 一文读懂人工智能、机器学习、神经网络及深度学习关系
一文读懂人工智能、机器学习、神经网络及深度学习关系
前段时间看了不少关于人工智能方面的书籍博客和论坛,深深觉得了人工智能是个大坑,里面有太多的知识点和学科,要想深入绝非易事,于是萌发了自己写一些博客把自己的学习历程和一些知识点笔记都记录下来的想法,给自己一个总结收获,同时监督自己的动力,这样咱也算是“有监督学习”了:)
这里提到了“有监督学习”,在刚刚开始学习人工智能/机器学习的时候经常看到,对于这个概念从一无所知到懵懵懂懂到略有了解也花费了一点时间,对于老鸟来说这些概念都太基本了因此没有过多的篇幅来介绍,但对于新手来说,刚刚接触一个新的领域的时候往往看到的都是一个个“高大上”的名词,这种名词多了,学习曲线就陡峭了,因此我们还是从基本的概念开始整理整理吧。因此这篇笔记就是一个基本概念的梳理,若有不恰的地方望不吝赐教。
人工智能,机器学习,神经网络,深度学习的关系
刚刚接触人工智能的内容时,经常性的会看到人工智能,机器学习,深度学习还有神经网络的不同的术语,一个个都很高冷,以致于傻傻分不清到底它们之间是什么样的关系,很多时候都认为是一个东西的不同表达而已,看了一些具体的介绍后才渐渐有了一个大体的模型。
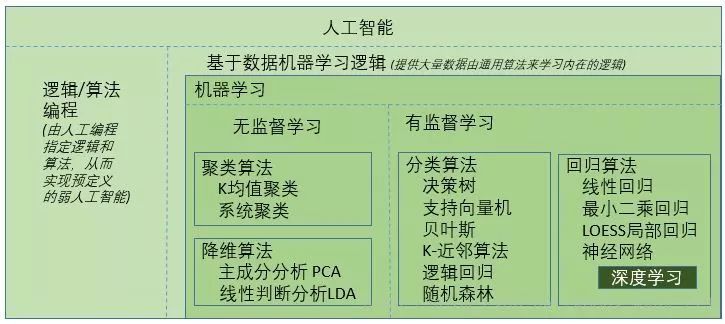
机器学习
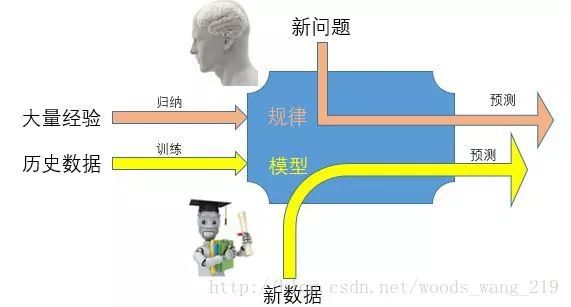
机器学习是人工智能最重要的内容,先来看看它的一个定义(当然有很多不同的定义):“Machine learning is the idea that there are generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, youfeed datato thegeneric algorithmand itbuilds its own logicbased on the data.”这里面有几个重要的关键词,就是你不用写专门的业务逻辑代码而是通过输入大量的数据给机器,由机器通过一个通用的机制来建立它自己的业务逻辑,也就是机器“自我学习”了业务的逻辑,当然这种学习后的逻辑可以用来处理新的数据。这和人类的学习过程有些类似,如下图:
有监督学习和无监督学习
这两个概念也是刚刚接触机器学习经常碰到的概念,通俗/简单点来说,所谓有监督学习就是训练用历史数据是既有问题又有答案,而无监督学习就是训练用历史数据是只有问题没有答案。正式的说法一般是把答案称之为标签label还有一种介于两者之间的混合学习方法,称为半监督学习
在无监督学习中,主要是发现数据中未知的结构或者是趋势。虽然原数据不含任何的标签,但我们希望可以对数据进行整合(分组或者聚类),或是简化数据(降维、移除不必要的变量或者检测异常值)。因此无监督算法主要的分类包含:- 聚类算法 (代表:K均值聚类,系统聚类)- 降维算法 (代表:主成份分析PCA,线性判断分析LDA)
有监督学习,可以根据预测变量的类型再细分。如果预测变量是连续的,那这就属于回归问题。而如果预测变量是独立类别(定性或是定类的离散值),那这就属于分类问题了。因此有监督学习主要的分类包含:- 回归算法 (线性回归,最小二乘回归,LOESS局部回归,神经网路,深度学习)- 分类算法(决策树,支持向量机,贝叶斯,K-近邻算法,逻辑回归,随机森林)
这里面提到了很多的算法,目前还不需要一一去掌握,相信在今后的学习中会经常看到,先混个眼熟:)
这些所有的算法中,目前最热的恐怕是深度学习了,但要了解深度学习必须先了解它的前任(前生,父类)。
神经网络
关于神经网络的介绍在网上有很多很多了,有不少大牛的介绍和课程,本人主要参考/推荐如下:神经网络浅讲:从神经元到深度学习用平常语言介绍神经网络因此不再赘述细节,做了一个不完全的总结图: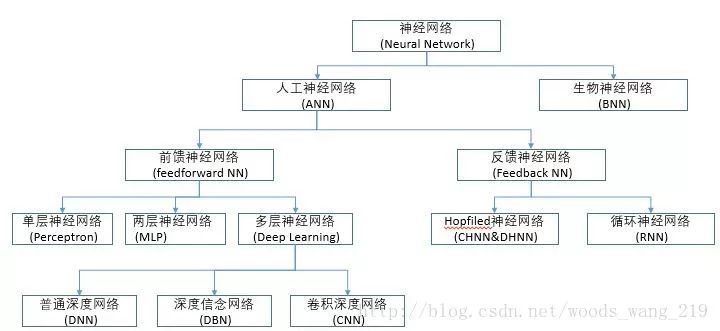
好了,大体的一个机器学习的最最基本的概念总结完毕,其实学习这些基本概念还是比较简单方便的,毕竟我们有强大的搜索引擎,只要输入“机器学习”就能得到海量的知识让我们去学习,不过对于刚开始的初学者来说,先浅尝即止即可,有了一个框架性的了解,为后续的深入学习做准备。
-
神经网络
+关注
关注
42文章
4562浏览量
98646 -
人工智能
+关注
关注
1775文章
43716浏览量
230494 -
机器学习
+关注
关注
66文章
8095浏览量
130518 -
深度学习
+关注
关注
73文章
5224浏览量
119866
原文标题:人工智能学习笔记-基本概念
文章出处:【微信号:Imgtec,微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【专辑精选】人工智能之神经网络教程与资料
人工智能AI-深度学习C#&LabVIEW视觉控制演示效果
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步
卷积神经网络简介:什么是机器学习?

人工智能、机器学习、神经网络和深度学习的关系究竟是什么?





 工商网监
工商网监
评论