 DeepMind提出强化学习新算法,教智能体从零学控制
DeepMind提出强化学习新算法,教智能体从零学控制
这在真实环境中成功让机械臂从头开始学习拾放物体。SAC-X 是基于从头开始学习复杂的任务这种想法,即一个智能体首先应该学习并掌握一套基本技能。就像婴儿在爬行或走路前必须具有协调能力和平衡能力,为智能体提供与简单技能相对应的内在目标(具有辅助作用),这会增加它理解和执行更复杂任务的可能性。
研究者认为,SAC-X是一种通用的强化学习方法,未来可以应用于机器人以外的更广泛领域。
不管你让小孩还是大人整理物品,他们很大可能都不会乖乖听你的话,如果想要让 AI 智能体进行整理收拾,那就更难了。如果想成功,需要掌握如下几个核心视觉运动技能:接近物体,抓住并举起它,打开盒子,把物体放进去。而更复杂的是,执行这些技能时,必须按照正确的顺序。
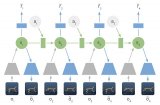
对于一些控制类的任务,比如整理桌面或堆叠物体,智能体需要在协调它的模拟手臂和手指的九个关节时,做到三个 W,即如何(how),何时(when)以及在哪里(where),以便正确地移动,最终完成任务。
在任何给定的时间内,需要明确各种可能的运动组合的数量,以及执行一长串正确动作,这些需求引申出一个严肃的问题,这成为强化学习中一个特别有趣的研究领域。
诸如奖赏塑形(reward shaping)、学徒学习(Apprenticeship learning)或从演示中学习(Learning from Demonstration)等技术可以帮助解决这个问题。然而,这些方法依赖于大量与任务相关的知识,而从零开始,通过最少的预先知识学习复杂的控制问题仍然是一个众所周知的挑战。
我们最近的论文提出了一种新的学习范式,叫做「调度辅助控制」(Scheduled Auxiliary Control (SAC-X)),我们试图通过这种学习范式来克服这个问题。
SAC-X 是基于从头开始学习复杂的任务这种想法,即一个智能体首先应该学习并掌握一套基本技能。就像婴儿在爬行或走路前必须具有协调能力和平衡能力,为智能体提供与简单技能相对应的内在目标(具有辅助作用),这会增加它理解和执行更复杂任务的可能性。
我们在几个模拟和真实的机器人任务中演示了 SAC-X 法,包括不同物体的堆叠,将物体放到盒子里。我们定义的辅助任务遵循一般原则:鼓励智能体探索其感应空间。
例如,激活手指上的触觉传感器,感知手腕的力度,利用本体感应器将关节角度调到最大,在视觉传感器范围内强制性移动物体。对于每个任务,如果实现目标,会提供相应的简单奖励。没实现目标的话,奖励为零。
智能体首先学习激活手指上的触觉传感器,然后移动物体
模拟智能体最终掌握复杂的堆叠任务
智能体接下来可以自行决定其当前的「意图」,例如下一步做什么。可能会是一个辅助任务或者是外部定义的目标任务。至关重要的是,对于目前还没有使用基于回放的离策略学习方法的任务,该代理可以从奖励信号中发现和学习。例如,当拾取或移动一个物体时,智能体可能会偶然地将物体堆叠起来,观察到「堆叠奖励」。一系列简单的任务会让智能体观察到罕见的外部奖励,所以让智能体具有安排意图的能力至关重要。
基于收集到的所有的间接知识,智能体会建立一个个性化的学习课程。在如此大的领域中,通过这种方法来利用知识非常高效,在只有很少的外部奖励信号的情况下尤其有用。
通过调度模块,智能体会决定接下来的意图。利用元学习算法,调度器会在训练过程中得到改进,该算法试图最大限度地提高主任务的进程,进而显著提高数据效率。
在探索完许多内部辅助任务之后,智能体学会了如何堆叠和整理物品
评估表明,SAC-X 能够从零开始完成我们设置的所有任务,这些任务都是在相同的辅助任务集下完成的。令人兴奋的是,利用 SAC-X,我们实验室的机器人手臂能够成功地从零开始学习拾取和摆放。在过去这极具挑战性,因为在现实世界中让机器人学习需要高效的数据,所以流行的方法是预训练模拟智能体,然后再将这种能力转移到真正的机器人手臂中。
针对真实的机器人手臂, SAC-X 能学习如何举起和移动绿色的立方体,在此之前它从来没有接触过这类任务
我们认为 SAC-X 是通向从零学习控制任务的重要一步,只需定义好整体目标。SAC-X 允许任意定义辅助任务,这些任务可以基于一般的看法(如有意激活传感器),最终会涵盖研究人员认为重要的任务。从这方面来说,SAC-X 是一种通用的强化学习方法,可以广泛应用于控制和机器人领域之外的一般稀疏强化学习环境。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
-
算法
+关注
关注
23文章
4454浏览量
90747 -
人工智能
+关注
关注
1776文章
43824浏览量
230584
原文标题:DeepMind提出强化学习新算法,教智能体从零学控制
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
什么是深度强化学习?深度强化学习算法应用分析

未来的AI 深挖谷歌 DeepMind 和它背后的技术
将深度学习和强化学习相结合的深度强化学习DRL
谷歌、DeepMind重磅推出PlaNet 强化学习新突破
懒惰强化学习算法在发电调控REG框架的应用
DeepMind发布强化学习库RLax
机器学习中的无模型强化学习算法及研究综述

强化学习的基础知识和6种基本算法解释
强化学习的基础知识和6种基本算法解释

基于强化学习的目标检测算法案例
语言模型做先验,统一强化学习智能体,DeepMind选择走这条通用AI之路

模拟矩阵在深度强化学习智能控制系统中的应用






 工商网监
工商网监
评论