 生成英文维基百科文章的方法可以概述为源文档的多文档摘要
生成英文维基百科文章的方法可以概述为源文档的多文档摘要
最近,经过研究证明,生成英文维基百科(English Wikipedia)文章的方法可以概述为源文档的多文档摘要。我们使用抽取式文摘(extractive summarization)来粗略地识别出显要的信息,以及一个神经抽象模型以生成文章。对于抽象模型,我们引入了一个只能解码的体系结构,它可以扩展性地处理非常长的序列,远比用于序列转换中的典型的编码器——解码器体系结构长得多。我们的研究表明,这个模型可以生成流畅、连贯的多句话段落,甚至整个维基百科的文章。当给出参考文献时,研究结果表明,它可以从诸如复杂度、ROUGE分数和人类评价所反映的信息中提取出相关的事实信息。
序列—序列框架已被证明在诸如机器翻译这样的自然语言序列转换任务上取得了成功。最近,神经技术已经被应用于对新闻文章进行单一文档、抽象(释义)文本摘要的处理。在此前的研究中,监督模型的输入范围包括文章的第一句到整个文本,并且要对其进行端到端的训练以预测参考摘要。由于语言理解是生成流畅摘要的先决条件,因此进行这种端到端的操作需要大量的并行的文章—摘要对。
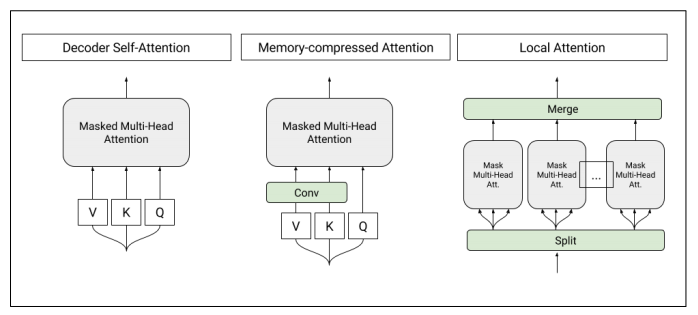
图1:T-DMCA模型中使用的自注意力层(self-attention layers)的架构。每个注意力层都将一个字符序列作为输入,并产生一个相似长度的序列作为输出。左图:转换器解码器中使用的原始自注意。中:内存压缩的注意力(Memory-compressed attentionyers),减少了键/值的数量。右:将序列分割成单个较小的子序列的局部注意力。然后将这些子序列合并在一起以得到最终的输出序列。
相反,我们考虑了多文档摘要的任务,其中,输入是相关文档的集合且其摘要是精炼过的。以往研究工作的着重点在提取式摘要上,从输入中选择句子或短语以形成摘要,而不是生成新的文本。抽象神经方法的应用存在一定的局限性,一个可能的原因是缺少大型的已标记数据集。
在这项研究中,我们将英文维基百科视为一个多文档摘要的监督式机器学习任务,其中,输入由维基百科主题(文章标题)和非维基百科参考文献的集合组成,目标是维基百科的文章文本。我们对第一次试图抽象地生成基于参考文本的维基百科文章的第一部分或引文。除了在任务上运行强大的基线模型之外,我们还将转换器(Transformer)体系结构(Vaswani 等人于2017年提出)修改为只包含一个解码器,在较长的输入序列情况下,与循环神经网络(RNN)以及Transformer编码器—解码器模型相比,它具有更好的表型性能。最后,研究结果表明,我们的建模改进使得我们能够生成完整的维基百科文章。
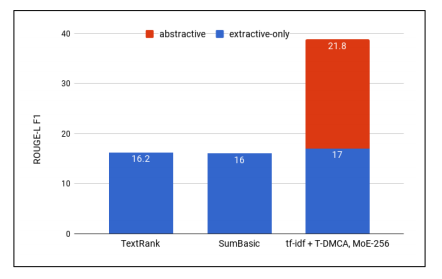
图2:用于各种提取方法的ROUGE-L F1,抽象模型的贡献表现为用于最佳组合的d tf-idf-T-DMCA模型
用于神经抽象摘要的其他数据集
神经抽象摘要(Neural abstractive summarization)是Rush等人(于2015年)提出的,其中,他们使用包括来自多家出版商的新闻报道在内的英文Gigaword语料库(Graff和Cieri于2003年提出)对标题生成模型进行训练。然而,这个任务更像是句子的释义,而不是摘要,因为只有文章的第一句话才被用以预测标题和另一句话。而在ROUGE(一种经常用于摘要的自动度量)和人类评估((Chopra等人于2016年提出))中,基于RNN具有注意力(attention)的编码器—解码器模型(seq2seq),在该任务上具有良好的性能表现。
2016年,Nallapati等人通过修改每日邮报(Daily Mail)和美国有线电视新闻网(CNN)中配有故事亮点的新闻报道的提问数据集,提出了一个抽象的摘要数据集。这个任务比标题生成更为困难,因为亮点中所使用的信息可能来自文章的多个部分,而不仅仅是第一句。数据集的一个缺点是,它有一个较少数量级的并行样本(310k VS 3.8M)以供学习。标准具有注意力的 seq2seq模型性能表现并不太好,并且还使用了大量的技术以提高性能。另一个不利之处是,目前还不清楚制定故事亮点的准则是什么,而且很显然的是,两家新闻出版商在文体上存在者显著的差异。
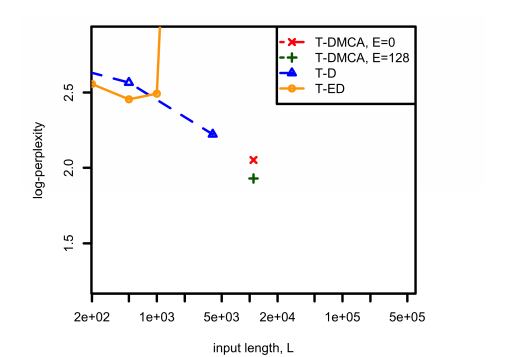
图3:在用于不同模型体系结构的组合语料库上,比较了复杂度和用于tf-idf提取问题中L之间的关系。对于T-DMCA来说,E表示专家级混合层(mixture-of-experts)的大小。
在我们的研究中,我们也对神经抽象模型进行了训练,但是是在维基百科的多文档机制中。从表1可以看出,输入和输出文本通常要大得多,并且根据文章的不同而有着明显的差异。一般来说,摘要(维基百科的主要内容)往往是多个句子,有时是多个段落,且就像维基百科风格手册中所提倡的那样,是以一种相当统一的风格编写的。但是,输入文档可能包含任意来源的任意风格的文档。

表1:摘要数据集的数量级输入/输出大小和一元(unigrams)回调
我们还在表1中给出了ROUGE-1给定输入的输出回调(recall)得分,即同时出现在输入输出中的一元(unigrams)/单词的比例。更高的分数对应于一个更易于进行抽取式摘要处理的数据集。特别是,如果输出完全嵌入到输入的某个地方(例如wiki复制),则得分将为100。相对于对于其他摘要数据集分数为76.1和78.7,而我们的分数为59.2的情况下,表明我们的方法是最不适合进行纯抽取方法的。
涉及维基百科的任务
其实,有许多研究工作都将维基百科用于机器学习任务中,包括问题回答(questionanswering)、信息提取(information extraction)以及结构化数据中的文本生成等。
与我们最为接近的涉及维基百科生成的研究工作是Sauper和Barzilay(于2009年)所进行的,其中文章是使用学习模板从参考文档中抽取式(而不是像我们案例中的抽象式)生成的。维基百科文章限于两类,而我们使用的是所有文章类型。参考文档是从搜索引擎获的,其中,用作查询的维基百科主题与我们的搜索引擎参考颇为相似。不过,我们也会在维基百科文章的“参考文献”部分中显示文档的结果。

图4:同一样本在不同模型中的预测结果显示。
在图4中,我们展示了来自三个不同模型(使用tf-idf提取和组合语料库)的预测结果,以及维基百科的基本事实。随着复杂度的降低,我们看到模型的输出在流畅性、事实准确性和叙述复杂性方面都有所改善。特别是,T-DMCA模型提供了维基百科版本的一个可替代性选择,并且更为简洁,同时提到了关键事实,例如律师事务所所在位置,什么时间、如何形成的,以及该事务所的崛起和衰落。

图5:来自Transformer-ED,L = 500的翻译
在模型输出的手动检查中,我们注意到一个意想不到的副作用:模型试着学习将英文名称翻译成多种语言,例如,将Rohit Viswanath翻译成印地语(见图5)。虽然我们没有对翻译进行系统的评估,但我们发现它们往往是正确的,而且在维基百科文章本身中并没有发现它们。我们还证实,一般情况下,翻译不仅仅是从诸如示例样本这样的源头复制的,其中,目标语言是不正确的(例如名称从英文到乌克兰语的翻译)。
我们已经证明,维基百科的生成可以看作是一个多文档摘要问题,它具有一个大的、并行的数据集,并且演示了一个用以实现它的两阶段的抽取—抽象框架。第一阶段使用的粗提取方法似乎对最终性能有显著的影响,这表明进一步的研究将会取得成果。在抽象阶段,我们引入了一种全新的、仅具有解码器序列的转换模型,能够处理非常长的输入—输出样本。该模型在长序列上的性能表现明显优于传统的编码器—解码器架构,从而使得我们能够在基于许多参考文献的条件下,生成连贯且信息丰富的维基百科文章。
-
解码器
+关注
关注
9文章
1073浏览量
40151 -
编码器
+关注
关注
41文章
3360浏览量
131481 -
自然语言
+关注
关注
1文章
269浏览量
13203 -
rnn
+关注
关注
0文章
67浏览量
6803
原文标题:「谷歌大脑」提出通过对长序列进行摘要提取,AI可自动生成「维基百科」
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论