 语音识别任务中除了模型以外的可以提升性能的技巧
语音识别任务中除了模型以外的可以提升性能的技巧
端对端语音识别改进的规则技巧
对于端对端模型来说,通过数据增强和Dropout的方法可以提高模型的性能。在语音识别中也是如此,之前,我公众号没有写过关于语音识别任务的数据增强的技巧,最近做了大规模的语音识别实践发现,数据增强对于小数据集而言简直就是雪中送炭,当然,如果你拥有大体量的数万小时的语音数据库,而且又能囊括全国各地不同口音风格,那么数据增强理论上也能起到锦上添花的作用。今天基于Salesforce Research的这篇文章以及自己平时的实践经验,来分享一下语音识别任务中除了模型以外的可以提升性能的技巧。
这篇论文中提到,通过对音频的速度、音调、音量、时间对齐进行微小的扰动,以及通过增加高斯白噪声来对音频进行改动,同时,文章也探讨了在每一层神经网络上采用dropout所带来的效果。实验结果表明,通过将数据增强技术与dropout联合使用,可以将语音识别模型的性能在WSJ数据库上和LibriSpeech数据库上相比baseline系统提高20%以上,从结果上看,这些规则化技巧对语音识别的性能改进有很大的帮助。我们先看一下作者基于什么模型来实践这些数据增强的技巧。
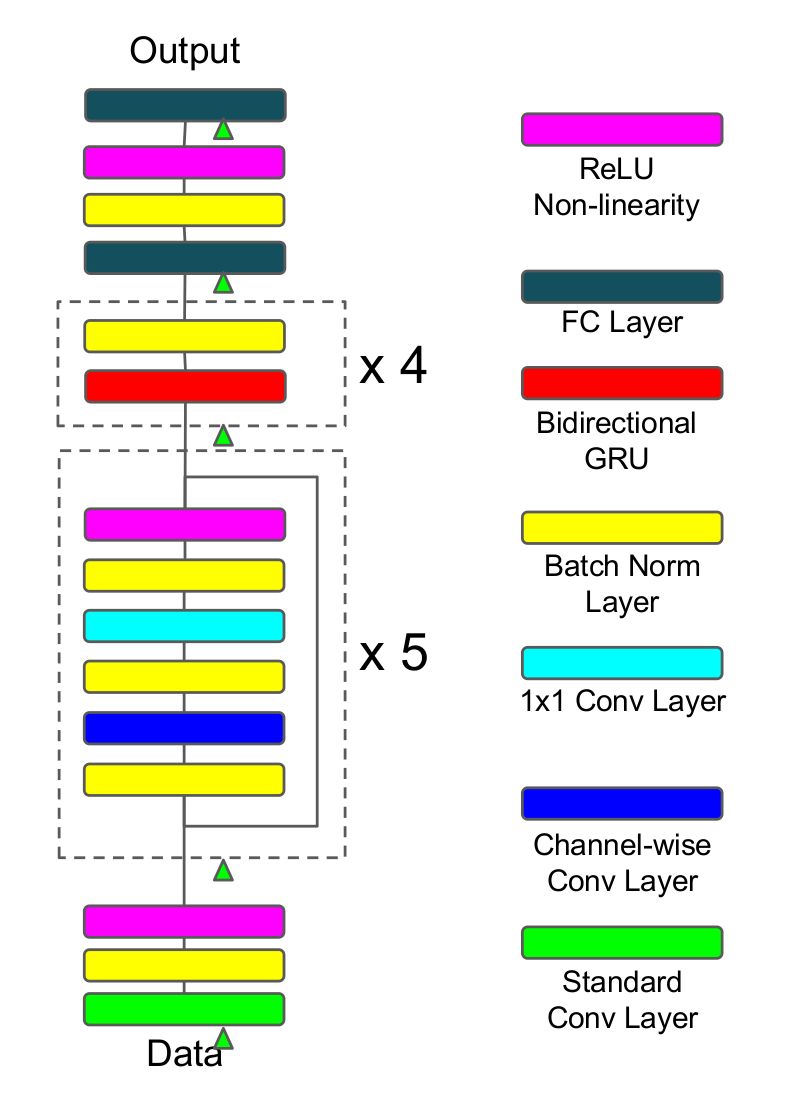
本文使用的端对端模型非常接近于百度提出的Deep Speech2 (DS2),如上图所示,原始特征数据首先经过一个较大卷积核的卷积层,卷积核较大的好处就是对原始特征进行降维,降维以后通过5个残差连接区,而每一个残差区都是由批归一化层、channel-wise卷积层和1×1的卷积层构成,并通过relu激活函数,紧接着连上4个双向GRU网络,最终通过全连接层得到目标概率分布,并采取端对端的CTC损失函数作为目标函数,使用随机梯度下降算法来进行优化。这里相比DS2所做的创新主要是channel-wise可分离的卷积层,其实就是depth-wise可分离卷积层,它相比常规的卷积具有性能好、参数减少的优势,它们在参数数量上的区别可以通过下面的例子看得出来(具体关于可分离卷积的介绍,可以搜索xception这篇文章):
假设现在要做一个卷积,输入深度是128,输出深度是256;常规的操作使用卷积核3×3进行卷积,那么参数数目为128×3×3×256=294912;depth-wise可分离卷积的操作是设置depth multiplier=2得到深度为2×128的中间层,再经过1×1的卷积层降维到深度为256,参数数目为128×3×3×2+128×2×1×1×256=67840,可以看到相比常规卷积,参数减少了77%;
除了使用了depth-wise可分离卷积层以外,残差连接以及在每一层上都采取了批归一化的技巧对训练有促进作用,整个网络共有约500万个参数。参数太大就容易出现过拟合的问题,为了避免过拟合,作者尝试探索了数据增强和dropout两种技巧来提升系统的性能。
1. 数据增强
在此之前,Hinton曾经提出使用Vocal Tract Length Perturbation (VTLP)的方法来提升语音识别的性能,具体的做法就是在训练阶段对每一个音频的频谱特征施加一个随机的扭曲因子,通过这种做法Hinton实现了在TIMIT小数据集上的测试集表现提升了0.65%,VTLP是基于特征层面所做的数据增强技巧,不过后来也有人发现通过改变原始音频的速度所带来的性能提升要比VTLP好。但是音频速度的快慢实际上会影响到音调(pitch),所以提高了音频的速度必然也就增大了音频的音调。反过来也是,降低了音频的速度就会使得音频的音调变小。所以,仅仅通过调节速度的方法就不能产生速度快同时音调低的音频,这就使得音频的多样性有所降低,对语音识别系统的性能提升有限。作者在本文中希望能够通过数据增强来丰富音频的变化,提升数据的数量和多样化,于是作者采取将音频的速度通过两个单独的变量来控制,它们分别是tempo和pitch,也就是节奏和音高,对音频的节奏和音高的调节可以通过语音的瑞士军刀——SOX软件来完成。
除了改变tempo和pitch以外,作者还添加了高斯白噪声、改变音频的音量以及随机对部分原始音频的采样点进行扭曲操作。
2. dropout
dropout是Hinton提出来的一种防止深度神经网络出现过拟合的技巧,它的做法是在训练神经网络的时候随机地让某些神经元的输入变为0,公式如下所示,通过生成一个概率为1-p的伯努利分布再与神经元的输入进行点乘,即可得到dropout以后的输入;而在推理阶段,我们只需要对输入乘以伯努利分布的期望值1-p即可。dropout对于前向神经网络作用很明显,但是应用到循环神经网络中的时候,很难取得较好的效果。
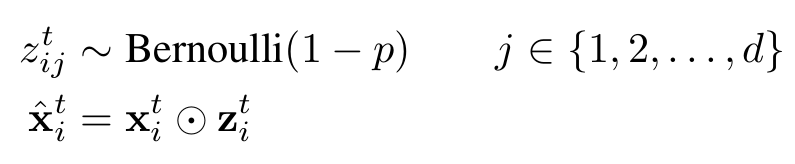
作者在本文中采取的dropout是不随时间变化的,即对于一个序列的不同时刻,产生dropout的伯努利分布是共享的,而在推理阶段,仍然是乘以伯努利分布的期望值1-p。作者在卷积层和循环层都是采取了这个变种的dropout,而在全连接层则是采取了标准的dropout。
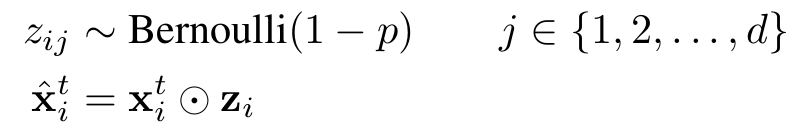
3. 实验细节
作者采取的数据集是LibriSpeech和WSJ,输入到模型的特征是语音的频谱图(spectrogram),以20ms为一帧,步长设为10ms。同时,作者对特征做了两个层次的归一化,分别是把频谱图归一化成均值为0标准差为1的分布,以及对每一个特征维度进行同样的归一化,不过这个特征维度的归一化是基于整体训练集的统计来做的。
数据增强部分,作者基于tempo的增强参数是取自(0.7, 1.3)的均匀分布,基于pitch的增强参数是取自(-500, 500)的均匀分布,添加高斯白噪声的时候将信噪比控制在10-15分贝,同时在调整速度方面,作者分别使用了0.9,1.0和1.1作为调整的系数。综合上面所有数据增强技巧,如下图所示,模型的性能相比没有这些技巧的baseline提高了20%。
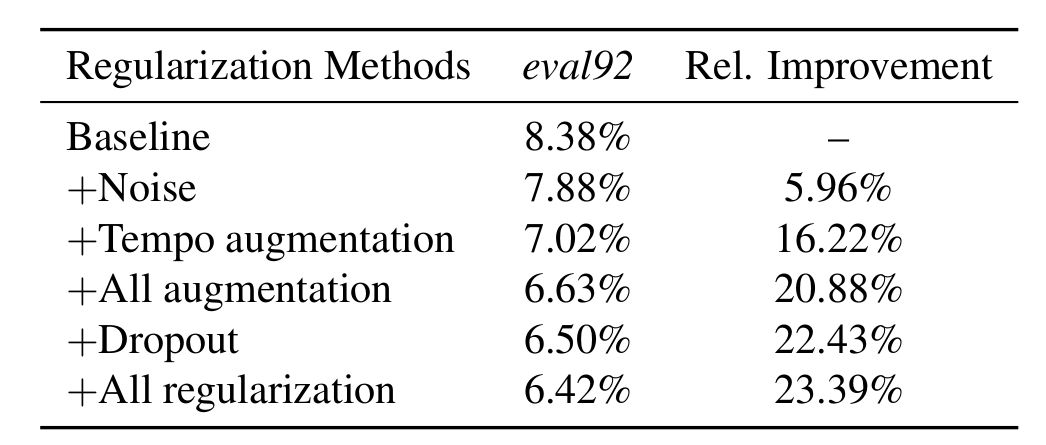
dropout同样提升了模型的性能,dropout概率作者对数据设置了0.1,对卷积层设置了0.2,对所有的循环层和全连接层设置了0.3,通过dropout,模型性能提高了22.43%,结合dropout和数据增强,模型整体性能提高了23.39%。
4. 总结
本文应该是对语音识别中的数据增强和规则化技巧做了总结,虽然实验用的数据集是时长比较短的数据集,但是这些数据集对于我们部署一个实际的语音识别系统也很重要。对于中文普通话语音识别而言,不论是不同人说话的语速、语调,还是不同地方的人说普通话的口音,这些导致语音识别的难度非常大,如果想去采集各个地方不同人所说的普通话语料,对于小公司或者小团队而言,是非常不现实的一件事情。所以,如何基于有限的普通话语料去使用数据增强算法来人工构建一个可以模拟全国各个地方不同口音分布的强大语料是一个不得不面对的实际难题,而解决了这个难题实际上也就能极大程度地提升语音识别的鲁棒性。
-
端对端
+关注
关注
0文章
3浏览量
7842 -
语音识别
+关注
关注
37文章
1635浏览量
111822
原文标题:改进语音识别性能的数据增强技巧
文章出处:【微信号:DeepLearningDigest,微信公众号:深度学习每日摘要】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于网络性能的VoIP语音质量评价模型
语音识别控制在音频、视频系统中的应用
【Nuvoton ISD9160语音识别试用体验】ISD9160语音识别代码分析
阿里开源自主研发AI语音识别模型
关于多任务学习如何提升模型性能与原则
重塑翻译与识别技术:开源语音识别模型Whisper的编译优化与部署






 工商网监
工商网监
评论