 什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?
Deepmind在Alphago上的成就把强化学习这一方法带入了人工智能的主流学习领域,【从零开始学习】也似乎成为了抛弃人类先验经验、获取新的技能并在各类游戏击败人类的“秘诀”。来自斯坦福的Andrey Kurenkov对强化学习的这一基础提出了质疑。本文中,他从强化学习的基本原则及近期取得的成就说起,肯定了其成果,也指出了强化学习的基础性局限。大数据文摘对本文进行了精华编译。
玩过棋牌游戏么?
假设你不会玩,甚至从来没有接触过。
现在你的朋友邀请你和他对战一局,并且愿意告诉你玩儿法。
你的朋友很耐心,他手把手教了你下棋的步骤,但是却始终不告诉你他所走每一步的含义,只在最后告诉你这盘棋的输赢结果。
对局开始。由于“没经验”,你一直输。但在经历了多次“失败的经验”后,你渐渐地发现了一些规律。
几个礼拜过去了,在几千把游戏实战的“磨练”下,你终于可以在对战中获得胜利。
挺傻的对吧?为什么你不直接问为什么下这个棋以及怎么下棋呢?
但是,这种学下棋的方法其实是今天大部分的强化学习方法的缩影。
什么是强化学习?
强化学习是人工智能基本的子领域之一,在强化学习的框架中,智能体通过与环境互动,来学习采取何种动作能使其在给定环境中的长期奖励最大化,就像在上述的棋盘游戏寓言中,你通过与棋盘的互动来学习。
在强化学习的典型模型中,智能体只知道哪些动作是可以做的,除此之外并不知道其他任何信息,仅仅依靠与环境的互动以及每次动作的奖励来学习。
先验知识的缺乏意味着角色要从零开始学习。我们将这种从零开始学习的方法称作“纯强化学习(Pure RL)”。
纯强化学习在西洋双陆棋和围棋这类游戏中被广泛应用,同时也应用于机器人技术等领域。
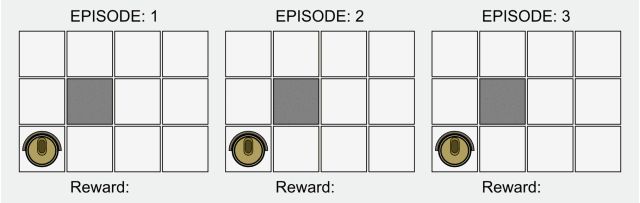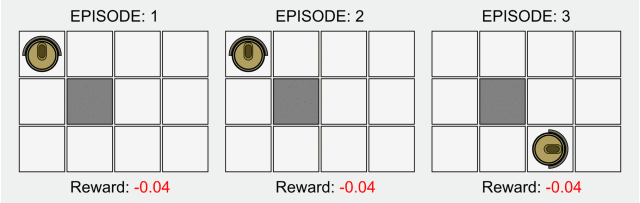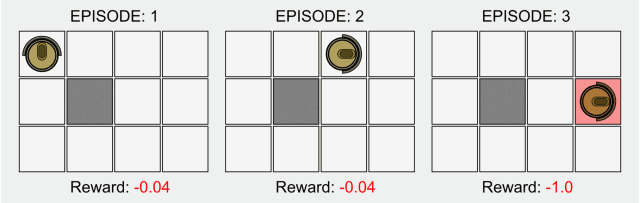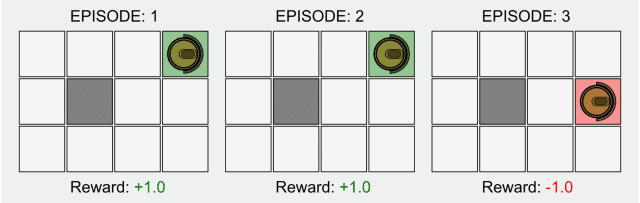
在传统的强化学习中,只有在最终状态才有非零奖励。这一领域的研究最近因为深度学习而再次受到关注,但是其基本的模型却并没有什么改进。
毕竟这种从零开始的学习方法可以追溯到强化学习研究领域的最初创建时期,也在最初的基本公式中就被编码了。
所以根本的问题是:如果纯强化学习没有什么意义,那么基于纯强化学习来设计AI模型还合理吗?
如果人类通过纯强化学习来学习新的棋类游戏听起来如此荒谬,那我们是不是应该考虑,这是不是一个本身就有缺陷的框架,那么AI角色又如何通过这一框架进行有效的学习呢?不依靠任何先前经验或指导,仅仅靠奖励信号来学习,是否真的有意义呢?
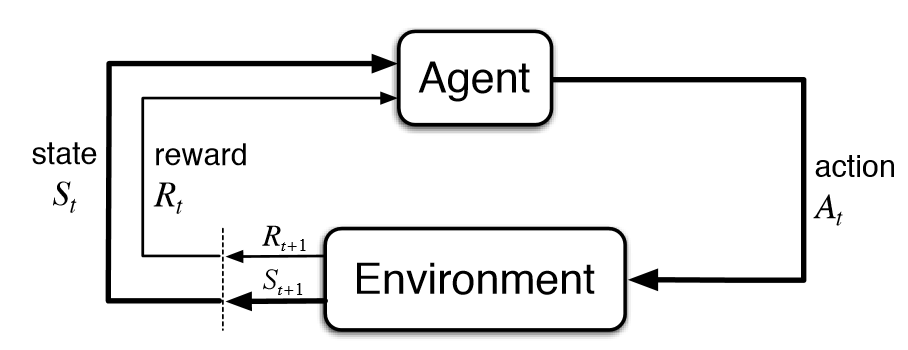
强化学习的基本公式
纯强化学习是否真的有意义?
关于这个问题,强化学习专家们众说纷纭:
有!纯强化学习当然有意义,AI智能体不是真正的人类,不用像我们一样学习。何况纯强化学习已经可以解决很多复杂问题了。
没有!从定义上看,AI研究包括让机器也能做目前只有人类能做的事情,所以跟人类智能来比较很合理。至于那些纯强化学习现在能解决的问题,人们总是忽视一点:那些问题其实没有它们看起来那么复杂。
既然业内无法达成共识,那就让我们来用事实说话。
基于纯强化学习,以DeepMind为代表的业内玩家已经达成了很多“炫酷”的成就:
1)DQN (Deep Q-Learning)—— DeepMind的著名研究项目,结合了深度学习与纯强化学习,并加入了一些别的创新,解决了很多以前解决不了的复杂问题。这个五年前的项目大大提高了人们对强化学习的研究兴趣。
毫不夸张的说,DQN是凭借一己之力重燃了研究者对于强化学习的热情。虽然DQN只有几项简单的创新,但是这几项创新对于深度强化学习的实用性至关重要。
虽然这个游戏现在看起来非常简单,仅仅是通过像素输入来学习,但在十年前,玩这个游戏是难以想象的。
2)AlphaGo Zero和AlphaZero——纯粹用于战胜人类的围棋、国际象棋及日本将棋的强化学习模型
首先来进行一个科普:AlphaGo Zero是谷歌DeepMinwd项目开发的最新的升级版AlphaGo。不同于原始的结合了监督学习和强化学习方式的AlphaGo,AlphaGo Zero单纯依靠强化学习和自我对弈来进行算法学习。
因此,尽管该模型也利用了一个预先提供的算法规则,即棋类的游戏规则和自我对弈来进行更可靠而持续的迭代更新,AlphaGo Zero更遵循纯强化学习的整体方法论:算法从零开始,通过学习结果的奖励信号反馈进行迭代。
由于它不是从人类身上直接学习游戏规则的,AlphaGo Zero也因此被许多人认为是一个比AlphaGo更具颠覆性的算法。然后就诞生了AlphaZero:作为一个更通用的算法,它不仅可以学习如何下围棋,还可以学习下国际象棋和日本将棋。
这是史上第一次出现用单一算法来破解象棋和围棋的算法。并且,它并没有像过去的深蓝计算机或者AlphaGo那样对任何一种游戏规则做特殊定制。
毫无疑问,AlphaGo Zero和AlphaZero是强化学习发展史上里程碑式的案例。
历史性的时刻——李世乭输给了AlphaGo
3)OpenAI的Dota机器人–由深度强化学习算法驱动的AI智能体,可以在流行的复杂多人对战游戏Dota2上击败人类。OpenAI在2017年在变化有限的1v1游戏中战胜了职业玩家的战绩已经足够让人惊叹。最近,它更是在一局复杂得多的5v5比赛中战胜了一整队人类玩家。
这一算法也与AlphaGo Zero一脉相承,因为它不需要任何人类知识,纯粹通过自我对弈对算法进行训练。在下面的视频里,OpenAI自己出色地解释了它的成就。
毫无疑问,在这种以团队合作为基础的高度复杂的游戏中,算法取得的好成绩,远远优于先前在Atari电子游戏和围棋上取胜的战绩。
更重要的是,这种进化是在没有任何重大算法进步的情况下完成的。
这一成就归功于惊人的计算量、已经成熟的强化学习算法、以及深度学习。在人工智能业内,大家普遍的共识是Dota机器人的胜利是令人惊叹的成就,也是强化学习一系列重要里程碑的下一个:
没错,纯强化学习算法已经取得了很多成就。
但仔细一想,我们就会发现,这些成就其实也“不过尔尔”。
纯强化学习的局限性
让我们从DQN开始回顾,在刚刚提到的这些案例中,纯强化学习到底存在哪些局限性。
它可以在很多Atari游戏中达到超人的水平,但一般来说,它只能在基于反射的游戏中做得很好。而在这种游戏中,你其实并不需要推理和记忆。
即使是5年后的今天,也没有任何一种纯强化学习算法能破解推理和记忆游戏;相反,在这方面做得很好的方法要么使用指令,要么使用演示,而这些在棋盘游戏中也行得通。
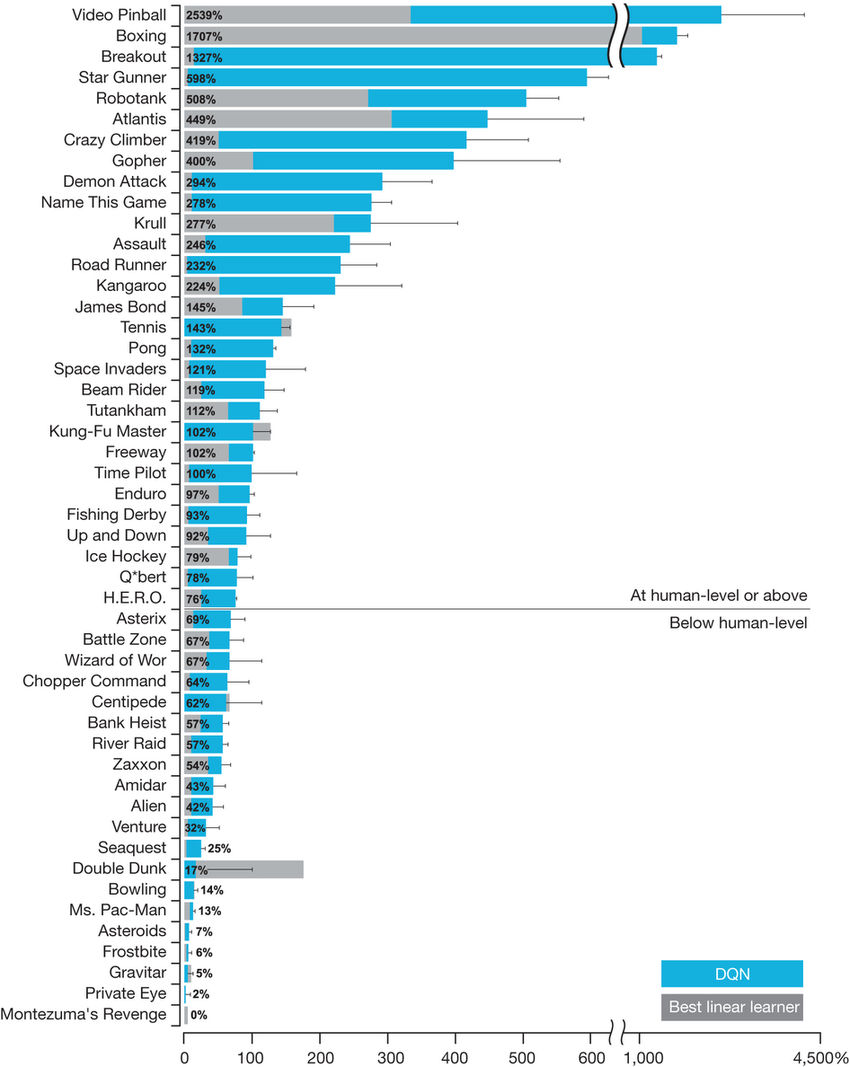
尽管DQN在诸如Breakout之类的游戏中表现出色,但它仍然无法完成像蒙特祖玛的复仇这样相对简单的游戏。
而即使是在DQN表现得很好的游戏里,和人类相比,它还是需要大量的时间和经验来学习。
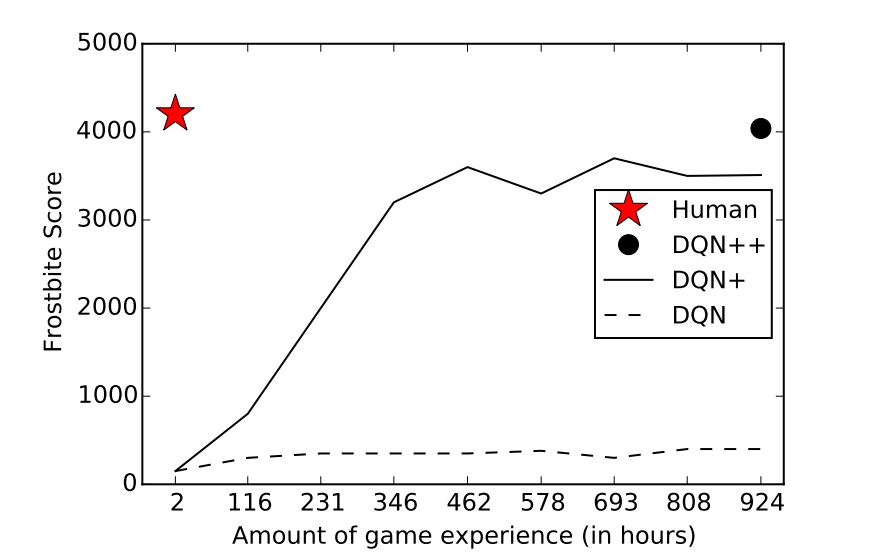
同样的局限性在AlphaGo Zero和AlphaZero中也存在。
也就是说,它的每一种性质都使学习任务变得容易:它是确定性的、离散的、静态的、完全可观察的、完全已知的、单智能体的、适用于情景的、廉价的、容易模拟的、容易得分的……
但在此前提下,对于围棋游戏来说,唯一的挑战是:它具有庞大的分支因子。
所以,尽管围棋可能是easy模式下最难的一道题,但它仍然是easy模式。而大多数研究人员都认识到,现实世界的多数问题比围棋这类简单的游戏复杂得多。
尽管有很多卓越的成就,但AlphaGo的所有变体在本质上仍与“深蓝”(Deep Blue)相似:它是一个经过多年设计的、投入高达数百万美元的昂贵系统,却纯粹只是为了玩一款抽象的棋盘游戏——除此之外别无其他用途。
现在到Dota了。
是的,这是一个比围棋复杂得多的游戏,缺乏很多使游戏变得简单的特性:它不是离散的、静态的、完全可观察的、单智能体的或适用于情景的——这是一个极具挑战性的问题。
但是,它仍然是一款很容易模拟的游戏,通过一个漂亮的API来控制——它完全消除了需要感知或运动控制。因此,与我们每天在真实世界中解决问题时所面临的真正的复杂性相比,它依然是简单的。
它仍然像AlphaGo一样,需要大规模投资。许多工程师为了得到一个算法,使用长到离谱的时间来解决这个问题。这甚至需要数千年的游戏训练并使用多达256个的GPU和128000个CPU核。
因此,仅仅因为强化学习的这些成果就认为纯强化学习很强大,是不正确的。
我们必须要考虑的是,在强化学习领域,纯强化学习可能只是最先使用的方法,但也许,它不一定是最好的?
纯强化学习的根本缺陷——从零开始
是否有更好的方法让AI智能体学习围棋或Dota呢?
“AlphaGo Zero”这个名字的含义就是指模型从零开始学习围棋。让我们回忆一下开头讲的那个例子。既然试着从头学起棋盘游戏而不作任何解释是荒谬的,那么AI为什么还一定要从零开始学习呢?
让我们想象一下,对于人类来说,你会如何开始学习围棋呢?
首先,你会阅读规则,学习一些高层次的策略,回想过去你是如何玩类似游戏的,然后从高手那里获取一些建议。
因此,AlphaGo和OpenAI Dota机器人从零开始学习的限制,导致他们和人类学习相比,依靠的是许多数量级的游戏指令和使用更原始的、无人能及的计算能力。
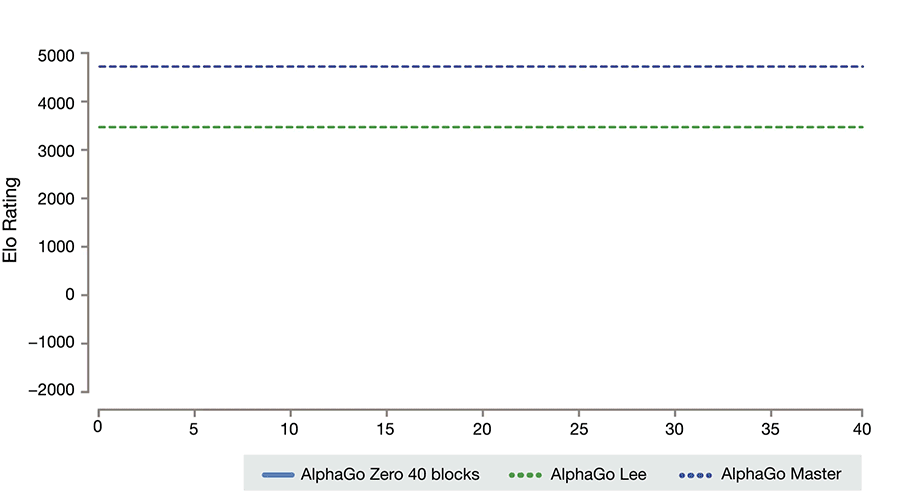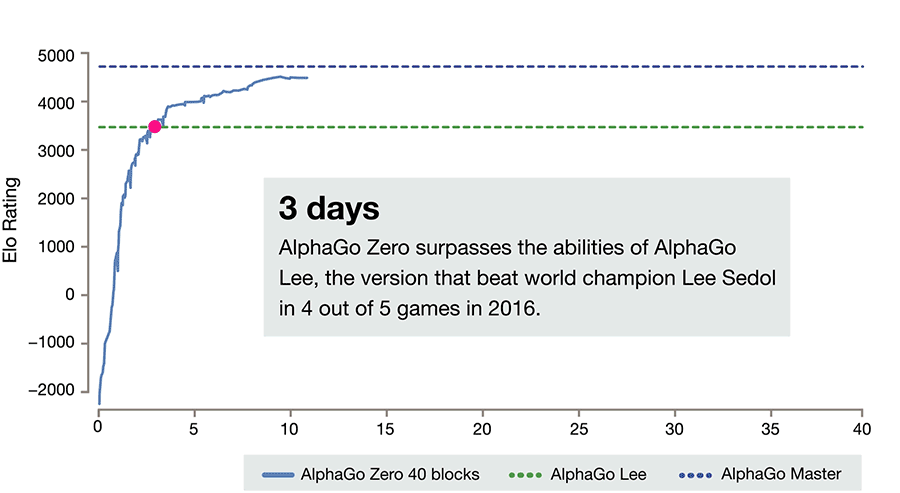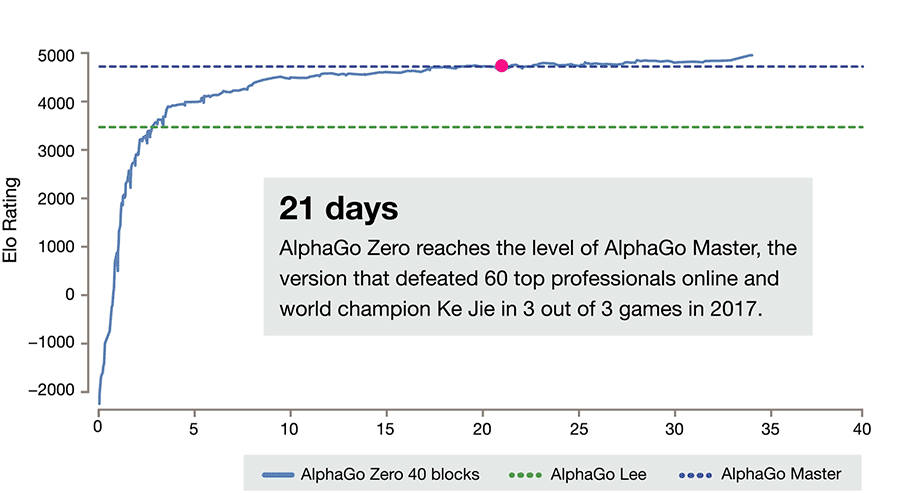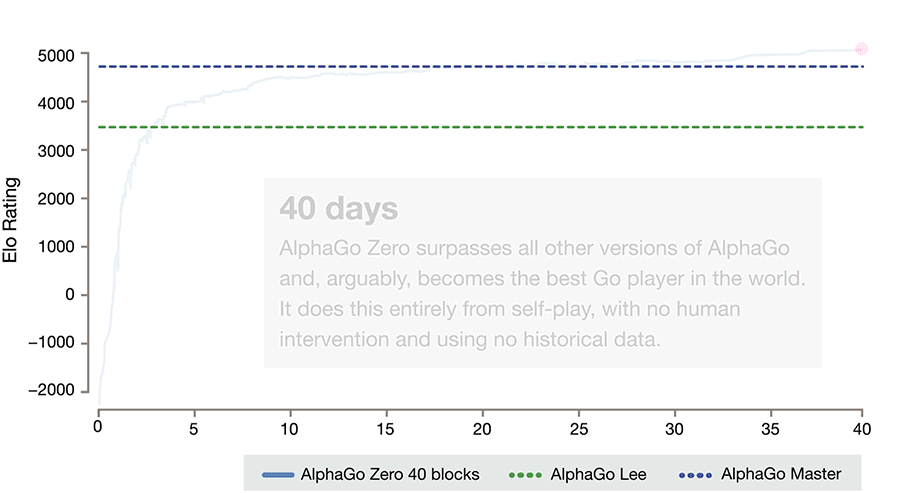
AlphaGo Zero的进展。请注意,要达到ELO分数为0,它需要一整天的时间和成千上万次的游戏(而即使是最弱的人也能轻松做到)。
公平地说,纯强化学习可以合理地用于诸如持续控制之类的“狭义”任务,或者最近的复杂游戏,如Dota或星际争霸。
然而,随着深度学习的成功,AI研究社区现在正试图解决越来越复杂的任务,这些任务必须面对现实世界中到复杂性。正是这些复杂性,我们可能需要一些超越纯强化学习的东西。
那么,让我们继续讨论我们的修正问题:纯强化学习,以及总体上从零开始学习的想法,是完成复杂任务的正确方法吗?
我们还应该坚持纯强化学习吗?
乍一看,这个问题的答案也许是:应该。为什么这么说呢?
从零开始的学习意味着它没有任何先入为主的主观因素,这样的话,经过学习的人工智能会比我们更加优秀,就像AlphaGo Zero一样。毕竟,如果人类的直接存在错误,那不就限制了机器的学习能力了么?
随着深度学习方法的成功,这个观点已经成为主流,虽然训练模型的数据量惊人,但是我们依旧只给予少量的先验知识。
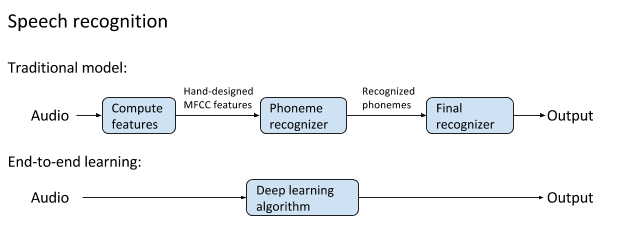
以前的非传统语音识别和端对端深度学习方法的图例,后者有更好的表现,并成为了现代语音识别的基础。
不过,让我们重新审视这个问题:结合人类的先验知识就一定会限制机器的学习能力么?
答案是否定的。也就是说,我们可以在深度学习的框架下(也就是只由数据出发),对手头的任务下达一定的指示,而不至于限制机器的学习能力。
目前,这个方向已经出现了诸多研究,相信这样的技术也能很快被应用到实际例子中。
比如像AlphaGo Zero这样的算法,我们大可不必从零开始学习,而是在不限制其学习能力的前提下加入人类知识的指导。
即使你觉得这个方向不靠谱,坚持要从零学习,那纯强化学习就是我们最佳的选择吗?
以前的话,答案是毋庸置疑的;在无梯度优化的领域中,纯强化学习是理论最完备而方法最可靠的。
不过近期很多文章都质疑这个论断,因为他们发现了相对简单的方法(而且总体而言没那么受到重视的)、基于进化策略的方法在一些典型的任务中似乎和纯强化学习表现得一样好:
《Simple random search provides a competitive approach to reinforcement learning》
《Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning》
大数据文摘微信公众号后台回复“缺陷”下载这两篇论文。
Ben Recht是最优化算法的理论与实践研究的带头人,他总结说:
我们发现随机搜索在简单线性问题中比强化学习更加优秀,比如策略梯度。不过,当我们遇到更加困难的问题时,随机搜索就会崩溃吗?并没有。
因此,并不能说强化学习是从零学习的最佳方法。
回到人类从零学习的问题上来,人类学习一个新的复杂技巧时就没有任何先验知识吗(比如组装一个家具或驾驶汽车)?其实并不是这样子的,对不对?
也许对于一些非常基础的问题来说(比如婴儿要学习的),我们可以从零开始,使用纯强化学习,但是对于AI领域中的很多重要问题,从零开始并没有特别的优势:我们必须清楚,我们想要AI学会什么,而且必须要提供这方面的演示和指导。
实际上,目前人们广泛认为,从零开始学习是强化学习模型受到限制的主要原因:
目前的AI是“数据依赖”的——大多数情况下,AI需要海量的数据才能发挥它的作用。这对于纯强化学习技术来说非常不利。回想一下,AlphaGo Zero需要上百万的对局来达到ELO分数为0的水平,而人类用很少的时间就能达到这个水平。显然,从零开始学习是效率最低的一种学习方法;
目前的AI是不透明的——在多数情况下,对于AI算法的学习,我们只有高层次的直觉。对于很多AI问题,我们希望算法是可预测和可解释的。但是一个什么都从零开始学习的巨型神经网络,其解释性和预测性都是最差的,它只能给出一些低层次的奖励信号或是一个环境模型。
目前AI是狭隘的——在很多情况下,AI模型只能够在特定领域表现的非常好,而且非常不稳定。从零开始学习的模式限制了人工智能学习能力。
目前的AI是脆弱的——AI模型只能把海量数据作为无形的输入进行泛化,但是结果非常不稳定。因此,我们只能知道我们要AI智能体学习的是什么。
如果是一个人,那么在开始学习前,应该能够对任务进行解释并提供一些建议。这对于AI来说,同样适用。
-
人工智能
+关注
关注
1775文章
43716浏览量
230494 -
大数据
+关注
关注
64文章
8632浏览量
136568 -
强化学习
+关注
关注
4文章
258浏览量
11112
原文标题:非得从零开始学习?扒一扒强化学习的致命缺陷
文章出处:【微信号:CAAI-1981,微信公众号:中国人工智能学会】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
什么是深度强化学习?深度强化学习算法应用分析

深度强化学习实战
将深度学习和强化学习相结合的深度强化学习DRL
萨顿科普了强化学习、深度强化学习,并谈到了这项技术的潜力和发展方向
一文详谈机器学习的强化学习
DeepMind发布强化学习库RLax
机器学习中的无模型强化学习算法及研究综述

《自动化学报》—多Agent深度强化学习综述

强化学习的基础知识和6种基本算法解释
强化学习的基础知识和6种基本算法解释

什么是强化学习






 工商网监
工商网监
评论