 DeepMind为视觉问题回答提出了一种新的硬注意力机制
DeepMind为视觉问题回答提出了一种新的硬注意力机制
DeepMind为视觉问题回答提出了一种新的硬注意力机制,它只保留了回答问题所需的少量视觉特征。减少需要处理的特征使得能够训练更大的关系模型,并在CLEVR上实现98.8%的准确率。
视觉注意力在许多方面都有助于人类的复杂视觉推理。例如,如果想要在一群人中认出一只狗的主人,人的视觉系统会自适应地分配更多的计算资源来处理与狗和可能的主人相关联的视觉信息,而非场景中的其他信息。感知效果是非常明显的,然而,注意力机制并不是计算机视觉领域的变革性力量,这可能是因为许多标准的计算机视觉任务,比如检测、分割和分类,都没有涉及有助于强化注意力机制的复杂推理。
要回答关于特定图像的细节问题,这种任务就需要更复杂的推理模式。最近,用于解决视觉问答(Visual QA)任务的计算机视觉方法出现了迅速发展。成功的Visual QA架构必须能够处理多个目标及其之间的复杂关系,同时还要整合丰富的背景知识,注意力已成为一种实现优秀性能的、有前途的计算机视觉方面的策略。
我们发现,计算机视觉和机器学习中的注意力机制存在很大的区别,即软注意力(soft attention)和硬注意力(hard attention)。现有的注意力模型主要是基于soft attention的,所有信息在被聚合之前会以自适应的方式进行重新加权。这样可以分离出重要信息,并避免这些信息受到不重要信息的干扰,从而提高准确性。随着不同信息之间相互作用的复杂度的降低,学习就变得越有效。
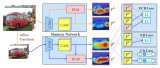
图1:我们使用给定的自然图像和文本问题作为输入,通过Visual QA架构输出答案。该架构使用硬注意力(hard attention)机制,仅为任务选择重要的视觉特征,进行进一步处理。我们的架构基于视觉特征的规范与其相关性相关的前提,那些具有高幅的特征向量对应的是包含重要语义内容的图像区域。
相比之下,hard attention仅仅选择一部分信息,对其进行进一步处理,这一方法现在已经得到越来越广泛地使用。和soft attention机制一样,hard attention也有可能通过将计算重点放在图像中的重要部分来提高准确性和学习效率。但除此之外,hard attention的计算效率更高,因为它只对认为相关度最高的那部分信息做完全处理。
然而,在基于梯度的学习框架(如深度学习)中存在一个关键的缺点:因为选择要处理的信息的过程是离散化的,因此也就是不可微分的,所以梯度不能反向传播到选择机制中来支持基于梯度的优化。目前研究人员正在努力来解决视觉注意力、文本注意力,乃至更广泛的机器学习领域内的这一缺点,这一领域的研究仍然非常活跃。
本文中,我们探讨了一种简单的hard attention方法,它在卷积神经网络(CNN)的特征表示中引发有趣的现象:对于hard attention选择而言,已被学习过的特征通常是易于访问的。特别是,选择那些具有最大L2范数值的特征向量有助于hard attention方法的实现,并体现出性能和效率上的优势(见图1)。这种注意力信号间接来自标准的监督任务损失,并且不需要明确的监督与对象存在、显著性或其他可能有意义的相关指标。
硬注意力网络和自适应硬注意力网络
我们使用规范化的Visual QA pipeline,利用特征向量的L2-norms来选择信息的子集,以进行进一步处理。第一个版本称为硬注意力网络(Hard Attention Network, HAN),它可以选择固定数量的规范度最高的特征向量,对其对应的信息作进一步处理。
第二个版本称为自适应硬注意力网络(Adaptive Hard Attention Network ,AdaHAN),它会根据输入选择可变数量的特征向量。我们的实验结果表明,在具有挑战性的Visual QA任务中,我们的算法实际上可以胜过类似的soft attention架构。该方法还能生成可解释的hard attention masks,其中与被选中特征相关的图像区域通常包含在语义上有意义的信息。我们的模型在与非局部成对模型相结合时也表现出强大的性能。我们的算法通过成对的输入特征进行计算,因此在特征图中的规模与向量数量的平方成正比,这也突出了特征选择的重要性。
方法
回答有关图像的问题通常是根据预测模型制定的。这些结构将相对回答a的条件分布最大化,给定问题q和图像x:

其中A是所有可能答案的可数集合。就像常见的问题-回答一样,问题是一个单词序列q = [q1,...,qn],而输出被简化为一组常见答案之间的分类问题。我们用于从图像和问题中学习映射的架构如图2所示。
图2:hard attention取代了常用的soft attention机制。
我们用CNN(在这个例子中是预训练过的ResNet-101,或者从头开始训练的一个小型CNN)对图像进行编码,然后用LSTM将问题编码成固定长度的向量表示。通过将问题表示复制到CNN的每个空间位置来计算组合表示,并将其与视觉特性连接在一起。
在经过几层组合处理之后,我们将注意力放在了空间位置上,就跟应用soft attention机制的先前工作一样。最后,我们使用sum-pooling或relational 模块聚合特性。我们用一个对应答案类别的标准逻辑回归损失来端到端地训练整个网络。
结果
为了说明对于Visual QA,hard attention的重要性,我们首先在VQA-CP v2上将HAN与现有的soft attention(SAN)架构进行比较,并通过直接控制卷积图中注意空间单元的数量来探究不同程度的hard attention的影响。
然后,我们对AdaHAN进行了实验,AdaHAN自适应地选择了attended cell的数量。我们也简要地研究了网络深度和预训练的影响。最后,我们给出了定性的结果,并提供了在CLEVR数据集上的结果,以说明该方法的通用性。
Hard Attention的效果
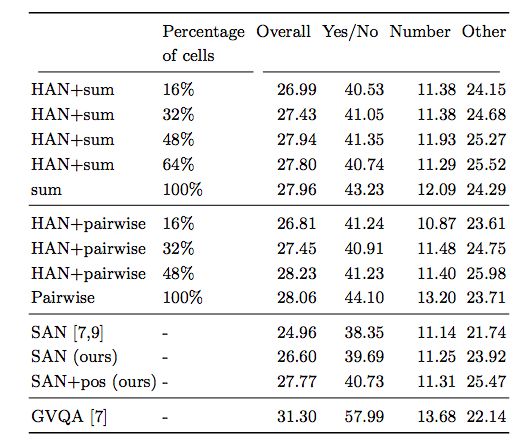
表1:不同数量的attended cell(整个输入的百分比)和聚合操作的比较
结果显示, 有 hard attention下,相比没有 hard attention,模型的性能得到了提报。
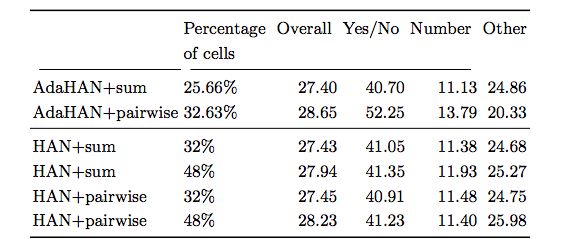
表2:不同的自适应hard-attention技术与平均参与数、以及聚合操作的比较
结果显示,soft attention并不优于基本的sum polling方法。我们的结果尽管比state-of-the-art略差,但这可能是由于实验中未包含的一些架构决策,例如不同类型问题的分离路径,特殊问题嵌入和使用问题提取器( question extractor)。
Adaptive hard attention
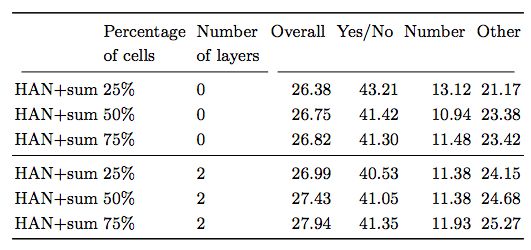
表3:不同数量的attended cells 占整个输入的百分比
结果显示,即使是以非常简单的方法来适应图像和问题,也可以导致计算和性能的提高,这表明更复杂的方法将是未来工作的重要方向。
CLEVR数据集上的表现
图3: hard attention机制的不同变体与不同聚合方法之间的定性比较。绿色表示正确答案,红色表示不正确,橙色表示和人类的答案之间的存在部分共识。这张图说明了不同方法的优点。
图4:我AdaHAN +成pairwise的其他结果。图中,被注意的区域突出显示,不被注意的区域则用暗色表示。绿色表示正确,红色不正确的答案。 橙色表示存在部分共识。
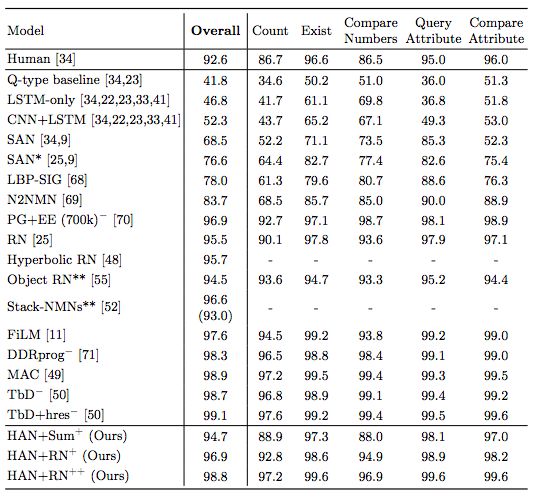
表4:在CLEVR上的准确率
由于hard-attention,我们能够训练更大的模型,我们称之为HAN + sum⁺,HAN + RN⁺,以及HAN + RN⁺⁺。这些模型使用更大的CNN和LSTM,而且HAN + RN⁺⁺还使用更高的输入分辨率。模型在CLEVR上的准确率分别达到94.7%、96.9%和98.8%。
总结
我们在计算机视觉领域引入了一种新的方法,可以选择特征向量的子集,以便根据它们的大小进行进一步处理。我们研究了两个模型,其中一个模型(HAN)会选择数目预先确定的向量的子集,另一个模型(AdaHAN)则自适应地选择子集规模作为输入的函数。现有文献中经常避免提到hard attention,因为它不可微分,对基于梯度的方法提出了挑战。但是,我们发现特征向量的大小与相关信息有关,hard attention机制可以利用这个属性来进行选择。
结果显示,HAN和AdaHAN方法在具有挑战性的Visual QA数据集上的表现具备很强的竞争力。我们的方法至少和更常见的soft attention方法的表现一样好,同时还提升了计算的效率。hard attention方法对于越来越常见的non-local方法而言尤其重要,这类方法通常需要的计算量和存储器数量与输入向量的平方成正比。最后,我们的方法还提供了可解释的表示,因为这种方法所选择的特征的空间位置与图像中最重要的部分构成最强的相关性。
-
神经网络
+关注
关注
42文章
4570浏览量
98714 -
计算机视觉
+关注
关注
8文章
1596浏览量
45602 -
机器学习
+关注
关注
66文章
8112浏览量
130545
原文标题:DeepMind提出视觉问题回答新模型,CLEVR准确率达98.8%
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于labview的注意力分配实验设计

一种通过引入硬注意力机制来引导学习视觉回答任务的研究
一种自监督同变注意力机制,利用自监督方法来弥补监督信号差异
基于注意力机制和本体的远程贾璐关系抽取模型

华南理工开源VISTA:双跨视角空间注意力机制实现3D目标检测SOTA

基于YOLOv5s基础上实现五种视觉注意力模块的改进





 工商网监
工商网监
评论