 探索GAN的景观,并讨论常见的陷阱和可重复性等问题
探索GAN的景观,并讨论常见的陷阱和可重复性等问题
随着GAN越来越多的应用到实际研究当中,其技术中的缺陷与漏洞也随之出现。从实际角度对GAN的当前状态进行深入挖掘与理解就显得格外重要。来自Google Brain的Karol Kurach等人重现了当前的技术发展水平,探索GAN的景观,并讨论常见的陷阱和可重复性等问题。
从实际角度对GAN的当前状态进行深入挖掘与理解对GAN的发展有着重要的意义。来自Google Brain的Karol Kurach等人重现了当前的技术发展水平,探索GAN的景观,并讨论常见的陷阱和可重复性等问题。Lan Goodfellow等AI界大咖也对此成果表示赞同,并纷纷转载。
深度生成模型可以应用于学习目标分布的任务。 他们最近在各种应用程序中被利用,在自然图像的背景下充分发挥其潜力。 生成对抗网络(GAN)是以完全无监督的方式学习这些模型的主要方法之一。 GAN框架可以被视为一个双人游戏,其中第一个“玩家”,生成器(generator),正在学习将一些简单的输入分布(通常是标准的多元正态或均匀)转换为图像空间上的分布,这样第二个“玩家”,鉴别器(discriminator),无法判断样本是属于真实分布还是合成。 两位“玩家”的目标都是尽量减少自己的损失,而比赛的解决方案就是Nash均衡(equilibrium),任何“玩家”都不能单方面改善他们的损失。 还可以通过最小化模型分布和真实分布之间的统计差异来导出GAN框架。
训练GAN需要解决发生器和鉴别器参数的最小极大(nimimax)问题。 由于发生器和鉴别器通常都被参数化为深度卷积神经网络,所以这种极小极大(minimax)问题在实践中是非常困难的。 为此,提出了许多损失函数,正则化和归一化以及神经结构的方案来做选择。 其中一些是基于理论见解得出的,而另一些则是实际考虑角度出发的。
在这项工作中,我们对这些方法进行了全面的实证分析。我们首先定义GAN landscape—损失函数集,归一化和正则化方案以及最常用的体系结构。我们通过超参数优化(hyperparameter optimization),在几个现代大规模数据集以及高斯过程回归(Gaussian Process regression)获得的数据集上探索这个搜索空间。 通过分析损失函数的影响,我们得出结论,非饱和损失(non-saturating loss)在数据集、体系结构和超参数之间足够稳定。然后,我们继续分析各种归一化和正则化方案以及不同的体系结构的效果。我们表明,梯度抑制(gradient penaltyas)以及频谱归一化(spectral normalization)在高容量(high-capacity)结构的背景下都是有用的。然后,我们发现人们可以进一步受益于同时正规化和规范化。最后,我们讨论了常见的陷阱,可重复性问题和实际考虑因素。
GAN Landscape
损失函数
令P表示目标分布,Q表示模型分布。原始的GAN公式有两种损失函数:minimax GAN和非饱和(NS) GAN。前者,鉴别器最小化二分类问题的负对数似然(即样本是真的还是假的),相当于最小化P和Q之间的Jensen-Shannon(JS)偏差。后者,生成器最大化生成样本是真实的概率。对应的损失函数定义为:
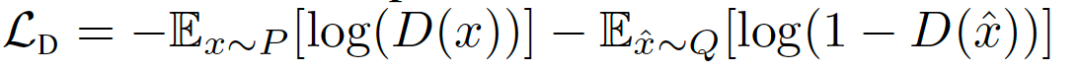
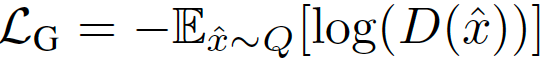
在综合考虑前人的研究后,我们考虑用最小平方损失(LS),相当于最小化P和Q之间的Pearson卡方散度(divergence)。对应的损失函数定义为:
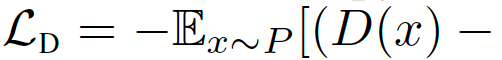
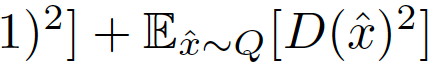
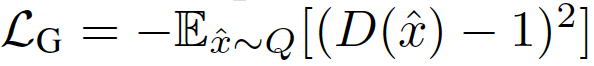
鉴别器的归一化和正则化
Gradient norm penalty
在训练点和生成的样本之间的线性插值上评估梯度,作为最佳耦合的代理(proxy)。 还可以在数据流形周围评估梯度损失,这促使鉴别器在该区域中成分段线性。梯度范数惩罚可以纯粹被认为是鉴别器的正则化器,并且它表明它可以改善其他损失的性能。计算梯度范数(gradient norms)意味着一个非平凡的运行时间惩罚(penalty) - 基本上是运行时间的两倍。
鉴别器归一化
从优化角度(更有效的梯度流、更稳定的优化)以及从表示的角度来看,归一化鉴别器是有用的 - 神经网络中层的表示丰富度取决于相应权重的谱结构矩阵。
从优化角度来看,一些关于GAN的技术已经成熟,例如: Batch normalization和Layer normalization (LN);从表示的角度来看,必须将神经网络视为(可能是非线性)映射的组合并分析它们的光谱特性(spectral properties)。特别地,为了使鉴别器成为有界线性算子,控制最大奇异值(maximum singular value)就可以了。
生成器和鉴别器机构
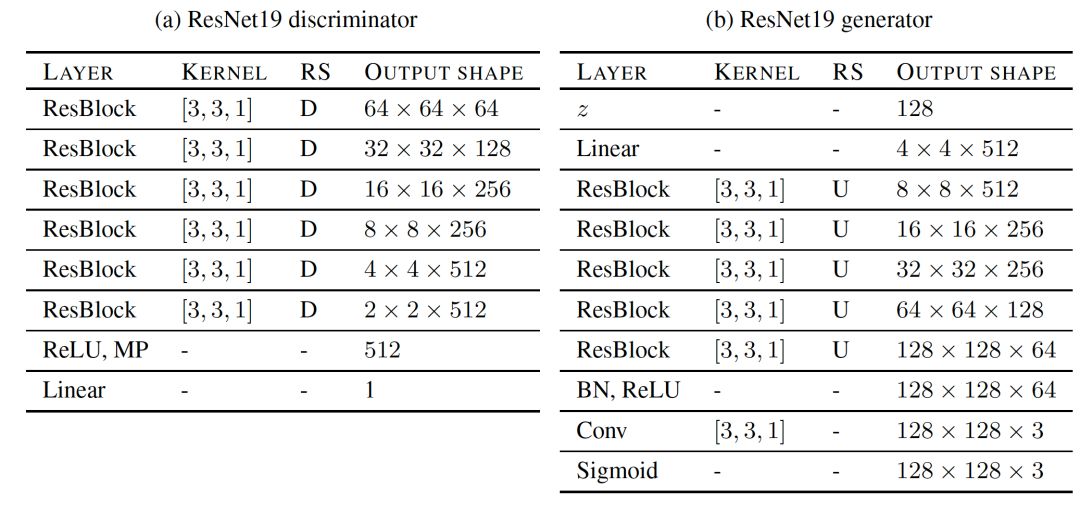
我们在这项研究中探索了两类架构:深度卷积生成对抗网络(DCGAN)和残余网络(ResNet)。ResNet19是一种架构,在生成器中有五个ResNet块,在鉴别器中有六个ResNet块,可以在128×128图像上运行。我们在每个鉴别器块中进行下采样,并且第一个块不包含任何自定义更改。 每个ResNet块由三个卷积层组成,这使得鉴别器总共有19层。 表3a和表3b总结了鉴别器和发生器的详细参数。 通过这种设置,我们能够重现并改进当前已有的最好结果。
评估方法
我们专注于几个最近提出的非常适合图像域的指标。
Inception Score (IS)
IS提供了一种定量评估生成样本质量的方法。 包含有意义对象的样本的条件标签分布应该具有低熵,并且样本的可变性应该高。 IS可以表示为:
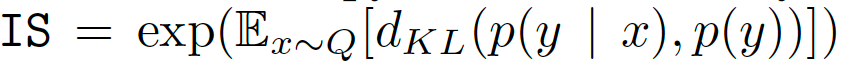
来自P和Q的样本首先嵌入到特征空间(InceptionNet的特定层)中。 然后,假设嵌入数据遵循多元高斯分布,估计均值和协方差。 最后,计算这两个高斯之间的Fréchet距离:
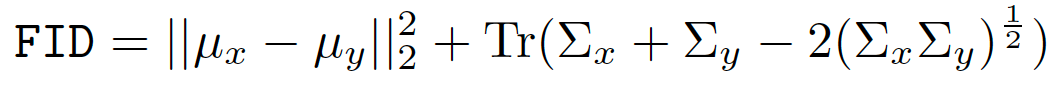
图像质量(MS-SSIM)和多样性的多尺度结构相似性
GAN中的一个关键问题是模式崩溃和模式丢失 - 无法捕获模式,或者从给定模式生成样本的多样性较低。MS-SSIM得分用于测量两个图像的相似度,其中较高的MS-SSIM得分表示更相似的图像。
数据集
我们考虑三个数据集,即CIFAR10,CELEBA-HQ-128和LSUN-BEDROOM。LSUN-BEDROOM数据集[包含300多万张图像。 我们将图像随机分成训练集和测试集,使用30588张图像作为测试集。 其次,我们使用30k张图像的CELEBA-HQ数据集,将3000个示例作为测试集,其余示例作为训练集。 最后,为了重现现有结果,我们还采用了CIFAR10数据集,其中包含70K张图像(32x32x3),60000个训练实例和10000个测试实例。 CELEBA-HQ-128的基线FID评分为12.6,LSUN-BEDROOM为3.8,CIFAR10为5.19。
实验结果
损失函数的影响
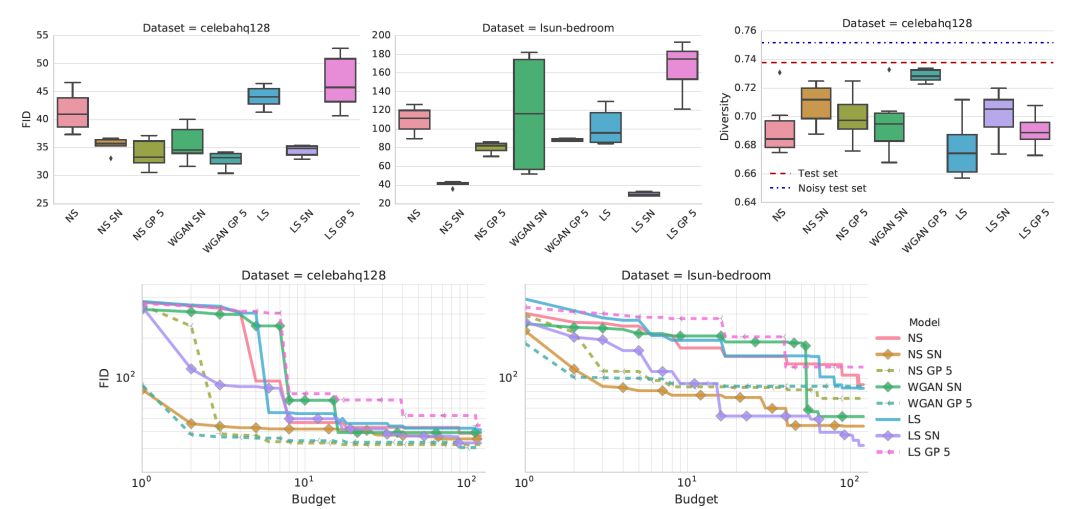
非饱和(NS)损失在两个数据集上都是稳定的
Gradient penalty和光谱(spectral)归一化提高了模型质量。 从计算预算的角度来看(即,需要训练多少个模型以达到某个FID),光谱归一化和Gradient penalty都比基线表现更好,但前者更有效。
Gradient penalty和谱归一化(SN)都表现良好,应该被认为是可行的方法,而后者在计算成本上更好。 可惜的是,没有人能完全解决稳定性问题。
归一化和正则化的影响
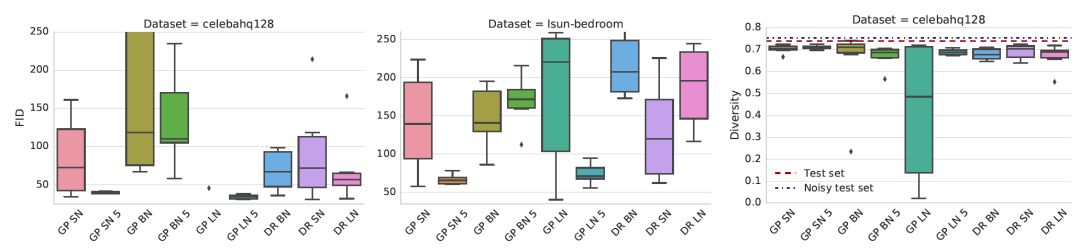
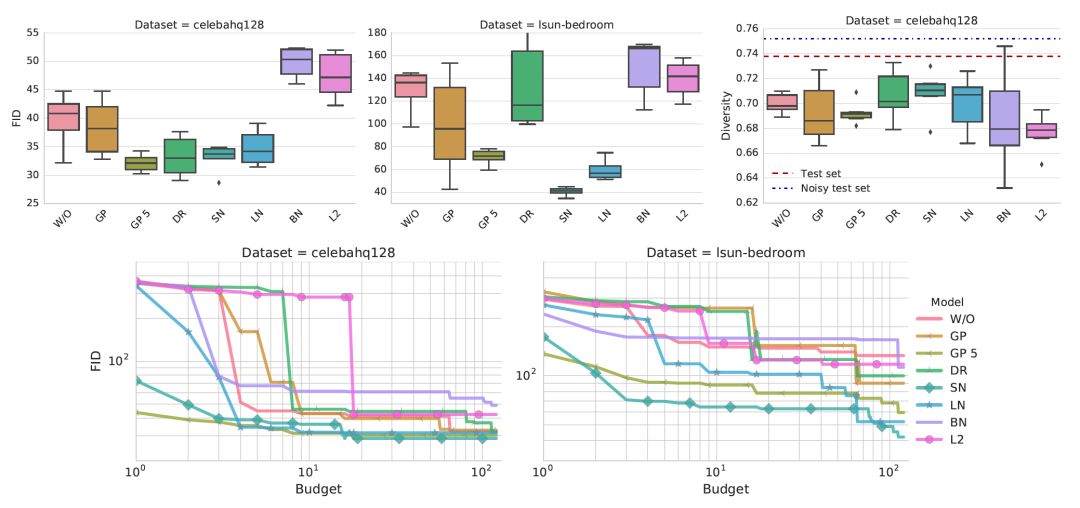
Gradient penalty加上光谱归一化(SN)或层归一化(LN)大大提高了基线的性能
生成器和鉴别器结构的影响
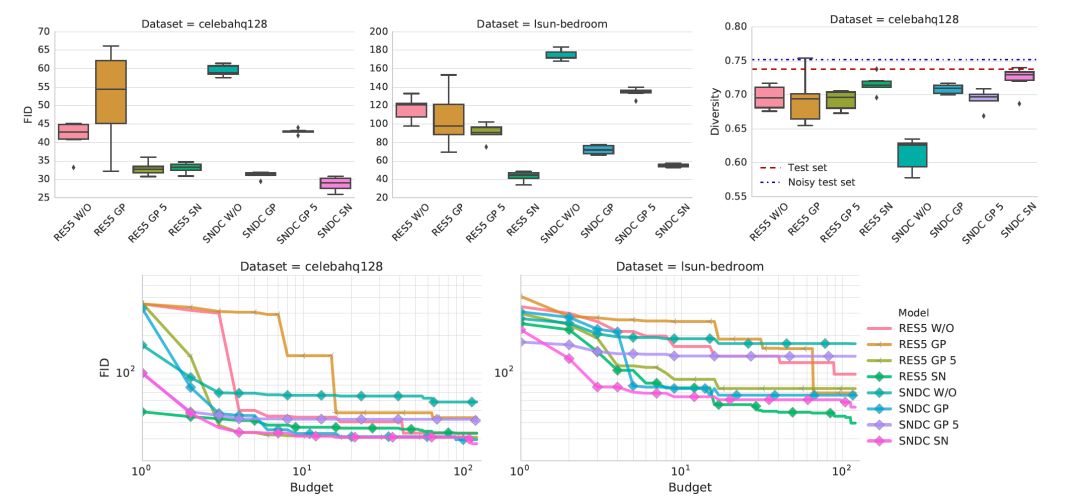
鉴别器和发生器结构对非饱和GAN损失的影响。光谱归一化和Gradient penalty可以帮助改进非正则化基线。
-
发生器
+关注
关注
3文章
1291浏览量
60842 -
GaN
+关注
关注
19文章
1762浏览量
67913 -
数据集
+关注
关注
4文章
1178浏览量
24348
原文标题:【GAN全局实用手册】谷歌大脑最新研究,Goodfellow力荐
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
PGA-SAR系统无法达到12比特级别的可重复性时,Δ-Σ系统会怎么样呢?
大规模中文搜索日志中查询重复性分析
测量系统的的重复性和重现性
相控阵探头的重复性与可靠性
选转换器?考虑下时序、精确度和可重复性以外的参考
机器人技术的可重复性和准确性分析
计量标准重复性的测量方法
流量计重复性差的解决方法
计量标准的重复性考核要求
在Verilog中利用函数将重复性的行为级设计进行提取
计量标准的重复性考核要求
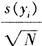





 工商网监
工商网监
评论