 离散化架构WAGE,训练推理合二为一
离散化架构WAGE,训练推理合二为一
图 1 吴双(左侧)和李国齐(右侧)- 被录用文章的两位作者
清华大学类脑计算研究中心博士生吴双的论文被 ICLR2018 收录并在会上做口头报告。迄今为止,这是中国作为第一署名单位里唯一一篇被 ICLR 会议收录的口头报告文章。该报告主要探讨如何实现对全离散化深度神经网络进行训练和推理,便于部署到嵌入式设备中。
ICLR 是深度学习领域的顶会,更被誉为深度学习的“无冕之王”,得到了 google, Facebook, DeepMind, Amazon,IBM 等众多高科技公司的高度关注和参与。ICLR2018 于当地时间 2018 年 4 月 30 日在加拿大温哥华会展中心召开,为期 4 天。本次大会的主席是深度学习领域三巨头中的 Yoshua Bengio(蒙特利尔大学)和 Yann LeCun (纽约大学 & Facebook),本次大会收到一千多篇投稿文章,其中仅有 23 篇被收录为本次会议的口头报告文章。
吴双同学的报告题目为 “Training and Inference with Integers in Deep Neural Networks”。

离散化架构 WAGE,训练推理合二为一
该报告主要探讨如何实现对全离散化深度神经网络进行训练和推理,便于部署到嵌入式设备中。
在深度学习领域,高精度意味着大面积、高功耗,从而导致高成本,这背离了嵌入式设备的需求,因此硬件加速器和神经形态芯片往往采用低精度的硬件实现方式。在低精度的算法研究方面,之前的工作主要集中在对前向推理网络的权重值和激活值的缩减,使之可以部署在硬件加速器和神经形态芯片上;而网络的训练还是借助于高精度浮点实现(GPU)。这种训练和推理的分离模式往往导致需要耗费大量的额外精力,对训练好的浮点网络进行低精度转换,这不仅严重影响了神经网络的应用部署,更限制了在应用端的在线改善。
为应对这种情况,本文提出了一种联合的离散化架构 WAGE,首次实现了将离散化神经网络的反向训练过程和前向推理合二为一。具体来说就是将网络权重、激活值、反向误差、权重梯度用全用低精度整形数表达,在网络训练时去掉难以量化的操作及操作数(比如批归一化等),从而实现整个训练流程全部用整数完成。
在数据集实测中,WAGE 的离散化方法能够有效的提高测试精度。由于该方法能够同时满足深度学习加速器和神经形态芯片的低功耗和反向训练需求,更使之具备高效地在线学习的能力,对未来多场景、多目标的可迁移、可持续学习的人工智能应用将大有裨益。
WAGE框架将训练和推理中的所有层中的权重( weights ,W),激活值( activations ,A),梯度( gradients ,G)和误差( errors ,E)限制为低位整数。首先,对于操作数,应用线性映射和方向保持移位来实现三元权重,用于激活和梯度累加的8位整数。其次,对于操作,批归一化由一个常数因子取代。用于微调的其他技术(如具有动量和L2正则化的SGD优化器)可以简化或放弃,性能的下降很小。考虑到整体双向传播,我们完全简化了累积比较周期的推理,并分别训练到具有对齐操作的低位乘法累加(MAC)周期。
所提出的框架在MNIST,CIFAR10,SVHN,ImageNet数据集上进行评估。相对于只在推理时离散权重和激活的框架,WAGE具有可比的准确性,并且可以进一步减轻过拟合。WAGE为DNN生成纯粹的双向低精度整数数据流,可以将其用于专门硬件的训练和推理。我们在GitHub上发布了代码。
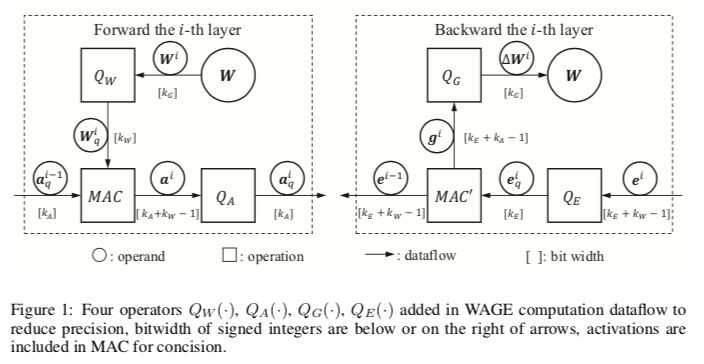
图1
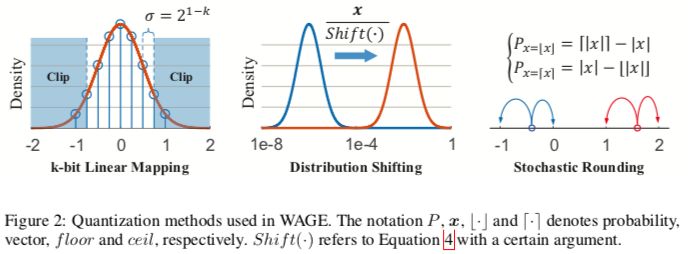
图2:WAGE的量化方法
实现细节
MNIST:采用LeNet-5的一个变体。WAGE中的学习率η在整个100个epochs中保持为1。我们报告了测试集上10次运行的平均准确度。
SVHN&CIFAR10:错误率的评估方式与MNIST相同。
ImageNet:使用AlexNe模型在ILSVRC12数据集上评估WAGE框架。
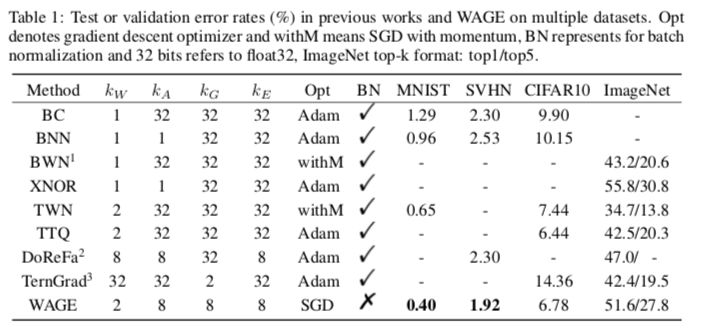
表1:WAGE及其他方法在多个数据集上的测试或验证错误率(%)

图3:训练曲线
结论和未来工作
这项工作的目标是展示在DNN中应用低位整数训练和推理的潜力。与FP16相比,8-bit整数运算不仅会降低IC设计的能耗和面积成本(约5倍,见Table 5),还会减少训练期间内存访问成本和内存大小要求,这将大大有利于具有现场学习能力的的移动设备。这个工作中有一些没有涉及到的点,未来的算法开发和硬件部署还有待改进或解决。
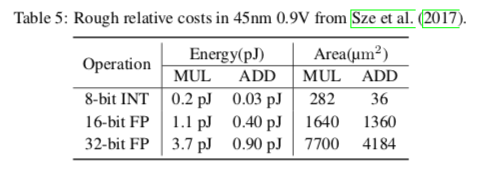
表5
WAGE使DNN的纯低位整数数据流进行训练和推理得以实现。我们引入一种新的初始化方法和分层常数比例因子来取代批归一化,这是网络量化的一个难点。此外,还探讨了误差计算和梯度累积的位宽要求。实验表明,我们可以量化梯度的相对值,并且在反向传播中丢弃大多数小值及其数量级。虽然为了稳定收敛和最终的精度,权重更新的积累是必不可少的,但仍然可以在训练中进一步减少压缩和内存消耗。WAGE在多个数据集实现了最高精度。通过微调、更有效的映射、批归一化等量化方法,对增量工作有一定的应用前景。总而言之,我们提出了一个没有浮点表示的框架,并展示了在基于整数的轻量级ASIC或具有现场学习能力的FPGA上实现离散训练和推理的潜力。
-
神经网络
+关注
关注
42文章
4562浏览量
98643 -
gpu
+关注
关注
27文章
4402浏览量
126562
原文标题:ICLR oral:清华提出离散化架构WAGE,神经网络训练推理合二为一
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何把两个电路合二为一?
模拟技术与数字技术怎样才能合二为一 电子资料
Matlab中使用S函数实现离散化数值计算的问题有哪些
用tflite接口调用tensorflow模型进行推理
图像预处理和改进神经网络推理的简要介绍
深度剖析OpenHarmony AI调度管理与推理接口
神经网络在训练时常用的一些损失函数介绍
探索一种降低ViT模型训练成本的方法
pytorch模型转为rknn后没有推理结果
如何用PyArmNN加速树莓派上的ML推理
如何提高YOLOv4模型的推理性能?
爆了!GPT-4模型架构、训练成本、数据集信息都被扒出来了

RetNet架构和Transformer架构对比分析





 工商网监
工商网监
评论