 谷歌TPU2和英伟达V100的性能详细对比
谷歌TPU2和英伟达V100的性能详细对比
本文详细对比了谷歌TPU2和英伟达V100的性能,有两个对比方向:一是测试在没有增强过的合成数据上的吞吐量(每秒图像);二是,考察ImageNet上两者实现的精确性和收敛性。结果在ResNet-50模型的原始表现上,4块TPU2芯片和4块V100GPU速度相同。训练ResNet-50时谷歌云TPU的实现用时短到令人发指,且基于ImageNet数据集的图像分类准确度达76.4%的成本只要73美元,说物美价廉可能也不过分。
去年5月,谷歌推出了第二代TPU芯片,这是一个自定义开发的深度学习加速芯片,不少人认为有望成为英伟达GPU的替代品。
可事实真的如此么?
在这篇文章中,作者详细对比了谷歌TPU2和英伟达V100的性能。孰优孰劣,一较便知~
环境设置
话不多说直接上干货了。下面我们就先比较由四个TPU芯片组成的TPU2组合板与四个英伟达V100 GPU的环境设置的差别。
巧的是,因为两者的总内存均为64G,因此我们能够用同一个模型测试了,还能使用相同的batch size,节省了不少工夫呢。
在这次实验中,我们用相同的方式训练模型,双方需要运行同步数据并行分布式训练。
最后,我们选中了ImageNet上的ResNet-50模型进行测试。它实际上是图像分类的一个参考点,虽然参考实现是公开的,但目前还没有一个支持在云TPU和多个GPU上训练的单一实现。
先看看V100这一边,英伟达建议用MXNet或TensorFlow来实现,两者都可以在英伟达GPU云上的Docker映像中使用。
但实际的操作中我们却发现了一些问题,这要是两种实现不能很好融合多个GPU和产生的大型batch size。
好在我们还有一些新发现,从TensorFlow的基准存储库中使用ResNet-50实现,并在Docker映像中运行它是可行的。这种方法比英伟达的推荐的TensorFlow实现要快得多,只比MXNet实现稍微慢一点(约3%)。这样一来,也更容易在相同版本中用同一个框架的实现做对比。
再看看谷歌云TPU这一边,官方建议用带TensorFlow 1.7.0官方TPU存储库的bfloat16实现。TPU和GPU实现都在各自的体系架构上使用混合精度计算,但大部分张量是以半精度的方式储存的。
一翻研究和对比后……我们终于敲定了实验方案。
对于V100来说,我们决定用AWS上的p3.8xlarge实例(Xeon E5-2686@2.30GHz 16内核,244GB内存,Ubuntu16.04),用4个单个内存为16GB的V100 GPU进行测试。
TPU这边的测试,我们将小型的n1-standard-4实例作为host(Xeon@2.3GHz两核,15GB内存,Debian 9),我们提供了一个云TPU,由4个单个内存为16G的TPU2芯片组成。
方案敲定后,我们又规划了两个对比方向。
一是我们要测试在没有增强过的合成数据上的吞吐量(每秒图像)。这种比较独立于收敛性,保证里了在I/O或数据增强中没有瓶颈bottleneck影响结果。
二是,我们要考察ImageNet上两者实现的精确性和收敛性。
目标,明确,方法,明确。我们迫不及待开始测试了——
吞吐量测试
我们依据每秒合成数据上的图像来测量吞吐量,即在训练数据实时创建、batch size也不同的情况下对吞吐量进行检测。
虽然~官方只推荐的TPU的batch size是1024,但是基于读者的请求,我们还报告了其他batch size大小的性能。
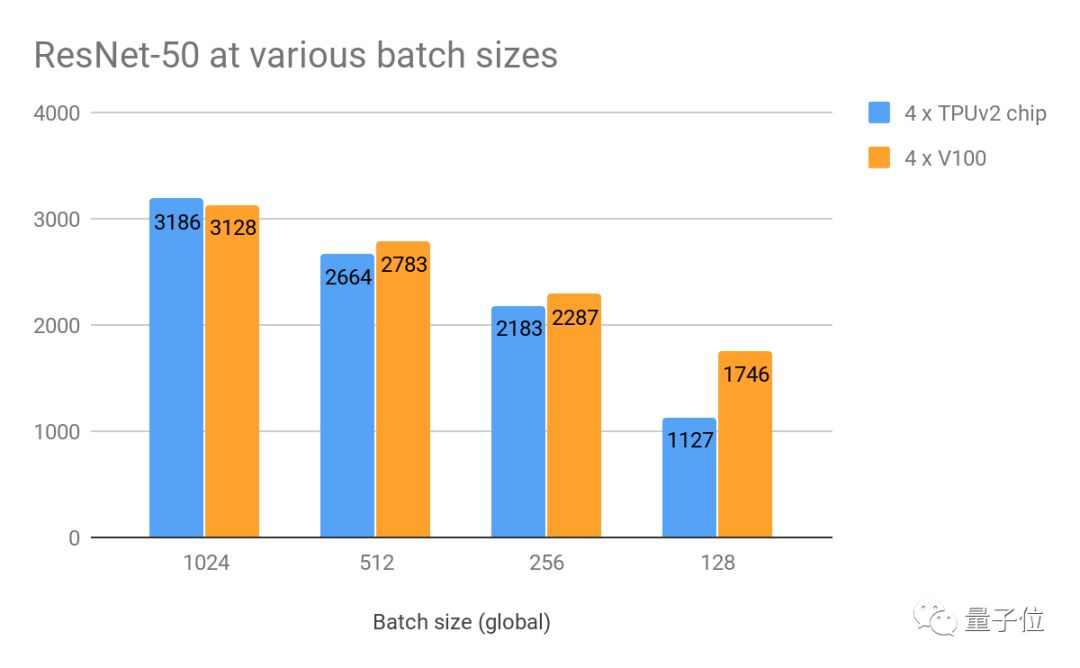
△在合成数据和w/o数据增强的不同批次上每秒的图像性能
在batch size为1024的情况下,双方的吞吐量旗鼓相当,TPU略领先2%。
当batch size较小时,在双方吞吐量均降低,但对比起来GPU的性能稍好一些。看来,这些batch size真的不是TPU的推荐设置~
根据英伟达的建议,我们还也在MXNet上做了一个GPU测验。
利用英伟达GPU云上Docker映像中提供的ResNet-50实现(mxnet:18.03-py3),我们发现在batch size为768的情况下,GPU每秒能处理约3280个图像。这比上面最好的TPU结果还要快3%。
也正如上面所说的那样,在上述batch size下,MXNet的实现在多个GPU上并没有很好聚合。所以,我们接下来研究的重点就是这就是为什么我们将重点就是TensorFlow的实现。
性价比
上面我们也提到过,谷歌云TPU2一组有四块芯片,目前只在谷歌云上才能用到。
当需要进行计算时,我们可以将它与虚拟机相连。考虑到谷歌云上不支持英伟达V100,所以其云服务只能来自AWS。
基于上述结果,我们可以把数据标准化,从每小时的花费、每秒处理的图片数量、每美元能处理的图片数三个维度进行对比。
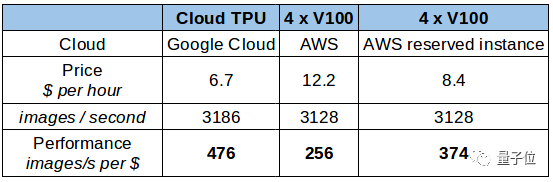
△每美元每秒处理图像的表现
对比下来,谷歌云TPU性价比略高。不过,谷歌TPU目前不卖,只能租。如果你考虑长期租用,或者购买的话,结论就不一样了。
有一点你可能忘了,上面这张表的前提是假定了我们的租期为12个月,所以费用中包含了AWS上p3.8xlarge实例,并且不需要提前支付定金。这样大大降低了价格,还能达到每美元能处理375张图片的不错效果。
其实对于GPU来说,还有更多的选择。比方说,Cirrascale提供4台V100GPU服务器的月租服务,收费大概是7500美元,折算下来是每小时10.3美元。
不过,因为AWS上像CPU、内存、NVLink支持等硬件类型也各不同,如果要更直接的对比,就需要更多的参考数据。其他费用套餐可参考:
http://www.cirrascale.com/pricing_x86BM.php
精准度和收敛程度
除了原始的表现,我们还希望有效验证的计算能力。比方说,实现收敛的结果。因为比较的是两个不同的实现,所以可以预期到结果会有不同。比较的结果不仅仅是硬件的速度,也包含实现的质量。
比方说,TPU实现的过程中应用到了计算密集的图像预处理步骤,并且还牺牲了原始的吞吐量。下面我们也能看到,谷歌的这种选择有不错的回报。
我们用ImageNet数据集训练这些模型,想把图像进行分类。目前,这个数据集中的类别已经细分到了1000种,包含了130万张训练图片,5万张验证图片。
我们在batch size为1024的情况下进行训练,进行了90次迭代后在验证集上对比双方的结果。
结果显示,TPU可以每秒完成2796张图,GPU则为2839张。这个结果和我们上面提到的吞吐量不同,是因为上面我们禁用了数据增强,并用合成数据来比较的TPU和GPU的原始速度。
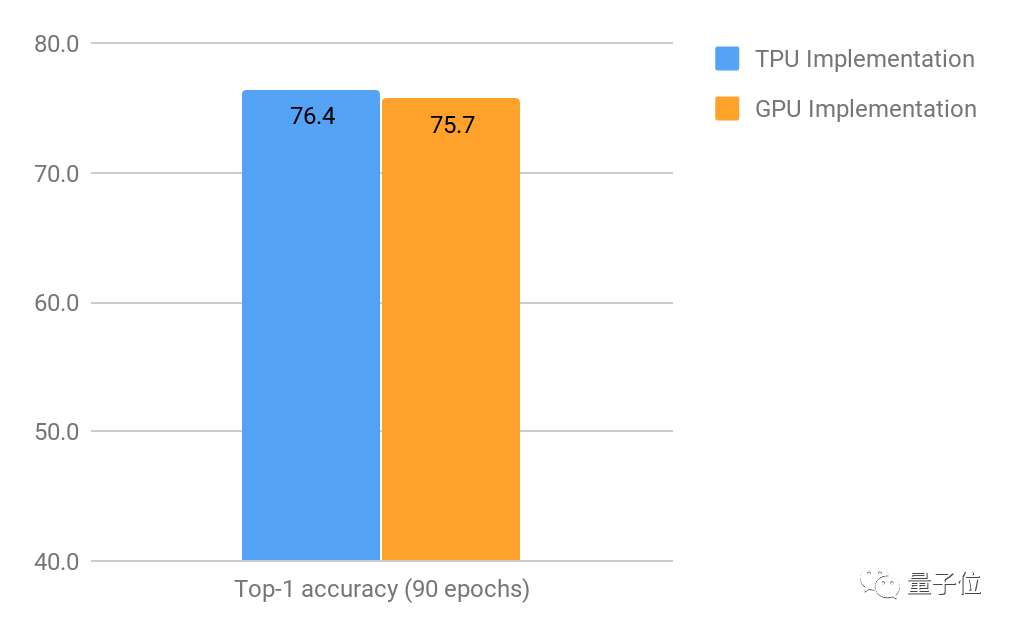
△90次训练之后,Top-1 精确值*(只考虑每张图最高的预估)
从上图可以看出来,90次训练之后,TPU实现的Top-1精准度要好过GPU,有0.7%的优势。
虽然0.7%的优势看起来非常微小,但在如此高水平的情况下还有这样的改进非常难,基于不同的应用个,这点改进将对最后的结果有很大影响。
接下来,我们看一下不同训练时期,模型Top-1精准度的表现。
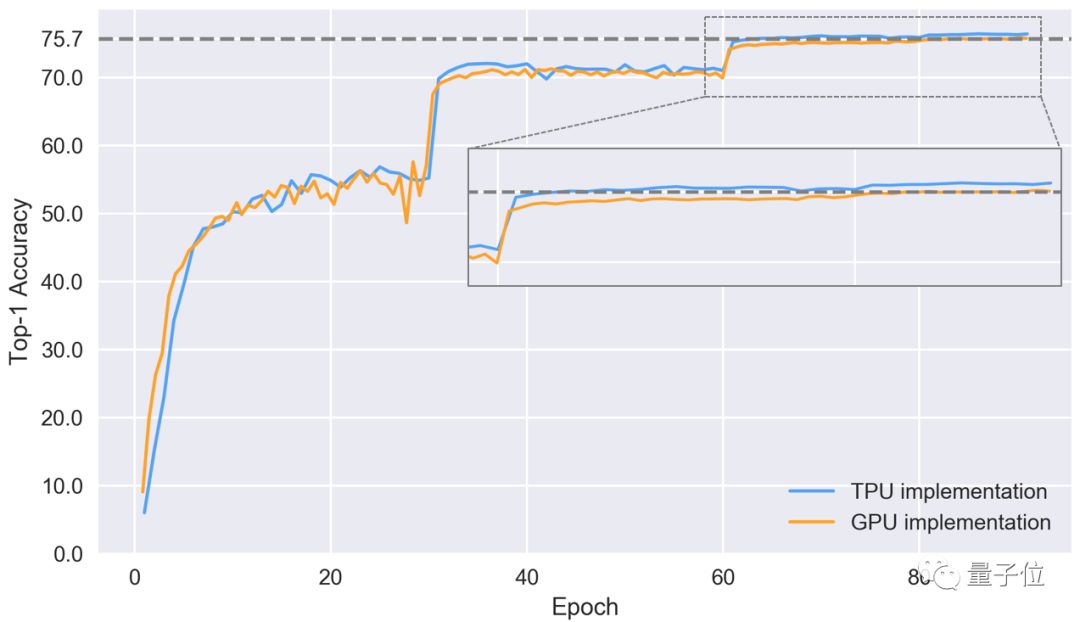
△在验证集上,两种方法实现Top-1精准度的表现
可以看出,图表中有一段精准度陡增,和学习速率高度同步。TPU实现的收敛表现更好,最后到第86次训练时,准确率可以达到76.4%。
GPU的表现就被甩在了后面,第84次训练后达到了75.7%的准确率,而TPU早在第64次训练时就达到了这个水平。
TPU有更好的表现,很可能要归功于前期的预处理和数据增强。不过我们需要更多的实验来验证这个猜想。
基于成本价格提出的解决方案
我们最终需要考虑的,一是整个流程走下来的时间,二是它需要耗费多少资金。如果我们假设最后可接受的准确率为75.7%,那么可以根据每秒训练速度和既定要求的训练次数,算出来达到这个标准所需的成本。时间方面需要注意,不包括训练启动用时,以及训练期间的模型验证用时。
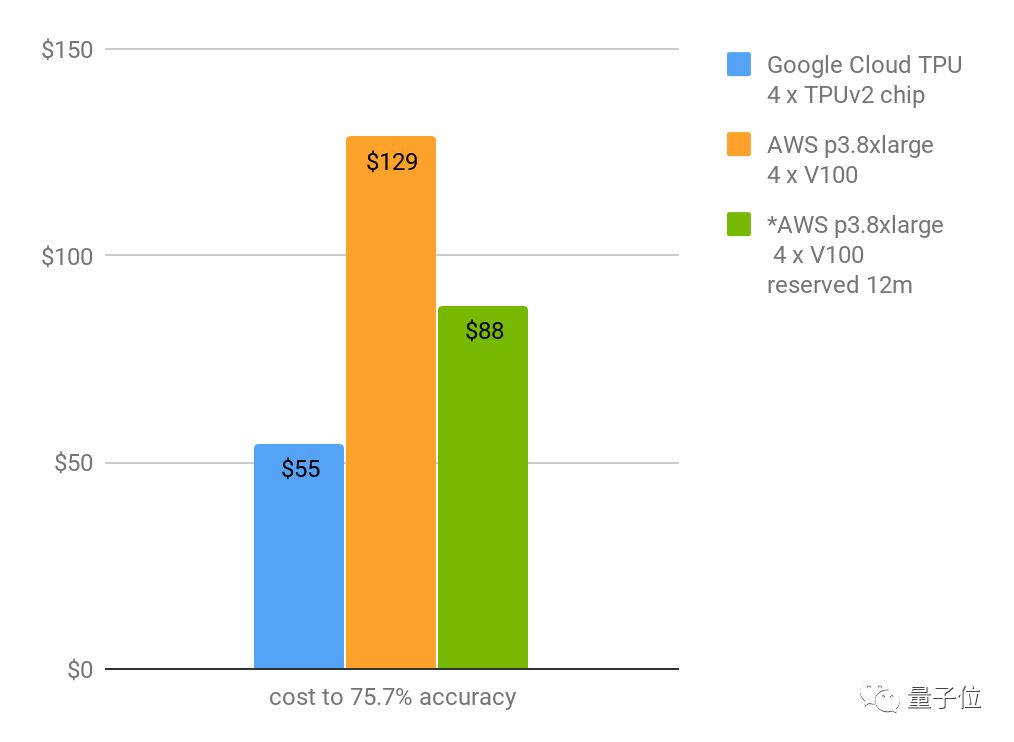
△达到75.1%Top-1准确率所需成本 | *表示租期为12个月
上图显示,谷歌TPU从零训练图像分类模型的成本是55美元(且训练时间用了不到9小时)!收敛到76.4%的话成本将达到73美元。
而英伟达V100速度差不多快,但成本会更高,收敛速度也比较慢,不是个性价比高的解决方案~
对了,我们这个结论是基于实现的质量、云的价格来对比得出的。其实还有另外一个维度可以来比较,即算力的损耗。不过因为我们缺乏二代TPU算力损耗的公开信息,这方面的对比先不做了啦。
总结
按我们上述的衡量标准来看,在ResNet-50模型的原始表现上,4块TPU2芯片和4块V100GPU是速度相同。
目前来说,训练ResNet-50时谷歌云TPU的实现用时短到令人发指,且基于ImageNet数据集的图像分类准确度达76.4%的成本只要73美元,说物美价廉可能也不过分~
-
谷歌
+关注
关注
27文章
5845浏览量
103245 -
gpu
+关注
关注
27文章
4410浏览量
126635 -
TPU
+关注
关注
0文章
131浏览量
20532 -
英伟达
+关注
关注
22文章
3316浏览量
87716
原文标题:谷歌TPU2代有望取代英伟达GPU?测评结果显示…
文章出处:【微信号:IV_Technology,微信公众号:智车科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
谷歌发布多模态Gemini大模型及新一代TPU系统Cloud TPU v5p

升腾910和v100性能参数对比
升腾910和英伟达h100对比
英伟达v100与A100的差距有哪些?
英伟达h800和a100参数对比
英伟达A100的算力是多少?
英伟达A100和A40的对比

通往AGI之路:揭秘英伟达A100、A800、H800、V100在高性能计算与大模型训练中的霸主地位

物联网行业通用主板—卓越V100






 工商网监
工商网监
评论