 基于语义布局的图像合成更逼真、效果更好
基于语义布局的图像合成更逼真、效果更好
编者按:去年,英特尔实验室视觉组主管Vladlen Koltun和斯坦福大学博士陈启峰发表论文Photographic Image Synthesis with Cascaded Refinement Networks,用级联优化网络生成照片。这种合成的图片是神经网络“凭空”生成的,也就是说,世界上根本找不到这样的场景。他们的算法可以看做一个渲染引擎,输入一张语义布局,告诉算法哪里有道路、哪里有车、交通灯、行人、树木,算法就能按照图中的布局输出一张逼真的图像,“好比机器想象出来的画面”。
在这篇论文中,英特尔实验室和香港中文大学的研究人员共同创造了一种半参数的图像合成方法,让基于语义布局的图像合成更逼真、效果更好。以下是论智对原论文的编译。
在古罗马作家普林尼的作品《自然史》中记述了这样一则故事:“公元前五世纪,古希腊画家宙克西斯(Zeuxis)以日常绘画和对光影的利用而闻名。他画了一个小男孩举起葡萄的作品,葡萄非常自然、逼真,竟吸引鸟儿前来啄食。然而宙克西斯并不满意,因为画上的男孩举起葡萄的动作还不够逼真,没有吓跑鸟儿。”技术高超的画家想做出以假乱真的画已经很困难了,机器可以实现这个任务吗?
用深度神经网络进行现实图像合成为模拟现实图像开辟了新方法。在现代数字艺术中,能合成非常逼真的图像的深层网络成为一种新工具。通过赋予它们一种视觉想象的形式,证明了它们在AI创造中的有用性。
最近的图像合成发展大多得益于基于参数的模型驱动,即能代表所有图像外观权重所有数据的深层网络。这与人类写实画家的做法完全不同,他们并不是依靠记忆作画,而是用外部参考当做材料来源,再现目标物体的外观细节。这也和之前图像合成的方法不同,传统的图像合成方法基于非参数技术,可以在测试时使用大规模数据集。从非参数方法转变为参数方法,研究人员发现,端到端的训练有着高度表达的模型。但它在测试时放弃了非参数技术优势。
在这篇论文中,我们提出了一种半参数的方法(semi-parametric approach),从语义布局中合成近乎真实的图像,这种方法被称作“半参数图像合成(semi-parametric image synthesis,SIMS)”。半参数合成方法结合了参数和非参数技术各自的优势,在所提出的方法中,非参数部分是指一组与照片相对的语义布局训练集中绘制的分段数据库。这些片段用于图像合成的原始材料,它们通过深度网络应用在画布上,之后,画布会输出一张图像。
Chen和Koltun的研究成果与我们的SIMS方法的成果对比。第一行是输入的语义布局
实验概览
我们的目标是基于语义布局L∈{0, 1}h×w×c合成一张逼真的图像,其中h×w是图片尺寸,c是语义类别的数量。下图是图像合成第一阶段的大致过程:
我们的模型在一对对图片和其对应的语义布局上进行训练,图片集是用于生成不同语义类别的图像片段存储库M,其中的每个片段Pi都来源于训练图像,并且属于一个语义类别。图中的a和b两部分就是一些片段。
在测试时,我们会得到在训练时从未见过的语义标签映射L,这个标签映射会分解成互相连接的组成部分{Li},对于每个连接部分,我们都会根据形状、位置和语境,从M中检索兼容的片段,即上图b的步骤。而检索步骤与Li被一个经过训练的空间变压器网络相连接,即图上的c和d。经过转换的片段在画布上进行合成,C∈Rw×h×3,即上图中的f。由于片段无法与{Li}完美重合,也许会出现重叠的情况。最后e部分用来进行前后排序。
之后,画布C和输入的语义布局L一同被输入合成网络f中,网络生成最终的图像被输出,过程如下图所示:
这一过程补全了缺失的区域、调整检索到的片段、混合边界、合成阴影,并且基于画布和目标布局调整图像外观。具体架构和训练过程可查看原论文。
为了将我们的方法应用到较为粗略的语义布局中,我们训练了一个级联的精炼网络,用于将粗糙的布局输入转化成密集的像素级输出。
实验过程
数据集
本次实验在三个数据集上进行:Cityscapes、NYU和ADE20K。Cityscapes数据集包含的是城市道路景观照,其中有3000张带有精细标记的图像,20000张粗略标记的、用于训练的图像。我们让模型在这两种图像上分别训练,最终在含有500张图像的验证数据集上进行测试。
对于NYU数据集,我们在前1200张图像上进行训练,剩下的249张图像用于测试。而ADE20K数据集是室外图片,我们中其中1万张图像进行训练,1000张图像进行测试。
感知测试
我们将提出的方法和pix2pix以及CRN进行了对比,下图是结果,表中的每一项都显示,我们的方法(SIMS)都比由pix2pix和CRN合成的图像更真实:

语义分割准确度
接下来,我们分析了合成图像的真实性。给定一个语义布局L,我们用一种可评估的方法合成一张图像I,该图像之后会被输入到一个预训练过的语义分割网络(这里我们用PSPNet)。这个网络会生成一个语义布局Lˆ,然后我们将Lˆ和L相比较。理论上来说,二者越接近,图像的真实程度就越高。比较L和Lˆ有两种方法:intersection over union(IoU)和总体像素精度。
最终的结果如下:
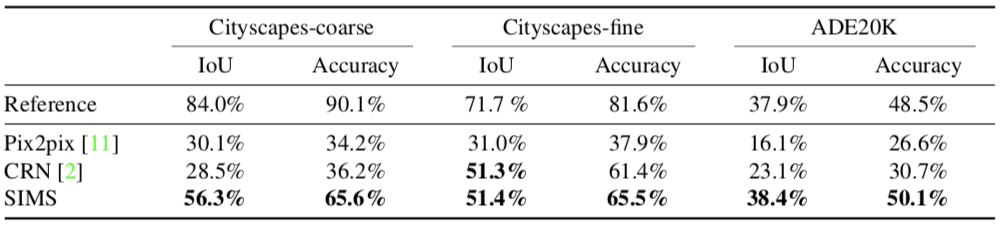
我们的SIMS方法比pix2pix和CRN生成的图像更合理、更真实。
图像数据
接着,我们从低级图像数据方面分析图像的真实性。我们比较了合成图像的平均经典谱(power spectrum)以及对应的数据集中的真实图像。下图显示了三种方法合成图像的平均经典谱:
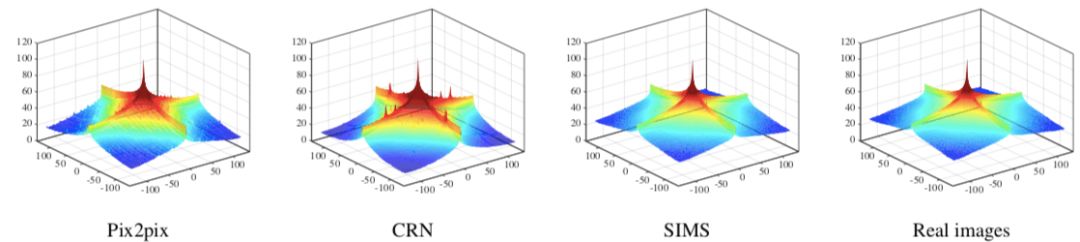
可以看出,我们的方法生成的平均经典谱与真实图像的平均经典谱非常接近,而其他两种方法则与真实图像有差别。
质量结果
从以下两张图中可以看出这三种方法的差别。
结语
我们所提出的半参数图像合成方法(SIMS)可以从语义布局中生成图像,实验证明这种方法比完全参数化的技术生成的图像更真实。但是在这之后仍有一些尚未解决的问题。首先,我们的方法在部署时比完全基于参数的方法慢很多。另外还要开发更高效的数据机构和算法。其次,其他形式的输入也应该可用,例如语义实例分割或者文本描述。第三,我们所提出的方法并不是端到端训练的。最后,我们希望这项半参数技术能应用到视频合成上。
-
神经网络
+关注
关注
42文章
4570浏览量
98714 -
图像
+关注
关注
2文章
1063浏览量
40037 -
数据集
+关注
关注
4文章
1178浏览量
24347
原文标题:英特尔实验室推出半参数图像合成方法,AI造图“以假乱真”
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种基于超像素的户外建筑图像布局标定方法
搜狗与新华社联合发布全球首个站立式AI合成主播
3D效果逼真的元件封装库网盘下载
基于语义报文的干扰效果评估系统设计
人工智能系统VON,生成最逼真3D图像
人体图像合成制作可信和逼真的人类图像
分析总结基于深度神经网络的图像语义分割方法

结合双目图像的深度信息跨层次特征的语义分割模型

一种具有语义区域风格约束的图像生成框架

基于SEGNET模型的图像语义分割方法
语义分割标注:从认知到实践
深度学习图像语义分割指标介绍






 工商网监
工商网监
评论