一定的水平;②人类要具备一定的生理条件;③人类社会有了产生语言的必要。满足这三个条件就可以创造语言,正好劳动满足三个条件,所以语言就是由劳动创造出来的。
自然语言的种类。目前世界存在语言6 909种,只有2 000多种语言有书面文字,2500种语言濒危。汉语、西班牙语、英语、阿拉伯语和印度语是世界上使用最多的;英、法、西、葡、荷兰语是世界上分布最广的;汉语国际化还不够。
自然语言处理
自然语言处理就是用计算机来处理人类的自然语言。那么,计算机怎样才能处理自然语言?都要做什么?
自然语言处理就做三件事情(见图3),把这三件事情做好了,可以获诺贝尔奖、图灵奖。
第一,分析和理解。什么叫分析和理解?就是我在上面讲,你听见了,如果你明白我讲什么了,在理解、思考我讲的什么,这个过程就是一个分析和理解的过程。
第二,生成和应用。什么叫生成和应用?我讲了之后,我们(人与人)进行对话、进行沟通,我讲了一句话你听懂反过来你要回答我,这就是一个互动和生成的过程。自然语言还有很多应用的过程。
第三,一个自然语言处理系统还要做一件事情,就是要有动作。比如对机器人讲:“给我倒一杯咖啡”;机器人听懂了,它说:“好的,主人,我给你倒一杯咖啡”。不要说好的,然后不动,这是不对的。
图3 自然语言处理系统
总之,自然语言处理方法目前可以概括四个方法:
第一,自然语言处理本身算法和理论。作为一门学科,它有自己的问题、规则和方法,要定义什么叫词法、句法、语义,以及其相应的分析算法。
第二,更抽象一点,从人工智能和机器学习角度讲,包括规则、统计、机器学习的方法和目前比较热深度学习的方法。再过几年之后,随着研究的深入,肯定会出现新方法取代深度学习。对这些方法抽象化,要解决自然语言处理时,要解决表示、推理和学习三个问题。表示什么意思?一个自然语言在计算机里怎样表达出来,语意、句话、篇章怎么表达。
第三,推理。
第四,学习过程。如图4所示。

图4 自然语言处理方法
自然语言分析、理解和生成,严格意义上讲这是自然语言处理最核心的两个问题。自然语言处理应用有两个层面,第一个是自然语言处理本身的直接应用;第二个是自然语言处理在行业的应用。本身的应用很多人都知道,比如问答、对话系统、机器翻译、自动文摘、机器写作等,这是自然语言处理本身的应用。自然语言处理在各行各业都可以得到应用,比如搜索、国际交流、教育、医疗、司法、金融,以及在公共安全、国防、旅游等行业应用。以教育为例就有很多,如对小孩的辅导和教学,无论学数学还是学英语,高考机器人等。
自然语言处理的历史,从广义理解,一直到秦朝、古希腊时代。真正的自然语言处理在计算机诞生之后,从1950年起就有了。为什么叫做forever?因为语言本身是人类区别于动物的一个标志,是最智能的行为,如果把语言研究透了,就可以解决人工智能一系列问题。这个问题只有人存在,只要对人本身没有研究透彻,这个问题就可以一直研究下去。
为什么在人工智能时代,自然语言处理这么热?
第一,技术取得了巨大进步,虽然离真正解决问题还差很远;
第二,产业落地的巨大需求。
以前我认为,自然语言处理技术没有成熟到达到产业需求的下限。目前自然语言处理在很多应用上已经达到产业需求的下限。有产业落地,就催生了技术需求,技术达到了产业落地的基本需求,反过来大大推动了技术进步。在人工智能时代,自然语言处理这么热是大势所趋。
机器能不能理解人类自然语言?举一个简单例子,我买件衣服是红色的,很高兴,所有人对这句话都能理解。但对计算机来说,它翻译成英文(见图5),这是今天早上的翻译结果,我测了很多机器翻译系统,几乎没有一句话对的。但是你问机器,谁是红色的?机器可能说衣服是红色的,也可能说我是红色的;如果问谁高兴,机器可能会想到我高兴、衣服高兴,甚至会想到红色高兴。翻译成英文的话,省略都要补齐。

图5 机器翻译示例1
另外一个例子。一天,小老虎看见一只猫在捉老虎,身手敏捷,羡慕极了。这是《老虎和猫学本领》中的一句话,非常简单。当给我女儿读故事书时,怕她不理解,经常问她,爸爸给你读完这个故事你听懂了吗?爸爸讲什么?你能讲一遍不?她最后都烦了,你为什么老问我这些问题?我说什么叫敏捷?什么叫羡慕?她想了想,不知道,然后她问我。我一想我也不知道,我怎么给小孩解释什么叫敏捷、什么叫羡慕。于是去Google图片搜索“敏捷”,有一只老虎跑来跑去;“羡慕”就用表情表达,我女儿就明白差不多了。但是这对机器来说有点“强人所难”。我又问我女儿,既然你和我说你理解了身手敏捷和羡慕极了,我问你,谁身手敏捷,谁羡慕谁?她一看问题比较难就乱讲了,一会说老鼠身手敏捷,一会又说猫、又说老虎。如果从机器角度来讲,她说的都没错。谁羡慕谁都可以?老鼠羡慕猫,我每天被你抓来抓去的,不过我辛辛苦苦偷了这么多东西还要被你吃;老虎羡慕猫,猫羡慕老虎都可以。从人的角度来讲没有任何问题,我们有很多常识,小孩没有,机器没有。我举这个例子不是说自然语言处理太难,机器做不了,我提醒大家不要太乐观,不要觉得人工智能发展,人类就要毁灭,远远达不到这个水平。
第三个例子,篮球放不进箱子里,太大了,太小了,形状不对。大家肯定知道,第一,篮球太大了,不可能箱子太大。但是问机器,机器就开始乱猜了。第二,太小了,形状不对,大家都能解决这些问题。但是机器必须要有知识库、要有推理、要有常识才能解决这个问题。再看机器翻译的结果,完全没有对这句话进行理解,“身手敏捷、羡慕极了”,从英文翻译来看,看不出任何修饰关系(见图6)。

图6 机器翻译示例2
这是被我抽象出来的例子,“我们班就一个女生,班上15个男生都喜欢她。B就问,那你喜欢她吗?回答说我们班有17位同学”。我到底喜欢还是不喜欢你?从正常角度讲是不喜欢的,只是很委婉地不想伤那个女生的自尊心或者不好意思回答。对机器来说不好回答,我女儿也没理解。我们很多问题隐含在语言、隐含在背后的推理和常识,这些逻辑关系非常抽象。
我们再看最后一个例子,这句话很有意思,这个题目是我女儿给我的。王师傅是卖鱼的,每公斤鱼进价48元,现38元一斤,顾客买了两公斤,给了王师傅200元假钱,王师傅没零钱,于是找了邻居换了200元。事后邻居存钱过程中发现钱是假的,被银行没收了,王师傅又赔了邻居200,请问王师傅一共亏了多少?对计算机来说,怎么明白进价、假钱的意思?这么简单例子,可以看出自然语言处理中常识和知识的重要性。
自然语言处理为什么这么难?下面从功能、知识、特点、语用性等方面阐述(见图7)。第一,语言是对世界的认识,是对客观、主观世界所有能够看到的东西、想到的东西的描述。第二,自然语言处理主要是基于语言学知识,除了自然语言知识还有外部世界知识、领域知识、常识知识。第三,自然语言组合性、开放性、动态性。还有一个非常重要的特点,是语用性。除了知识之外,对自然语言处理要解决另外一个最重要的问题,就是语言是有特点和环境的,尤其在对话过程中是有上下文、有信息、有意图的。

图7 自然语言处理为什么这么难?
2.
自然语言处理方法
学科的内涵和外延
自然语言处理方法到底是什么?首先要定义如图1所示的学科内涵、外延和边界。自然语言处理三件事,即分析理解、生成和应用、动作。内涵是分析理解和生成;多语言处理、跨语言和单语言理解有不同特点,我把多语言处理也作为自然语言处理学科内涵,包括对词法分析、句法分析、语意分析和篇章分析。自然语言生成从内部表示生成自然语言的表达。多语言处理就是语言之间的对齐和转换。这就是自然语言处理学科内涵问题,也就是“听得懂、讲明白”。学科外延有机器翻译、文本分类、信息检索、机器对答等自然语言本身的直接应用和自然语言处理加行业(见图8)。下面对内涵和外延所要解决的问题,给大家解释一下。

图8 自然语言处理的外延(应用)
分词
第一是分词,意思是人听一句话之后理解的是以词为单位,而不是以句子为单位。计算机要解决第一个问题就是分词。举个例子,“严守一把手机关了”有非常多歧义,一把手、机关都是词,这里只有一个正确分词结果就是“严守一/把/手机/关了”。自然语言处理解决第一个问题就是分词,目前我们把它叫做序列标注方法。
一个图
B是开始,I是中间,E是结束,S是单个;B又是开始,E又是结束;“关”是单独,“了”也是单独。这个字到底是一个词的开始还是一个词的中间,还是一个词的结束,还是这个字本身就是单独的。这就是目前分词所用到的数学模型。目前主要包括两种方法,第一种是基于离散特征的CRF;第二种是神经网络的方法。
自然语言分词挑战有五个。
第一,交叉歧义、分真歧义和伪歧义,如乒乓球拍卖完了,这就是一个真歧义。
第二,新词不断涌现。
第三,领域移植问题,如在新闻领域做得非常好,如果放在法律领域、医疗领域就不一样。
第四,数据融合问题。到底什么是词?不同人有不同鉴别。现在有各种各样的语料,分词标准不同,在理解这些问题时怎么样进行标注和融合?
第五,粒度不同的问题。
分词进展包括四个方面。
第一,深度学习方法,使分词定义有了进一步提高。
第二,网络文本分词数据的人工标注,这是由于在互联网时代,尤其互联网公司产生了巨大的需求,对网络文本分词有了进展。
第三,多源异构数据的融合和利用。第四,多粒度分词。
如图9所示,第一个句子“特别是我国经济下滑”,在CTB,“特别是”做一个词,如果在PD描述,把“特别是”分开,“我国”也是。第二个是“全国各地医学界专家走出人民大会堂”,可以看到两个分词标准完全不同。统计表明,90%词一致性都做不到,这是一个很大的问题。还有分词的粒度问题,不同人对词语认知不同,包括生活环境、体系不同。还有汉语语素和合成词的界限很模糊,这也是一个问题。在1996年,Sproat教授一个实验结果表明,中文的native speaker分词一致率仅76%。
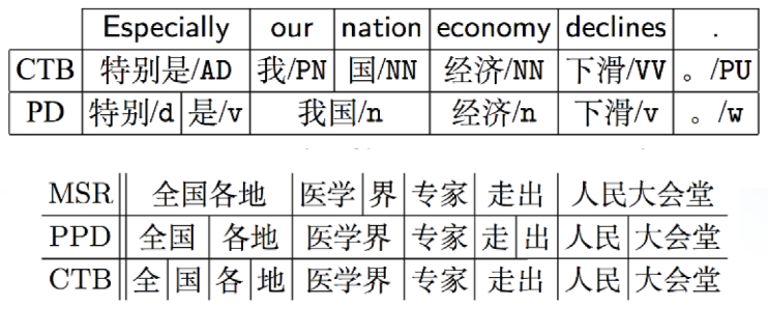
图9 分词的粒度
粗粒度分词和细粒度分词有不同的需求。以前一个互联网公司高层人员说,分词不需要做了,我们每天有这么多数据,每天新词都能发现,每天分词结果都很准确。于是让我的学生给他一些文章,测一下其分词结果怎样?结果可想而知。所以分词的问题从这里可以看出,远没有解决。
如何能够在多源异构数据中学习?我们现在用的分词系统还是机器协同的系统,有了这么多异构数据,怎样能够学出好的分词模型,这也是目前研究的热点。多粒度分词也是这样,不像最开始讲的,把分词看成线性序列问题,现在把分词做成一棵树,树的任何一个节点都可以看作是一个词。如图9所示,如果医学界在图中1这个节点,医学就是一个词;如果在图中2这个节点,医学界就是一个词。这是目前研究比较有意思的现象,我们叫做多粒度分词。
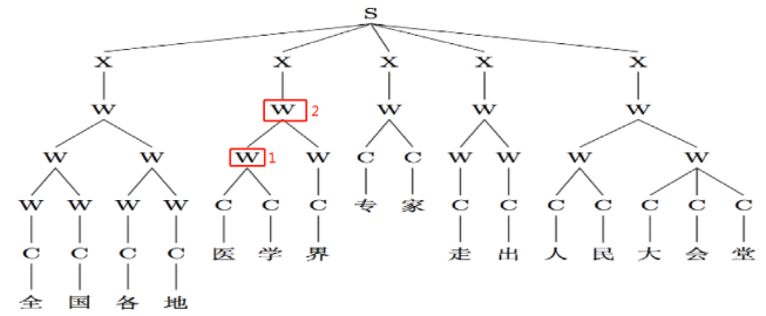
图10 基于树结构的多粒度分词示例
命名实体
在多源数据融合,研究的都是基于模糊标注的耦合序列学习,还有基于树结构的多粒度分词。作为自然语言处理要解决第一个问题就是分词问题,第二个问题就是命名实体识别问题。“周润发出生香港南丫岛,籍贯广东开平”,这里有很多命名实体(见图11)。命名实体就是指人名、地名、组织机构名、产品名和时间等;还有很多专有名词,我们也叫做命名实体。比如,昆虫的名字在生物学界就是很难解决的问题。据说在英文里,昆虫的种类大概有几百万种,如为每一只昆虫命名是很难的问题。如图10所示就出现了非常多的命名实体。

图11 命名实体示例
要解决第二个问题,怎样能够把命名实体识别出来。
命名实体识别方法有两种:
第一,规则系统;第二,基于机器学习的学习系统。
研究难点包括三个方面:
第一,新领域旧实体类别识别。在新的领域里面,实体没有变过,但是领域发生变化;第二,新实体新类别,以前没有这个类别,现在出现新的类别怎么样定义、发现出来;第三,方法,这是目前研究的热点和难点。
句法分析
有了分词、命名实体,下一步要做的就是句法分析。句法分析要研究的问题就是,从结构的角度,这些词为什么能够组成一个句子?就是说,在这个句子内部,这些词到底有什么关系?这里以依存句法分析为例(见图12)。输入是一个句子的词系列,输出的是依存关系句法树。这些对应关系我们能够知道的,或者以前学过的,比如主、谓、宾、定、状、补。这是目前在学术界或者工业界常用的句法树库,第一个是格位语法;第二个是短语结构文法;第三个是依存语法。
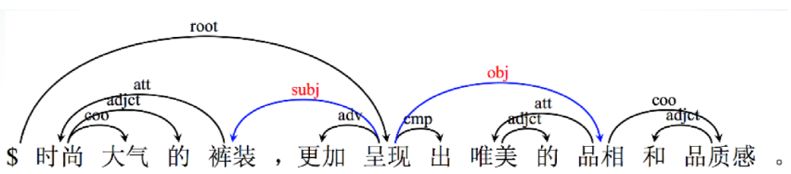
图12 依存句法分析示例
表1所示的这些句法树之间,由于不同的人后面有不同的学术背景和认知背景,都是不完全兼容的。
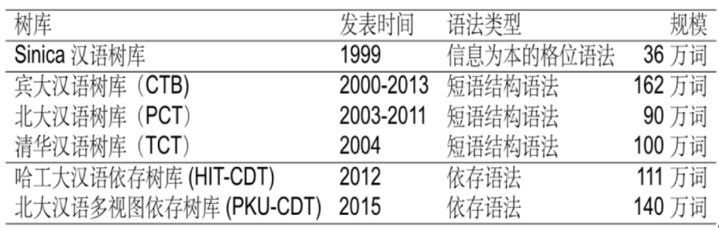
表1句法树库
句法分析方法有两种:
第一,图的方法;
第二是转移方法。
从全图里,怎样能找到子图。基于转移的方法是状态的转移,每个状态代表了N个结构里的公共部分。状态的方法叫做移进规约的方法。这是句法分析的性能,从图13可以看到性能进步非常快,尤其在2016和2017年。2016年Google提出了基于深度学习的转移句法分析方法,2017年斯坦福提出了基于深度学习的图分析方法, 所以目前有近10%的性能进步。英文比中文性能高8%~10%;英文句法分析如果在学术界里标准测试题达到90%~95%,中文86%的水平。
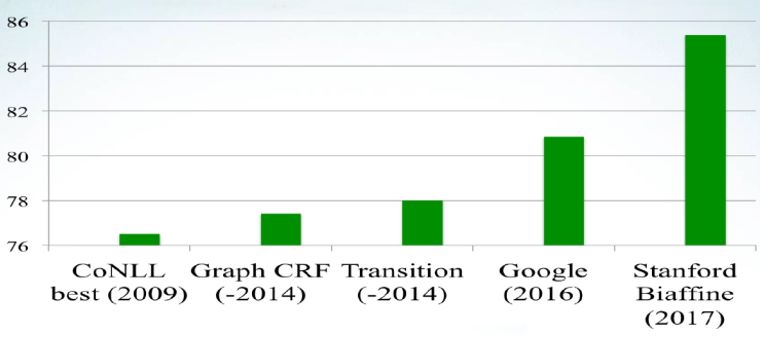
图13 句法分析性能
句法分析的难点有两个:
第一,处理网络文本时准确率急剧下降5%~10%,我们和企业合作时也发现了这个问题。不仅句法分析有这个问题,同样分词也有这样的问题,分词可以下降到20%。
第二,语义知识和外部知识的利用。
研究热点包括两部分:
第一,资源构建,局部标注的主动学习和树库转换。树库标准、规范不一样,而且要在企业标新的树库出来,怎样把树库转换成标准格式,从而能充分利用起来?
第二,知识驱动的句法分析。
到目前为止分享了分词、命名实体,还有句法分析。下一步进入语义分析,输入是自然语言的句子,输出是自然语言句子含义的结构化和机器可读的表示。语义不像句法,句法有标准的表达形式,在语义层面还没有形成一个大家公认的、可计算的、深层次的、能够在计算机里面可用的,在学术界得到充分认可的表达。不同的应用语义表达方法也不一样,分析方法也不一样。
语义表达有三种:
第一,浅层语义分析,回答谁做了什么,什么时候做的,为什么这么做,怎么做的。
第二,逻辑语义分析,是基于逻辑表达式的分析。
第三,抽象语义表示是南加州大学提出的ARM。
方法分三种:
第一,基于同步上下文无关文法。
第二,基于组合范畴语法。
第三,在上述两种方法加了神经网络的,基于神经网络序列到序列方法。
语义分析性能以ARM为例子,1-10个词率达到75%,这是稍微简单一点的;如果句子长一些,30、40、50个词,性能则急剧下降。这是目前语义分析的性能现状。
篇章分析
到目前为止我们讨论了分词、实体、句法、语义,下面看一下篇章的分析。篇章是什么?“比尔来自美国,今天交通非常拥挤。长江贯穿中国多个省市。因此,自然语言处理是计算机科学与语言学的融合。”读完这句话以后,发现每句话都没错,拿出其中任何一句话都觉得是有意义的,但是放在一起,觉得这个人语无伦次了,逻辑有问题。第二句话,“这里交通非常拥挤,张先生早上6:40之前就得出发。常常会提前半个小时到办公室;如果稍晚一点,他很可能会迟到。”同样一句话,第一句话比第二句话讲得还冠冕堂皇,好像文风更好,但是第一句话表达不出任何意思,第二句话就表达了完整的意义。篇章是做什么?为什么三个句子、四个句能够按照一定顺序讲,为什么不颠倒过来?这些句子到底有什么关系?篇章就是解决这些问题的。人在理解自然语言时是以篇章为单位,不能断章取义就是这个意思。
这是学术界老前辈宋柔老先生的例子,《围城》里有一句话:“高松年发奋办公,夙夜匪懈,精明得真是睡觉还睁着眼睛,戴着眼睛,做梦都不含糊的。摇篮也挑选得很好,在平成县乡下一个本地财主家的花园里,面溪背山。” 一个逗号到底,中间有一个句号。读完虽然有点绕口,基本上能明白它意思。但是这些句子和句子的关系非常复杂,它们到底有什么关系?“带着眼镜和睁着眼睛”之间有并列关系,从计算机角度一定要明确;“做梦都不含糊”,做梦和睡觉也是并列关系。。
看另外一个例子。“如果你不出面干预,他即使把设备卖了,也没人组织得了他。”这里隐含什么关系?转折关系、因果关系或者假设关系。这些关系如果分析不清楚,自然语言处理应用,比如理解、问答、对话都做不了。
篇章分析到底要做什么?其实就是要解决两个问题,一个是篇章结构;还有一个是篇章特征。篇章结构包括刚才看到的逻辑语义结构、话题结构、指代结构、功能结构和事件结构等。除了功能结构之外,其他几个结构目前在自然语言处理都有所研究(都是非常难的问题)。篇章的基本特征包括衔接性、连贯性、意图性、可接受性、信息性、情景性和跨篇章性七个,目前学术界研究最多的还是衔接性和连贯性。衔接性指的是你在一段话或在一篇文章里讲这个词时,主题基本上都会用一个词、用同样的词,不会跳来跳去,不会发生很大变化,这就叫做词汇链的概念。连贯性指的是结构。
篇章分析语言学理论有中心理论、脉络理论、篇章表示理论等,我们统称叫做修辞结构理论(RST)。RST对从事计算机语言的人影响非常大。目前最大的中英文篇章标注树库基本上都是基于RST,在它的基础上进行小幅度改进所标注。这些篇章分析的库,我们叫做篇章树库。
篇章分析的目标就是分析篇章所蕴含的各种结构,以及构成单元之间的各种语义关系。其任务:
第一,识别篇章基本单元;
第二,识别这些单元之间的篇章关系。
篇章分析有三种方法:
第一种是线性;
第二种是组块方法;
第三种是树结构方法。
篇章里一直在讲修辞结构,到底有什么用?
第一个修辞结构。“张三才30出头,既没有什么学历,又没有多少新的工作经验,但是不论干什么,他都非常认真,所以处长总是把一些重要的任务交给他。”这句话跳来跳去。问的问题是,为什么处长总把一些重要任务交给他?如果篇章分析做不好,这个问题没法回答,只有在篇章分析基础上,我们回答,最终原因是,他不论干什么,都非常认真,所以处长才把任务交给他。
第二个话题结构。“我昨天上街看见一个人,长得很魁梧,穿着军大衣,买了两斤肉。”这句话比较通俗。问题是谁买了两斤肉?无外乎就是两个答案,一个是我;一个是看见的那个人。如果篇章分析不出来,完全给不出答案,所以篇章非常重要。
自然语言生成
分词、命名实体为代表的词法、句法、语义、篇章这是分析和理解层次,它们是自然语言处理或者自然语言理解必须要解决、要做的事情,这是最核心的科学问题;此外还有生成。
自然语言生成和分析比起来,研究差得很多。
造成这种情况的原因无外乎两点:
第一,生成是基于分析的,如果分析做不好,生成也很难做好;
第二,以前产业界对生成没有很大的需求,尤其是近三年或者近五年,随着人机对话、问答,对生成的要求越来越高。
2000—2005年在国际会议上举办一个自然语言生成的比赛没有人参加,但现在自然语言生成变得尤其重要。一个系统要做人机交互,要把自己的想法用自然语言表达出来,表达得好坏直接决定用户体验,生成就变得非常有用。自然语言生成有基于规则方法、基于知识库检索方法和基于深度学习的方法。
到此为止,对自然语言处理方法介绍了词法、句法、语义和篇章,在生成这个层次介绍了生成的所采用的不同的方法。
3.
自然语言处理应用
自然语言处理应用包括两方面,第一方面是自然语言处理本身应用;第二方面是自然语言处理+行业。下面介绍几个代表性的自然语言处理应用。
情绪和情感分析
情感和情绪不同。
情感分析主要对产品评论和新闻文本表达的意见、情感、情绪、主客观性、评价等方面的研究。情感分析在工业界和学术界已经有着广泛的应用,比如舆情监测,我国做得非常好;还有企业征信、聊天服务机器人等做得也好。情感包括正面、负面和中性三个方面。如图14所示,“这部电影情节还不错,我很喜欢,但是这家影院的3D效果太烂,以后不会再来了。”如果在句子层面,这个层面是正面;句子二是负面;既有正面也有负面,综合评价是负面,他不会再来。

图14 情感分析示例
情感非常重要。学术界一般做情感分析都是做一个句子或者一篇文章,在我们和某电商公司合作之后,发现了很多在学术界所看不到的问题。在电商领域有很多用户,用户和用户之间、用户和客服之间进行交流,产生了很多新的科学问题和应用场景,比如基于问答的情感分析,以及基于单产品、单一问答多用户的情感分析。这些问题都是在实际中电商公司必须解决的,都是学术界没有意识到的问题,没有数据,没有要求,也没有科学问题的驱动,但是企业界有这样需求,一归纳就发现了很多的科学问题和实际应用。
情绪就是喜怒哀惊,难过、新奇、愤怒等。比如,“今天学发了国家奖学金太开心了。明天就去买个LV包包。”这个情绪第一个是太开心;,第二个产生的结果就是买个LV包包,这就是情绪分析。模型从机器角度来讲,各个方法都有。问题驱动是做自然语言处理更感兴趣的,那就是情感和情绪分析到底要哪些解决问题。然后分析完之后又挨个做一遍。
问答系统
自然语言处理应用,第一个就是情感和情绪;第二个是问答。问答也非常有意思,问答输入自然语言句子,输出是精准答案。但是很多情况下给不出一个精准答案,很多答案是主观的,或者很多答案你认为正确,但是不敢说、不能说。问答任务分为社区问答、基于知识的问答、垂直领域问答、开放领域问答、阅读理解等。
问答的分类也有很多种。事实类,2018中国人工智能大会在哪里召开?深圳。描述性问答,这款新发布的手机有什么特点?过程性问答,护照怎么申请办理?需要计算的问答,飞巴黎和飞洛杉矶最短的时间差多少?这相对难一些,要找到飞巴黎和飞洛杉矶的时间,然后互相减掉。很多小学应用题里蕴含很多对自然语言处理很难,以及很多推理、常识性又是可计算性的东西。推理因果关系,为什么中国会发生疫苗事件?这个答案不唯一,政府发言人是一个,敌对势力是一个,受害小孩家长也是一个,愤青是一个。观点性问答,你对疫苗事件和中美贸易战有何看法?二者有关系吗?如果让小冰回答,小冰估计会说“跟我没关系,我不告诉你”,这也是一种回答。
问答分类分析和理解分为一阶和二阶,一阶比较简单,比如喜马拉雅山有多高?二阶问答,比如《红楼梦》作者还写过哪些书?还有更复杂的,经常用的例子,谢霆峰前妻的什么之类,绕了很多圈最后又绕到谢霆峰这里,推理得非常翔实。这也是一阶、二阶逻辑。第二就是要做好问题分类、分析和理解,要做好答案的匹配和检索。第三个是答案生成。要看问题是什么,归归类,作者意图是什么。答案匹配和检索,既然把问题分好了,总要找到答案,无论是知识库、社区还是互联网要匹配和检索出来。答案生成可能涉及到推理、涉及到知识图谱、组合、指代等很多东西,一个问答系统需要做好这三个模块。
问答发展历史和人工智能历史是一样的。现在测试人工智能要进行图灵测试,这就是一个问答系统;后面有TREC、IBM沃森、社区问答、看图说话等。
问答有四个难点:
第一,多源异构大数据背景下开放域问答瓶颈;
第二,语义理解问题;
第三,知识库与知识图谱问题;
第四,多模态场景下的问答(就是常说的看图说话)。
研究方法:
第一,针对多源异构大数据以前用IR方法,目前就是IR+阅读理解的方法。
第二,深度理解主要抽取的方法,现在抽取+生成的方法。生成是问答非常重要的一环,目前生成式问答已经成为主流。
第三,知识图谱以后专门介绍。
第四,多模态场景下的问答,最有趣的地方是要把语言学用的模型和图像处理模型在一个框架下统一起来;也就是说,要跨媒体、跨模态的特征共享、独立和抗依赖。
问答系统有什么样的应用?图15是在网上找到人工智能行业图谱,发现每个领域只要涉及人机交互都可以用到问答。
图15 人工智能行业图谱
对话系统
对话系统不像问答系统这么单纯,一个是开放域对话系统;一个是封闭域对话系统,或者面向任务驱动的对话系统。比如银行、客服、旅游就是封闭域对话系统。开放就是随便问、随便答。开放域对话系统分两种,一种是闲聊;一种是解决问题。对话系统是综合性问题,主要涉及语言识别、语言理解、状态跟踪、自然语言生成和语音合成。
知识图谱
图16所示的是我们和某电商公司做的一个计划,叫做藏经阁计划,是在国内几所科研机构、大学在某电商公司支持下共同打造的。
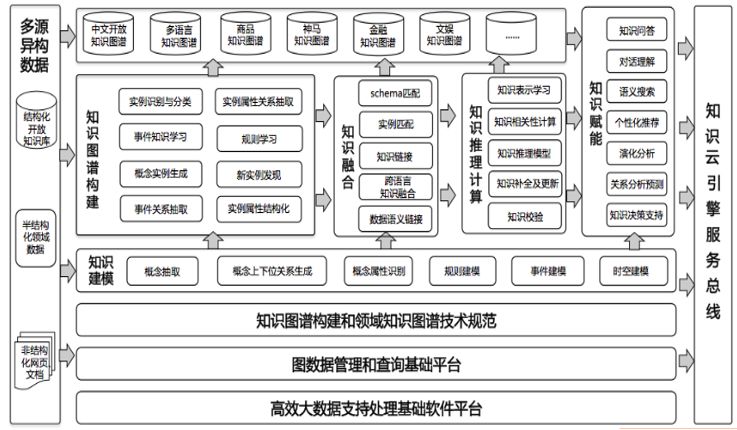
图16 藏经阁计划(知识图谱)
第一个图谱知识建模,就是人工智能内涵里很重要的部分知识工程。知识工程一个非常核心的部分叫做知识建模。如果问你,什么叫知识?大家回答不出来。经常说,你有知识没文化;有知识没能力,你是一个书呆子。知识建模就是要解决这些问题。我们每天都在讲这些东西,怎么能用计算机表达出来?是用图的表达还是用树的表达?属性是什么?这就是知识建模。有了建模之后,要进行图谱的构建。图谱包括很多,目前先讲的都是实体之间的关系,再讲实体的属性。图谱非常多,不仅有属性。比如,某搜索公司做用户意图图谱,某电商公司做用户购买力图谱,还可以做事件图谱。有了知识建模,有了知识图谱构建之外,下面要做的就是知识的融合。有各种各样的图谱,有各种各样的知识;化学第一章学的是有机化学,下一章是无机化学,怎么样把知识融合起来?这就是知识融合解决的问题。还有知识推理和计算。有了知识和图谱这些静态的东西,如果利用起来,必须要有推理、要有计算的过程;有了推理和计算之后要赋能,人很会造词。以前对赋能这个词很反感,听时间长了,慢慢也接受了。因为英文不是你的母语,没有文化认同感,没有主人感,如果有一个新词就会很容易接受;但是中文出了一个新词,会思考这样有没有道理。
信息抽取
信息抽取做了几件事情,第一,命名实体;第二个叫做mention,是指代的意思;还有关系,比如北大和清华有什么关系;还有事件的关系,比如讲破案过程,肯定是先发生案件,然后被人发现了,警察去了开始搜集线索,最后破案了,这就是事件的关系。
举个例子,什么叫信息抽取?图17所示的这段话很长,看起来是不是很费力气?如果用图18所示的表格表示则非常简单,一看就明白了。信息抽取要做什么?信息抽取基本的任务就是要把那段话变成这种结构化的表达;也就是说,信息抽取就是要把非结构化数据、自然语言数据变成结构化数据,或者非结构化、或者半结构化数据变成结构化数据。

图17 非结构化数据

图18 结构化数据 (信息抽取的结果)
机器翻译
机器翻译有基于词典的方法、基于规则转换的方法、基于中间语言的方法、基于实例的方法、基于统计的方法和基于神经网络的方法。举个例子看看机器怎样做机器翻译(见图19),输入是“我们必须与友邦建立一种关系”。这个短语可以随便划分,我们必须与友邦建立关系。第二步是做短语翻译,第一步先做短语切分,再做短语的翻译;第三步做短语的转化,翻译结果就出来了。这是短语结构的机器翻译,非常简单。
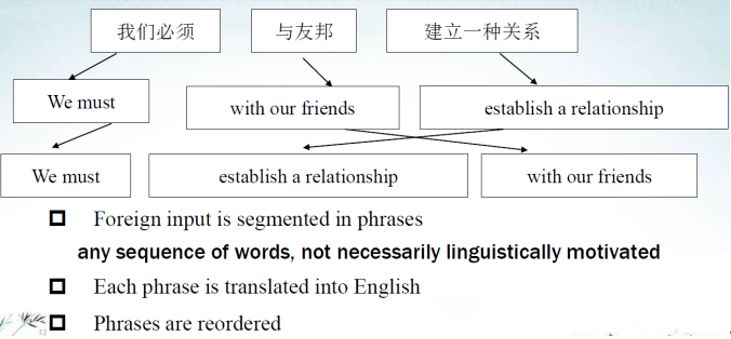
图19 短语结构的机器翻译
目前用的神经网络方法也非常简单(图20)。首先把句子进行切分,然后从左向右扫描一遍,再从右向左扫描一遍,扫描过程用的循环神经网络。扫描后这个句子形成一个向量,有了向量就产生了目标源的词,从左向右一个个产生。产生词时要用到两个条件,一个是状态序列;另一个就是当前词和源语言每个词的attention。神经网络方法比短语方法更简单,先是从左向右,然后是从右向左两边扫描,这是编码过程;然后是从左向右解码。
图20 神经网络方法的机器翻译
目前最新进展是Google提出的Transformer方法,在大规模语料上比之前SMT提高了10个点。Transformer只需要一个叫做attention的东西,第一词本身;第二词的位置;第三个是词与词之间的attention进行编码。
机器翻译的挑战:第一是知识建模和翻译引擎,从句法到语义到知识,没有知识就没有智能。第二,广度和深度,广度就是篇章,深度就是深度学习。第三,面向产业化需求,满足国家重大需求。
上面讲了自然语言处理方法和自然语言处理应用,最后的自然语言处理+行业,从目前的发展来看,自然语言处理在各行各业有非常大的需求。
4.
AI时代自然语言处理
AI时代自然语言处理有什么特点?第一非常热;第二取得巨大进步。技术进步和产业需求推动了行业的发展。特点包括表示、搜索、推理和学习三个方面。学习有各种各样的学习方法,多任务学习、对抗学习、迁移学习等,这些都是自然语言处理发生的新框架(见图21)。
图21 AI时代自然语言处理的特点
最后简单介绍苏州大学的自然语言处理。我们目前有200多人的自然语言处理团队,做了30年的自然语言处理研究,前面讲的东西,在我们苏州大学自然语言处理实验室都在做(见图22)。
图22 苏州大学自然语言处理的研究
5.
总结
第一,自然语言处理发展正处于历史的最好时期,并取得了很大进步。最重要的原因是技术的进步达到了产业需求的下限,产业的巨大需求反过来推动了技术的进步。
第二,AI时代自然语言处理发展趋势,一个是知识;一个是学习。
第三,学科自身发展和边界,要凝练自然语言处理本身的科学问题,研究框架和规范。
第四,加快产学研的进一步融合。
-
人工智能
+关注
关注
1776文章
43796浏览量
230567 -
自然语言
+关注
关注
1文章
269浏览量
13201
原文标题:CCAI2018演讲实录丨张民:自然语言处理方法与应用
文章出处:【微信号:CAAI-1981,微信公众号:中国人工智能学会】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论