 DeepMind生成查询网络GQN,从一个场景的少量2D照片中重新生成3D
DeepMind生成查询网络GQN,从一个场景的少量2D照片中重新生成3D
DeepMind今天在Science发表论文,提出生成查询网络(Generative Query Network,GQN),能够在无监督的情况下,抽象地描述场景元素,并通过“想象”渲染出场景中没有见到的部分。这项工作展示了没有人类标签或领域知识的表示学习,为机器自动学习并理解周围世界铺平了道路。
DeepMind又有大动作,早上起来便看到Hassabis的推文:
一直以来,我对大脑是如何在脑海中构建图像的过程深感着迷。我们最新发表在Science的论文提出了生成查询网络(GQN):这个模型能从一个场景的少量2D照片中重新生成3D表示,并且能从新的摄像头视角将它渲染出来。
Hassabis在接受《金融时报》采访时表示,GQN能够从任何角度想象和呈现场景,是一个通用的系统,具有广泛的应用潜力。
如果说新智元昨天介绍的DeepMind那篇有关图网络的论文重磅,那么这篇最新的Science更显分量。
“此前我们不知道神经网络能否能学会以如此精确和可控的方式来创建图像,”DeepMind的研究员、论文的第一作者Ali Eslami表示:“但是,这次我们发现具有足够深度的网络,可以在没有任何人类工程干预的情况下,学习透视和光线。这是一个非常惊人的发现。”

DeepMind最新发表在Science上的论文《神经场景表示和渲染》。包括老板Demis Hassabis在内,一共22名作者。本着开源共享的精神,文章以公开获取的形式在Science发表。
这篇文章的意义在于,提出了一种无监督的方法,不依赖带标记的数据,而且能够推广到各种不同的场景中。过去的计算机视觉识别任务,通常是建立在大量有标记的数据基础上,不仅标记这些数据麻烦,标记好的数据还可能带有偏见,最重要的是,已经有越来越多的研究者意识到,由于测试集过拟合的问题,很多分类器的鲁棒性亟待提高。
DeepMind的这套视觉系统,也即生成查询网络(GQN),使用从不同视角收集到的某个场景的图像,然后生成关于这个场景的抽象描述,通过一个无监督的表示学习过程,学习到了场景的本质。之后,在学到的这种表示的基础上,网络会预测从其他新的视角看这个场景将会是什么样子。这一过程非常类似人脑中对某个场景的想象。而理解一个场景中的视觉元素是典型的智能行为。
虽然还有诸多局限,但DeepMind的这项工作,在此前许许多多相关研究的基础上更进一步,展示了我们在让机器“理解世界”的道路上,迈出了坚实一步。
下面是DeepMind今天发表的官方博文,论文的联合第一作者S. M. Ali Eslami和Danilo Jimenez Rezende对这项工作进行了解读。
《神经场景表示和渲染》的研究背景
当谈到我们人类如何理解一个视觉场景时,涉及的不仅仅是视觉:我们的大脑利用先验知识进行推理,并做出远远超出光线的模式的推断。例如,当你第一次进入一个房间时,你能够立即识别出房间里的物品以及它们的位置。如果你看到一张桌子的三条腿,你会推断,可能存在第四条桌子腿从你的视线中隐藏了,它的颜色和形状应该与其他三条腿相同。即使你看不到房间里的所有东西,你也很可能勾画出它的布局,或者从另一个角度想象它的样子。
这些视觉和认知任务对人类来说似乎毫不费力,但它们对我们的AI系统来说是一个重大挑战。今天,最先进的视觉识别系统都是用人类产生的带注释图像的大型数据集训练的。获取这些数据是一个昂贵而且耗时的过程,需要有人对数据集中每个场景的每个对象进行标记。因此,通常只能捕获整体场景的一小部分内容,这限制了用这些数据进行训练的人工视觉系统。
当我们开发出在现实世界运行的更复杂的机器时,我们希望机器能充分了解它们所处的环境:可以坐的最近的表面在哪里?沙发是什么料子的?所有的阴影都是哪些光源产生的?电灯的开关可能在哪里?
论文一作S. M. Ali Eslami解读
在这篇发表于《科学》(Science)的最新论文中,我们提出生成查询网络(Generative Query Network,GQN)。在这个框架中,机器学习只使用它们在场景中移动时所获得的数据进行训练,从而感知周围的环境。
就像婴儿和动物一样,GQN通过尝试理解它对周围世界的观察来学习。在这样做的过程中,GQN了解了似乎合理的场景及其几何属性,而没有任何人类来对场景内容进行标注。
GQN:仅使用从场景中感知到的数据做训练
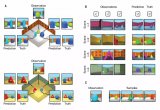
GQN模型由两个部分组成:表示网络(representation network)和生成网络(generation network)。表示网络将agent的观察结果作为输入,并生成一个描述基础场景的表示(向量)。然后,生成网络从先前未观察到的角度来预测(“想象”)场景。
Agent从不同视角观察训练场景
表示网络不知道生成网络被要求预测哪些视点,所以它必须找到一种有效的方式来尽可能准确地描述场景的真实布局。为了实现这个目的,表示网络以一种简洁的分布式表示来捕获最重要的元素(如对象位置、颜色和房间布局)。
在训练过程中,生成器学习环境中的典型对象、特征、关系和规则。这种共享的“概念”集合使表示网络能够以高度压缩、抽象的方式描述场景,让生成网络在必要时填充细节。
例如,表示网络会简洁地将“蓝色立方体”表示为一组数字,而生成网络将会知道如何以特定的视点将其显示为像素。
四大重要特性:能够“想象出”没有观察过的场景
我们在模拟的3D世界的一系列程序生成环境中,对GQN进行了受控实验。这些环境包含多个物体,它们的位置、颜色、形状和纹理都是随机的,光源也是随机的,而且会被严重遮挡。
在这些环境中进行训练后,我们使用GQN的表示网络来形成新的、以前未观察到的场景的表示。我们的实验表明,GQN具有以下几个重要特性:
GQN的生成网络能够以非常精确的方式从新的视角“想象”先前未观察到的场景。当给定一个场景表示和新的摄像机视点时,它会生成清晰的图像,而不需要事先说明透视、遮挡或灯光的规范。因此,生成网络是一种从数据中学习的近似渲染器(approximate renderer):
GQN的表示网络可以学会对对象进行计数、定位和分类,无需任何对象级标签。尽管GQN的表示可能非常小,但是它在查询视点(query viewpoints)上的预测是高度准确的,与ground-truth几乎无法区分。这意味着表示网络能够准确地感知,例如识别构成以下场景的块的精确配置:
GQN可以表示、测量和减少不确定性。即使内容不完全可见,它也能对场景的不确定性进行解释,并且可以将场景的多个局部视图组合成一个连贯的整体视图。如下图所示,这是由其第一人称(first-person)和自上而下的预测(top-down predictions)显示的。模型通过其预测的可变性来表示不确定性,不确定性随着其在迷宫中移动而逐渐减小(灰色的椎体指示观察位置,黄色椎体指示查询位置):
GQN的表示允许稳健的、数据有效(data-efficient)的强化学习。当给定GQN的紧凑表示时,与无模型基线agent相比, state-of-the-art的深度强化学习agent能够以更高的数据效率方式完成任务,如下图所示。对于这些agent,生成网络中编码的信息可以被看作是对环境的“先天”知识:
图:使用GQN,我们观察到数据效率更高的策略学习(policy learning),与使用原始像素的标准方法相比,其获得收敛级性能的交互减少了约4倍。
未来方向
GQN建立在此前大量相关工作的基础上,包括多视图几何、生成建模、无监督学习和预测学习,我们在论文中有详细讨论。
GQN演示了一种学习紧凑的、基础的物理场景表示的新方法。关键的是,我们提出的方法不需要专用领域工程(domain-specific engineering)或耗时的场景内容标记,从而允许将相同的模型应用于各种不同的环境。GQN还学会了一个强大的神经渲染器,能够从新的视角生成精确的场景图像。
与更传统的计算机视觉技术相比,我们的方法仍然有许多限制,目前只有接受过合成场景的训练。然而,随着获得更多新的数据源,以及硬件功能的进展,我们期望能够探索GQN框架在更高分辨率的真实场景图像中的应用。在未来的工作中,我们将探索GQN在场景理解的更广泛方面的应用,例如通过查询跨空间和时间学习物理和运动的常识概念,以及虚拟和增强现实中的应用。
尽管在我们的方法在投入实用前还有很多研究需要完成,但我们相信这项工作是迈向完全自主场景理解的一大步。
-
神经网络
+关注
关注
42文章
4572浏览量
98720 -
机器学习
+关注
关注
66文章
8116浏览量
130550 -
DeepMind
+关注
关注
0文章
126浏览量
10709
原文标题:【Science重磅】DeepMind生成查询网络GQN,无监督学习展现3D场景
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Ansys Maxwell 3D 2D RMxprt v16.0 Win32-U\
AD+Solidworks配合=3D模型相关问题
针对显示屏的2D/3D触摸与手势开发工具包DV102014
如何同时获取2d图像序列和相应的3d点云?
Intel Q33 express芯片组如何启用2D和3D?
自动3D X射线和离轴2D X射线检查
PYNQ框架下如何快速完成3D数据重建
视觉处理,2d照片转3d模型
Google AI子公司开发出一个神经网络GQN,其组成部分介绍





 工商网监
工商网监
评论