 DeepMind团队游戏新突破,AI和人类进行组队
DeepMind团队游戏新突破,AI和人类进行组队
我们还时常感叹两年前 AlphaGo 的一举成名,今天Deep Mind 的另一个游戏项目获得新的突破。不仅和人类进行一对一作战,还可以进行团队作战,与人类进行组队。
Deep Mind 在周二发表推文 “ 我们最新的工作演示了如何在一个复杂的第一人称多人游戏中实现多人游戏的性能,甚至可以与人类队友进行合作!”Deep Mind 开发了创新和强化学习技术,是人工智能系统在夺旗游戏中达到人类的水平,不仅各个人工智能独立行动,同时学会配合,进行团队战。Deep Mind 表示这项工作凸显了多智能体培训对促进人工智能发展的潜力。不得不说,在看完模拟游戏的视频确实觉得挺有意思的,今天人工智能头条就为大家介绍这个首款具有“团队精神” 的智能代理。
▌背景
Quake III Arena Capture the Flag——Quake III Arena 中文名称:雷神之锤III竞技场,是 1999 年在 PC 上推出的 一款FPS(第一人称射击类游戏)大作。Capture the flag 简称 CTF,CTF 在Quake 3 里分成蓝红两边在通常是一个对称的(也有不对称的)地图中竞赛。
竞赛的目的是将对方的旗子带回来,并且碰触未被移动过的我方旗子,我队就得一分,称作一个 capture。一般会设定两个要素,得分的极限以及时间极限,先到达分数极限的队伍获胜,若是两队势均力敌而难以得分,则通常会由时间的设定来结束一个游戏(match)。在夺旗模式中,杀死对手得1分,自己非正常死亡扣1分,夺取对方旗子得3分,杀死夺旗者得2分,重新拿到己方旗子得1分,成功夺取一次旗子(将旗子送回己方基地中)得5分。
▌前言
掌握多人视频游戏中涉及的策略,战术理解和团队配合一直是AI研究的关键性挑战。如今,随着强化学习的不断发展,DeepMind 提出的的智能代理能够在雷神之锤 III竞技场夺旗游戏(Quake III Arena Capture the Flag) 中实现人类玩家的水平。
该游戏涉及复杂的多智能体环境,也是一个典型的 3D第一人称视角的多人游戏。DeepMind 提出的智能代理展示了与人工智能体及人类玩家合作的能力。
下面我们将解读 DeppMind 最新的这篇博文,进一步了解这个 AI 智能体背后的技术及其在游戏中的表现。
所谓的多智能体学习的设置:指的是多个单智能体必须独立行动,并学会与其他智能体进行互动与合作。通过共适适应智能体,世界在不断变化,因而这是一个非常困难的问题。
我们的智能代理面临的挑战是直接从原始像素中进行学习并产生动作,这种复杂性使得第一人称视角的多人游戏,成为AI社区的一个硕果累累且活跃的研究领域。
在这项工作中,我们关注的游戏是 Quake III Arena(雷神之锤 III 竞技场,我们从美学的角度对游戏进行部分修改,但所有游戏机制都保持不变。)Quake III Arena是现代许多第一人称视频游戏的基础,并吸引了具备长期竞争力的电子竞技场景。
我们训练了一些能够单独学习并采取行动的智能代理,但它们必须要能够在游戏中共同协作,以便抵御其他智能体 (不论是人工智能体还是人类游戏玩家) 的攻击。
在这里CTF的规则很简单,但其具有复杂的动态性。两队的游戏玩家要在给定的地图上竞争,目标是在保护己方旗帜不被夺走的同时,夺取对方的旗帜。为了获得战术优势,玩家可以射击对方战队的玩家,并将它们送回复活点 (spawn point)。游戏时长为五分钟,最终拥有旗帜最多的队伍将获胜。
从多智能代理的角度来看,CTF既要求玩家们能与己方队友妥善合作,又要与敌方玩家相互竞争,同时还要灵活应变可能遇到的游戏风格的转变。
为了让这件事情更有意思,在这项工作中我们考虑CTF游戏的一种变体,其中每场游戏中的地图布局都会发生变化。因此,我们的智能代理必须要学会一种通用的策略,而非记住某种游戏地图的布局。此外,为了保证游戏竞争环境的公平,我们的智能体需要以与人类玩家类似的方式体验CTF游戏世界:即通过观察图像的像素流,模拟游戏控制器并采取相应的行动。
▌FTW 智能体
夺旗游戏是在程序生成的不同环境中进行的,因此智能体必须能够泛化到未知的地图。智能体必须从零开始学习如何在未知的环境中进行观察,行动,合作及竞争,每场游戏都是一个单独的强化信号:他们的团队是否获得胜利。这是一个具有挑战性的学习问题,其解决方案主要基于强化学习的三个基本概念:
我们不是训练一个单独的智能体,而是训练一群的智能体。他们互相学习,合作,甚至竞争,彼此成为队友或对手,以便适应多样化的游戏方式。
智能体们都需要各自学习自身内部的奖励信号,这将促使智能体能够生成自身内部的目标,如夺取一面旗帜。双重优化过程 (two-tier) 可直接优化智能体内部的获胜奖励,并基于内部奖励,运用强化学习方法来进一步地学习智能体的游戏策略。
智能体分别以快速和慢速两种时间尺度开始游戏,这有助于提高它们使用内存和生成一致动作序列的能力。
FTW(for the win) 智能体的结构示意图
该智能体的结构结合了快速和慢速时间尺度上的循环神经网络(Fast RNN & Slow RNN),其中包括一个共享记忆模块,并学习从游戏点到内部的奖励转换。
由此产生的智能体,我们称之为For The Win(FTW) 智能体,它学会了以非常高的标准玩CTF。更重要的是,该智能体学习到的游戏策略对地图的大小,队友的数量以及团队中的其他玩家都是稳健鲁棒的。
▌FTW的性能
下面演示了探索一些室外环境的游戏(其中FTW智能体互相竞争),以及一些智能体与人类玩家在室内环境中一起玩的游戏。
交互式的CTF 游戏浏览器,具有室内和室外的程序生成环境游戏
室外环境的游戏是 FTW 智能体之间的游戏,而室内环境下则是混合了人类玩家和 FTW 智能体的游戏。
在原文中通过6个不同场景,每个场景下3个不同角度的摄像头为大家呈现更多的游戏过程,如果大家希望看到所有场景与角度的视频,可以通过文章最后的原文链接进行查看。
我们进行了一场包括 40 名人类玩家的游戏比赛,在比赛中人类和智能体随机配对,既有可能成为对手,也可能成为队友。
在早前的一场 CTF 测试赛中,比赛双方是经过训练的智能体与人类玩家组成的队伍
经过训练学习,FTW 智能体已经比强大的基线方法更强大,并且超过了人类玩家的胜率。事实上,在一份对游戏参与者的调查报告中显示它们比人类玩家更具有合作性。
智能体在训练中的表现
FTW智能体的 Elo 评级 -- 获胜概率超过了人类玩家和 Self-play + RS、Self-play 等基线方法。
此外,我们不仅仅只对智能体进行了性能评估,还进一步探索了这些智能体的行为及内部表征的复杂度。
▌FTW的表征
为了理解智能体内部是如何表征游戏状态,我们观察并在平面上绘制智能体中神经网络的激活模式。下图中的点表示游戏中的情形,邻近的点表示相似的激活模式。这些点根据不同的 CTF 游戏状态进行相应地着色,这些状态包括:智能体在哪个房间?旗帜的状态怎样?可以看到哪些队友和对手?我们观察到同样颜色的簇表示该智能体以相似的方式表示类似的高级游戏状态。
智能体是如何表征游戏世界状态?智能体将不同情况下相同的游戏状态进行相似的表征。训练后的智能体甚至能够直接用一些人工神经元来编码特定情况。
我们的智能体从未得知任何的游戏规则,却能够学习基本的游戏概念并有效地发展对CTF游戏的直观认识。实际上,我们可以发现,智能体中某些特定的神经元可直接对最重要的游戏状态进行编码,例如当智能体的旗帜被夺走时,某个神经元就会被激活;或者当智能体的队友夺取旗帜时,某个神经元就将被激活等。我们的论文提供了进一步的分析,涉及的内容包括智能体在游戏过程中是如何利用记忆和视觉注意力机制的。
▌FTW的行为
除了丰富的游戏状态表征外,智能体在游戏中又是如何采取行动的呢?
首先,需要注意的是我们的智能体有非常快的反应时间及非常准确的命中率,这能解释它们在游戏中的卓越表现。人为地减少反应时间并降低命中率后,这仅是智能体获得成功的其中一个因素。
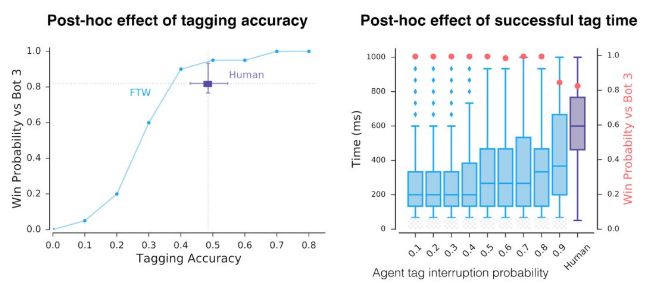
训练后,我们人为地减少反应时间和降低命中率,智能体所取得的游戏表现。即使是与人类玩家保持相近的反应时间和准确率,我们的智能体的游戏表现也优于人类玩家。
通过无监督学习的方式,我们在智能体和人类的原型行为之间建立联系,研究发现实际上智能体能够学习了类似人类的行为,例如跟随队友并敌方的基地扎营等行为。

已训练的智能体所展示的三个行为示例行为
在训练过程中,这些行为是伴随着强化学习和群体级进化而出现的。随着智能体以更加互补的方式进行学习合作,诸如在训练初期跟随队友的类似行为将逐渐变少。
FTW 智能体群体的训练进展
左上角展示了 30 个智能体在训练和互相演化过程中的 Elo 评级评分。右上角展示了这些演化事件的遗传树。底部展示了智能体训练过程中知识、内部奖励和行为概率的情况。
▌结束语
研究界最近在星际争霸II 和 Dota 2这样的复杂游戏中做了非常令人印象深刻的工作,虽然我们的研究侧重于夺旗游戏,但研究贡献是具有普遍性的,我们很高兴看到其他人如何在不同的复杂环境中建立我们的技术。在未来,我们还希望进一步改进目前的强化学习和基于人口的培训方法。总的来说,我们认为这项工作突出了多智能体培训推动人工智能发展的潜力
-
人工智能
+关注
关注
1776文章
43792浏览量
230563
原文标题:DeepMind在团队游戏领域取得新突破,AI和人类一起游戏真是越来越6了
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
谷歌DeepMind推出SIMI通用AI智能体
谷歌DeepMind推新AI模型Genie,能生成2D游戏平台
谷歌DeepMind资深AI研究员创办AI Agent创企
再登Nature!DeepMind大模型突破60年数学难题,解法超出人类已有认知

人机组队概念的战场应用
山东省大力发展元宇宙产业,DeepMind创始人访谈:AI像把双刃剑

GPT-5正秘密训练!DeepMind联创爆料,这模型比GPT-4大100倍

AI 人工智能的未来在哪?
谷歌DeepMind发现更快排序算法,已集成到C++库
谷歌DeepMind用AI改进数据排序
商汤联合发布通才AI智能体通关《我的世界》,像人类一样生存、探索和创造






 工商网监
工商网监
评论