 手动设计一个卷积神经网络(前向传播和反向传播)
手动设计一个卷积神经网络(前向传播和反向传播)
上篇文章中我们讲解了卷积神经网络的基本原理,包括几个基本层的定义、运算规则等。本文主要写卷积神经网络如何进行一次完整的训练,包括前向传播和反向传播,并自己手写一个卷积神经网络。如果不了解基本原理的,可以先看看上篇文章:【深度学习系列】卷积神经网络CNN原理详解(一)——基本原理
卷积神经网络的前向传播
首先我们来看一个最简单的卷积神经网络:
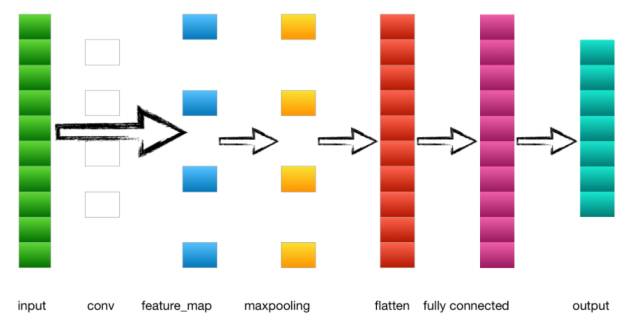
1.输入层---->卷积层
以上一节的例子为例,输入是一个4*4 的image,经过两个2*2的卷积核进行卷积运算后,变成两个3*3的feature_map
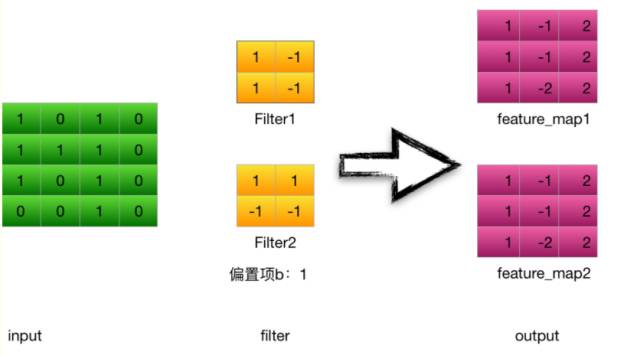
以卷积核filter1为例(stride = 1 ):

计算第一个卷积层神经元o11的输入:
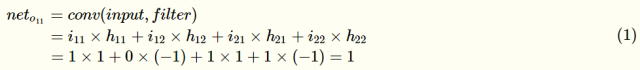
神经元o11的输出:(此处使用Relu激活函数)

其他神经元计算方式相同
2.卷积层---->池化层

计算池化层m11的输入(取窗口为 2 * 2),池化层没有激活函数

3.池化层---->全连接层
池化层的输出到flatten层把所有元素“拍平”,然后到全连接层。
4.全连接层---->输出层
全连接层到输出层就是正常的神经元与神经元之间的邻接相连,通过softmax函数计算后输出到output,得到不同类别的概率值,输出概率值最大的即为该图片的类别。
卷积神经网络的反向传播
传统的神经网络是全连接形式的,如果进行反向传播,只需要由下一层对前一层不断的求偏导,即求链式偏导就可以求出每一层的误差敏感项,然后求出权重和偏置项的梯度,即可更新权重。而卷积神经网络有两个特殊的层:卷积层和池化层。池化层输出时不需要经过激活函数,是一个滑动窗口的最大值,一个常数,那么它的偏导是1。池化层相当于对上层图片做了一个压缩,这个反向求误差敏感项时与传统的反向传播方式不同。从卷积后的feature_map反向传播到前一层时,由于前向传播时是通过卷积核做卷积运算得到的feature_map,所以反向传播与传统的也不一样,需要更新卷积核的参数。下面我们介绍一下池化层和卷积层是如何做反向传播的。
在介绍之前,首先回顾一下传统的反向传播方法:

卷积层的反向传播
由前向传播可得:
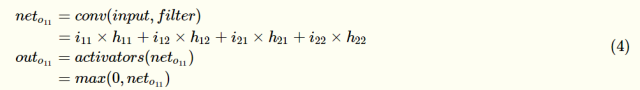

然后依次对输入元素求偏导

观察一下上面几个式子的规律,归纳一下,可以得到如下表达式:
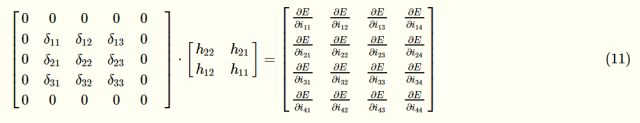
图中的卷积核进行了180°翻转,与这一层的误差敏感项矩阵deltai,j)deltai,j)周围补零后的矩阵做卷积运算后,就可以得到∂E/∂i11,即∂E/∂ii,j=∑m⋅∑nhm,nδi+m,j+n
第一项求完后,我们来求第二项∂i11/∂neti11
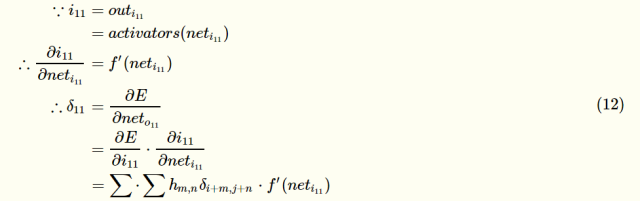
此时我们的误差敏感矩阵就求完了,得到误差敏感矩阵后,即可求权重的梯度。
由于上面已经写出了卷积层的输入neto11与权重hi,j之间的表达式,所以可以直接求出:

推论出权重的梯度:

偏置项的梯度:
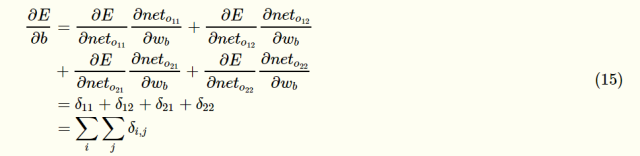
可以看出,偏置项的偏导等于这一层所有误差敏感项之和。得到了权重和偏置项的梯度后,就可以根据梯度下降法更新权重和梯度了。
池化层的反向传播
池化层的反向传播就比较好求了,看着下面的图,左边是上一层的输出,也就是卷积层的输出feature_map,右边是池化层的输入,还是先根据前向传播,把式子都写出来,方便计算:

假设上一层这个滑动窗口的最大值是outo11
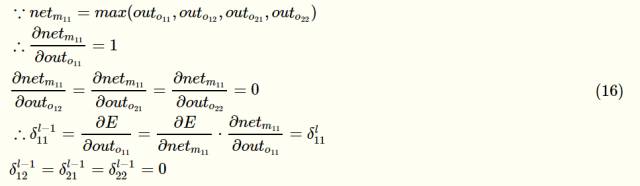
这样就求出了池化层的误差敏感项矩阵。同理可以求出每个神经元的梯度并更新权重。
手写一个卷积神经网络
1.定义一个卷积层
首先我们通过ConvLayer来实现一个卷积层,定义卷积层的超参数
class ConvLayer(object):
'''
参数含义:
input_width:输入图片尺寸——宽度
input_height:输入图片尺寸——长度
channel_number:通道数,彩色为3,灰色为1
filter_width:卷积核的宽
filter_height:卷积核的长
filter_number:卷积核数量
zero_padding:补零长度
stride:步长
learning_rate:学习率
'''
def __init__(self, input_width, input_height,
channel_number, filter_width,
filter_height, filter_number,
zero_padding, stride, activator,
learning_rate):
self.input_width = input_width
self.input_height = input_height
self.channel_number = channel_number
self.filter_width = filter_width
self.filter_height = filter_height
self.filter_number = filter_number
self.zero_padding = zero_padding
self.stride = stride
self.output_width =
ConvLayer.calculate_output_size(
self.input_width, filter_width, zero_padding,
stride)
self.output_height =
ConvLayer.calculate_output_size(
self.input_height, filter_height, zero_padding,
stride)
self.output_array = np.zeros((self.filter_number,
self.output_height, self.output_width))
self.filters = []
for i in range(filter_number):
self.filters.append(Filter(filter_width,
filter_height, self.channel_number))
self.activator = activator
self.learning_rate = learning_rate
其中calculate_output_size用来计算通过卷积运算后输出的feature_map大小
@staticmethod def calculate_output_size(input_size,
filter_size, zero_padding, stride):
return (input_size - filter_size +5
2 * zero_padding) / stride + 1
2.构造一个激活函数
此处用的是RELU激活函数,因此我们在activators.py里定义,forward是前向计算,backforward是计算公式的导数:
class ReluActivator(object):
def forward(self, weighted_input):
#return weighted_input
return max(0, weighted_input)
def backward(self, output):
return 1 if output > 0 else 0
其他常见的激活函数我们也可以放到activators里,如sigmoid函数,我们可以做如下定义:
class SigmoidActivator(object): def forward(self, weighted_input): return 1.0 / (1.0 + np.exp(-weighted_input))#the partial of sigmoiddef backward(self, output): return output * (1 - output)
如果我们需要自动以其他的激活函数,都可以在activator.py定义一个类即可。
3.定义一个类,保存卷积层的参数和梯度
class Filter(object):
def __init__(self, width, height, depth):
#初始权重
self.weights = np.random.uniform(-1e-4, 1e-4,
(depth, height, width))
#初始偏置
self.bias = 0
self.weights_grad = np.zeros(
self.weights.shape)
self.bias_grad = 0
def __repr__(self):
return 'filter weights: %s bias: %s' % (
repr(self.weights), repr(self.bias))
def get_weights(self):
return self.weights
def get_bias(self):
return self.bias
def update(self, learning_rate):
self.weights -= learning_rate * self.weights_grad
self.bias -= learning_rate * self.bias_grad
4.卷积层的前向传播
1).获取卷积区域
# 获取卷积区域
def get_patch(input_array, i, j, filter_width,
filter_height, stride):
'''
从输入数组中获取本次卷积的区域,
自动适配输入为2D和3D的情况
'''
start_i = i * stride
start_j = j * stride
if input_array.ndim == 2:
input_array_conv = input_array[
start_i : start_i + filter_height,
start_j : start_j + filter_width]
print "input_array_conv:",input_array_conv
return input_array_conv
elif input_array.ndim == 3:
input_array_conv = input_array[:,
start_i : start_i + filter_height,
start_j : start_j + filter_width]
print "input_array_conv:",input_array_conv
return input_array_conv
2).进行卷积运算
def conv(input_array,
kernel_array,
output_array,
stride, bias):
'''
计算卷积,自动适配输入为2D和3D的情况
'''
channel_number = input_array.ndim
output_width = output_array.shape[1]
output_height = output_array.shape[0]
kernel_width = kernel_array.shape[-1]
kernel_height = kernel_array.shape[-2]
for i in range(output_height):
for j in range(output_width):
output_array[i][j] = (
get_patch(input_array, i, j, kernel_width,
kernel_height, stride) * kernel_array
).sum() + bias
3).增加zero_padding
#增加Zero padding
def padding(input_array, zp):
'''
为数组增加Zero padding,自动适配输入为2D和3D的情况
'''
if zp == 0:
return input_array
else:
if input_array.ndim == 3:
input_width = input_array.shape[2]
input_height = input_array.shape[1]
input_depth = input_array.shape[0]
padded_array = np.zeros((
input_depth,
input_height + 2 * zp,
input_width + 2 * zp))
padded_array[:,
zp : zp + input_height,
zp : zp + input_width] = input_array
return padded_array
elif input_array.ndim == 2:
input_width = input_array.shape[1]
input_height = input_array.shape[0]
padded_array = np.zeros((
input_height + 2 * zp,
input_width + 2 * zp))
padded_array[zp : zp + input_height,
zp : zp + input_width] = input_array
return padded_array
4).进行前向传播
def forward(self, input_array):
'''
计算卷积层的输出
输出结果保存在self.output_array
'''
self.input_array = input_array
self.padded_input_array = padding(input_array,
self.zero_padding)
for f in range(self.filter_number):
filter = self.filters[f]
conv(self.padded_input_array,
filter.get_weights(), self.output_array[f],
self.stride, filter.get_bias())
element_wise_op(self.output_array,
self.activator.forward)
其中element_wise_op函数是将每个组的元素对应相乘
# 对numpy数组进行element wise操作,将矩阵中的每个元素对应相 def element_wise_op(array, op) for i in np.nditer(array op_flags=['readwrite']):i[...] = op(i)
5.卷积层的反向传播
1).将误差传递到上一层
def bp_sensitivity_map(self, sensitivity_array,
activator):
'''
计算传递到上一层的sensitivity map
sensitivity_array: 本层的sensitivity map
activator: 上一层的激活函数
'''
# 处理卷积步长,对原始sensitivity map进行扩展
expanded_array = self.expand_sensitivity_map(
sensitivity_array)
# full卷积,对sensitivitiy map进行zero padding
# 虽然原始输入的zero padding单元也会获得残差
# 但这个残差不需要继续向上传递,因此就不计算了
expanded_width = expanded_array.shape[2]
zp = (self.input_width +
self.filter_width - 1 - expanded_width) / 2
padded_array = padding(expanded_array, zp)
# 初始化delta_array,用于保存传递到上一层的
# sensitivity map
self.delta_array = self.create_delta_array()
# 对于具有多个filter的卷积层来说,最终传递到上一层的
# sensitivity map相当于所有的filter的
# sensitivity map之和
for f in range(self.filter_number):
filter = self.filters[f]
# 将filter权重翻转180度
flipped_weights = np.array(map(
lambda i: np.rot90(i, 2),
filter.get_weights()))
# 计算与一个filter对应的delta_array
delta_array = self.create_delta_array()
for d in range(delta_array.shape[0]):
conv(padded_array[f], flipped_weights[d],
delta_array[d], 1, 0)
self.delta_array += delta_array
# 将计算结果与激活函数的偏导数做element-wise乘法操作
derivative_array = np.array(self.input_array)
element_wise_op(derivative_array,
activator.backward)
self.delta_array *= derivative_array
2).保存传递到上一层的sensitivity map的数组
def create_delta_array(self): return np.zeros((self.channel_number, self.input_height, self.input_width))
3).计算代码梯度
def bp_gradient(self, sensitivity_array):
# 处理卷积步长,对原始sensitivity map进行扩展
expanded_array = self.expand_sensitivity_map(
sensitivity_array)
for f in range(self.filter_number):
# 计算每个权重的梯度
filter = self.filters[f]
for d in range(filter.weights.shape[0]):
conv(self.padded_input_array[d],
expanded_array[f],
filter.weights_grad[d], 1, 0)
# 计算偏置项的梯度
filter.bias_grad = expanded_array[f].sum()
4).按照梯度下降法更新参数
def update(self): '''按照梯度下降,更新权重 '''for filter in self.filters: filter.update(self.learning_rate)
6.MaxPooling层的训练
1).定义MaxPooling类
class MaxPoolingLayer(object):
def __init__(self, input_width, input_height,
channel_number, filter_width,
filter_height, stride):
self.input_width = input_width
self.input_height = input_height
self.channel_number = channel_number
self.filter_width = filter_width
self.filter_height = filter_height
self.stride = stride
self.output_width = (input_width -
filter_width) / self.stride + 1
self.output_height = (input_height -
filter_height) / self.stride + 1
self.output_array = np.zeros((self.channel_number,
self.output_height, self.output_width))
2).前向传播计算
# 前向传播
def forward(self, input_array):
for d in range(self.channel_number):
for i in range(self.output_height):
for j in range(self.output_width):
self.output_array[d,i,j] = (
get_patch(input_array[d], i, j,
self.filter_width,
self.filter_height,
self.stride).max())
3).反向传播计算
#反向传播
def backward(self, input_array, sensitivity_array):
self.delta_array = np.zeros(input_array.shape)
for d in range(self.channel_number):
for i in range(self.output_height):
for j in range(self.output_width):
patch_array = get_patch(
input_array[d], i, j,
self.filter_width,
self.filter_height,
self.stride)
k, l = get_max_index(patch_array)
self.delta_array[d,
i * self.stride + k,
j * self.stride + l] =
sensitivity_array[d,i,j]
完整代码请见:cnn.py(https://github.com/huxiaoman7/PaddlePaddle_code/blob/master/1.mnist/cnn.py)
#coding:utf-8
'''
Created by huxiaoman 2017.11.22
'''
import numpy as np
from activators import ReluActivator,IdentityActivator
class ConvLayer(object):
def __init__(self,input_width,input_weight,
channel_number,filter_width,
filter_height,filter_number,
zero_padding,stride,activator,
learning_rate):
self.input_width = input_width
self.input_height = input_height
self.channel_number = channel_number
self.filter_width = filter_width
self.filter_height = filter_height
self.filter_number = filter_number
self.zero_padding = zero_padding
self.stride = stride #此处可以加上stride_x, stride_y
self.output_width = ConvLayer.calculate_output_size(
self.input_width,filter_width,zero_padding,
stride)
self.output_height = ConvLayer.calculate_output_size(
self.input_height,filter_height,zero_padding,
stride)
self.output_array = np.zeros((self.filter_number,
self.output_height,self.output_width))
self.filters = []
for i in range(filter_number):
self.filters.append(Filter(filter_width,
filter_height,self.channel_number))
self.activator = activator
self.learning_rate = learning_rate
def forward(self,input_array):
'''
计算卷积层的输出
输出结果保存在self.output_array
'''
self.input_array = input_array
self.padded_input_array = padding(input_array,
self.zero_padding)
for i in range(self.filter_number):
filter = self.filters[f]
conv(self.padded_input_array,
filter.get_weights(), self.output_array[f],
self.stride, filter.get_bias())
element_wise_op(self.output_array,
self.activator.forward)
def get_batch(input_array, i, j, filter_width,filter_height,stride):
'''
从输入数组中获取本次卷积的区域,
自动适配输入为2D和3D的情况
'''
start_i = i * stride
start_j = j * stride
if input_array.ndim == 2:
return input_array[
start_i : start_i + filter_height,
start_j : start_j + filter_width]
elif input_array.ndim == 3:
return input_array[
start_i : start_i + filter_height,
start_j : start_j + filter_width]
# 获取一个2D区域的最大值所在的索引
def get_max_index(array):
max_i = 0
max_j = 0
max_value = array[0,0]
for i in range(array.shape[0]):
for j in range(array.shape[1]):
if array[i,j] > max_value:
max_value = array[i,j]
max_i, max_j = i, j
return max_i, max_j
def conv(input_array,kernal_array,
output_array,stride,bias):
'''
计算卷积,自动适配输入2D,3D的情况
'''
channel_number = input_array.ndim
output_width = output_array.shape[1]
output_height = output_array.shape[0]
kernel_width = kernel_array.shape[-1]
kernel_height = kernel_array.shape[-2]
for i in range(output_height):
for j in range(output_width):
output_array[i][j] = (
get_patch(input_array, i, j, kernel_width,
kernel_height,stride) * kernel_array).sum() +bias
def element_wise_op(array, op):
for i in np.nditer(array,
op_flags = ['readwrite']):
i[...] = op(i)
class ReluActivators(object):
def forward(self, weighted_input):
# Relu计算公式 = max(0,input)
return max(0, weighted_input)
def backward(self,output):
return 1 if output > 0 else 0
class SigmoidActivator(object):
def forward(self,weighted_input):
return 1 / (1 + math.exp(- weighted_input))
def backward(self,output):
return output * (1 - output)
最后,我们用之前的4 * 4的image数据检验一下通过一次卷积神经网络进行前向传播和反向传播后的输出结果:
def init_test():
a = np.array(
[[[0,1,1,0,2],
[2,2,2,2,1],
[1,0,0,2,0],
[0,1,1,0,0],
[1,2,0,0,2]],
[[1,0,2,2,0],
[0,0,0,2,0],
[1,2,1,2,1],
[1,0,0,0,0],
[1,2,1,1,1]],
[[2,1,2,0,0],
[1,0,0,1,0],
[0,2,1,0,1],
[0,1,2,2,2],
[2,1,0,0,1]]])
b = np.array(
[[[0,1,1],
[2,2,2],
[1,0,0]],
[[1,0,2],
[0,0,0],
[1,2,1]]])
cl = ConvLayer(5,5,3,3,3,2,1,2,IdentityActivator(),0.001)
cl.filters[0].weights = np.array(
[[[-1,1,0],
[0,1,0],
[0,1,1]],
[[-1,-1,0],
[0,0,0],
[0,-1,0]],
[[0,0,-1],
[0,1,0],
[1,-1,-1]]], dtype=np.float64)
cl.filters[0].bias=1
cl.filters[1].weights = np.array(
[[[1,1,-1],
[-1,-1,1],
[0,-1,1]],
[[0,1,0],
[-1,0,-1],
[-1,1,0]],
[[-1,0,0],
[-1,0,1],
[-1,0,0]]], dtype=np.float64)
return a, b, cl
运行一下:
def test():
a, b, cl = init_test()
cl.forward(a)
print "前向传播结果:", cl.output_array
cl.backward(a, b, IdentityActivator())
cl.update()
print "反向传播后更新得到的filter1:",cl.filters[0]
print "反向传播后更新得到的filter2:",cl.filters[1]
if __name__ == "__main__":
test()
运行结果:
前向传播结果: [[[ 6. 7. 5.]
[ 3. -1. -1.]
[ 2. -1. 4.]]
[[ 2. -5. -8.]
[ 1. -4. -4.]
[ 0. -5. -5.]]]
反向传播后更新得到的filter1: filter weights:
array([[[-1.008, 0.99 , -0.009],
[-0.005, 0.994, -0.006],
[-0.006, 0.995, 0.996]],
[[-1.004, -1.001, -0.004],
[-0.01 , -0.009, -0.012],
[-0.002, -1.002, -0.002]],
[[-0.002, -0.002, -1.003],
[-0.005, 0.992, -0.005],
[ 0.993, -1.008, -1.007]]])
bias:
0.99099999999999999
反向传播后更新得到的filter2: filter weights:
array([[[ 9.98000000e-01, 9.98000000e-01, -1.00100000e+00],
[ -1.00400000e+00, -1.00700000e+00, 9.97000000e-01],
[ -4.00000000e-03, -1.00400000e+00, 9.98000000e-01]],
[[ 0.00000000e+00, 9.99000000e-01, 0.00000000e+00],
[ -1.00900000e+00, -5.00000000e-03, -1.00400000e+00],
[ -1.00400000e+00, 1.00000000e+00, 0.00000000e+00]],
[[ -1.00400000e+00, -6.00000000e-03, -5.00000000e-03],
[ -1.00200000e+00, -5.00000000e-03, 9.98000000e-01],
[ -1.00200000e+00, -1.00000000e-03, 0.00000000e+00]]])
bias:
-0.0070000000000000001
PaddlePaddle卷积神经网络源码解析
卷积层
在上篇文章中,我们对paddlepaddle实现卷积神经网络的的函数简单介绍了一下。在手写数字识别中,我们设计CNN的网络结构时,调用了一个函数simple_img_conv_pool(上篇文章的链接已失效,因为已经把framework--->fluid,更新速度太快了 = =)使用方式如下:
conv_pool_1 = paddle.networks.simple_img_conv_pool(
input=img,
filter_size=5,
num_filters=20,
num_channel=1,
pool_size=2,
pool_stride=2,
act=paddle.activation.Relu())
这个函数把卷积层和池化层两个部分封装在一起,只用调用一个函数就可以搞定,非常方便。如果只需要单独使用卷积层,可以调用这个函数img_conv_layer,使用方式如下:
conv = img_conv_layer(input=data, filter_size=1, filter_size_y=1, num_channels=8, num_filters=16, stride=1, bias_attr=False, act=ReluActivation())
我们来看一下这个函数具体有哪些参数(注释写明了参数的含义和怎么使用)
def img_conv_layer(input,
filter_size,
num_filters,
name=None,
num_channels=None,
act=None,
groups=1,
stride=1,
padding=0,
dilation=1,
bias_attr=None,
param_attr=None,
shared_biases=True,
layer_attr=None,
filter_size_y=None,
stride_y=None,
padding_y=None,
dilation_y=None,
trans=False,
layer_type=None):
"""
适合图像的卷积层。Paddle可以支持正方形和长方形两种图片尺寸的输入
也可适用于图像的反卷积(Convolutional Transpose,即deconv)。
同样可支持正方形和长方形两种尺寸输入。
num_channel:输入图片的通道数。可以是1或者3,或者是上一层的通道数(卷积核数目 * 组的数量)
每一个组都会处理图片的一些通道。举个例子,如果一个输入如偏的num_channel是256,设置4个group,
32个卷积核,那么会创建32*4 = 128个卷积核来处理输入图片。通道会被分成四块,32个卷积核会先
处理64(256/4=64)个通道。剩下的卷积核组会处理剩下的通道。
name:层的名字。可选,自定义。
type:basestring
input:这个层的输入
type:LayerOutPut
filter_size:卷积核的x维,可以理解为width。
如果是正方形,可以直接输入一个元祖组表示图片的尺寸
type:int/ tuple/ list
filter_size_y:卷积核的y维,可以理解为height。
PaddlePaddle支持长方形的图片尺寸,所以卷积核的尺寸为(filter_size,filter_size_y)
type:int/ None
act: 激活函数类型。默认选Relu
type:BaseActivation
groups:卷积核的组数量
type:int
stride: 水平方向的滑动步长。或者世界输入一个元祖,代表水平数值滑动步长相同。
type:int/ tuple/ list
stride_y:垂直滑动步长。
type:int
padding: 补零的水平维度,也可以直接输入一个元祖,水平和垂直方向上补零的维度相同。
type:int/ tuple/ list
padding_y:垂直方向补零的维度
type:int
dilation:水平方向的扩展维度。同样可以输入一个元祖表示水平和初值上扩展维度相同
:type:int/ tuple/ list
dilation_y:垂直方向的扩展维度
type:int
bias_attr:偏置属性
False:不定义bias True:bias初始化为0
type: ParameterAttribute/ None/ bool/ Any
num_channel:输入图片的通道channel。如果设置为None,自动生成为上层输出的通道数
type: int
param_attr:卷积参数属性。设置为None表示默认属性
param_attr:ParameterAttribute
shared_bias:设置偏置项是否会在卷积核中共享
type:bool
layer_attr: Layer的 Extra Attribute
type:ExtraLayerAttribute
param trans:如果是convTransLayer,设置为True,如果是convlayer设置为conv
type:bool
layer_type:明确layer_type,默认为None。
如果trans= True,必须是exconvt或者cudnn_convt,否则的话要么是exconv,要么是cudnn_conv
ps:如果是默认的话,paddle会自动选择适合cpu的ExpandConvLayer和适合GPU的CudnnConvLayer
当然,我们自己也可以明确选择哪种类型
type:string
return:LayerOutput object
rtype:LayerOutput
"""
def img_conv_layer(input,
filter_size,
num_filters,
name=None,
num_channels=None,
act=None,
groups=1,
stride=1,
padding=0,
dilation=1,
bias_attr=None,
param_attr=None,
shared_biases=True,
layer_attr=None,
filter_size_y=None,
stride_y=None,
padding_y=None,
dilation_y=None,
trans=False,
layer_type=None):
if num_channels is None:
assert input.num_filters is not None
num_channels = input.num_filters
if filter_size_y is None:
if isinstance(filter_size, collections.Sequence):
assert len(filter_size) == 2
filter_size, filter_size_y = filter_size
else:
filter_size_y = filter_size
if stride_y is None:
if isinstance(stride, collections.Sequence):
assert len(stride) == 2
stride, stride_y = stride
else:
stride_y = stride
if padding_y is None:
if isinstance(padding, collections.Sequence):
assert len(padding) == 2
padding, padding_y = padding
else:
padding_y = padding
if dilation_y is None:
if isinstance(dilation, collections.Sequence):
assert len(dilation) == 2
dilation, dilation_y = dilation
else:
dilation_y = dilation
if param_attr.attr.get('initial_smart'):
# special initial for conv layers.
init_w = (2.0 / (filter_size**2 * num_channels))**0.5
param_attr.attr["initial_mean"] = 0.0
param_attr.attr["initial_std"] = init_w
param_attr.attr["initial_strategy"] = 0
param_attr.attr["initial_smart"] = False
if layer_type:
if dilation > 1 or dilation_y > 1:
assert layer_type in [
"cudnn_conv", "cudnn_convt", "exconv", "exconvt"
]
if trans:
assert layer_type in ["exconvt", "cudnn_convt"]
else:
assert layer_type in ["exconv", "cudnn_conv"]
lt = layer_type
else:
lt = LayerType.CONVTRANS_LAYER if trans else LayerType.CONV_LAYER
l = Layer(
name=name,
inputs=Input(
input.name,
conv=Conv(
filter_size=filter_size,
padding=padding,
dilation=dilation,
stride=stride,
channels=num_channels,
groups=groups,
filter_size_y=filter_size_y,
padding_y=padding_y,
dilation_y=dilation_y,
stride_y=stride_y),
**param_attr.attr),
active_type=act.name,
num_filters=num_filters,
bias=ParamAttr.to_bias(bias_attr),
shared_biases=shared_biases,
type=lt,
**ExtraLayerAttribute.to_kwargs(layer_attr))
return LayerOutput(
name,
lt,
parents=[input],
activation=act,
num_filters=num_filters,
size=l.config.size)
我们了解这些参数的含义后,对比我们之前自己手写的CNN,可以看出paddlepaddle有几个优点:
支持长方形和正方形的图片尺寸
支持滑动步长stride、补零zero_padding、扩展dilation在水平和垂直方向上设置不同的值
支持偏置项卷积核中能够共享
自动适配cpu和gpu的卷积网络
在我们自己写的CNN中,只支持正方形的图片长度,如果是长方形会报错。滑动步长,补零的维度等也只支持水平和垂直方向上的维度相同。了解卷积层的参数含义后,我们来看一下底层的源码是如何实现的:ConvBaseLayer.py有兴趣的同学可以在这个链接下看看底层是如何用C++写的ConvLayer
池化层同理,可以按照之前的思路分析,有兴趣的可以一直顺延看到底层的实现,下次有机会再详细分析。(占坑明天补一下tensorflow的源码实现)
总结
本文主要讲解了卷积神经网络中反向传播的一些技巧,包括卷积层和池化层的反向传播与传统的反向传播的区别,并实现了一个完整的CNN,后续大家可以自己修改一些代码,譬如当水平滑动长度与垂直滑动长度不同时需要怎么调整等等,最后研究了一下paddlepaddle中CNN中的卷积层的实现过程,对比自己写的CNN,总结了4个优点,底层是C++实现的,有兴趣的可以自己再去深入研究。写的比较粗糙,如果有问题欢迎留言:)
-
深度学习
+关注
关注
73文章
5219浏览量
119863 -
卷积神经网络
+关注
关注
4文章
283浏览量
11709
原文标题:【深度学习系列】卷积神经网络详解(二)——自己手写一个卷积神经网络
文章出处:【微信号:AI_shequ,微信公众号:人工智能爱好者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
卷积神经网络如何使用
【案例分享】基于BP算法的前馈神经网络
如何构建神经网络?
卷积神经网络模型发展及应用
解读多层神经网络反向传播原理
基于Numpy实现神经网络:反向传播

如何使用numpy搭建一个卷积神经网络详细方法和程序概述
卷积神经网络的权值反向传播机制和MATLAB的实现方法
浅析深度神经网络(DNN)反向传播算法(BP)
BP(BackPropagation)反向传播神经网络介绍及公式推导






 工商网监
工商网监
评论