 从5个方面来解析计算机中的字符编码概念
从5个方面来解析计算机中的字符编码概念
字符编码是计算机编程中不可回避的问题,不管你用 Python2 还是 Python3,亦或是 C++, Java 等,我都觉得非常有必要厘清计算机中的字符编码概念。本文主要分以下几个部分介绍:
基本概念
常见字符编码简介
Python 的默认编码
Python2 中的字符类型
UnicodeEncodeError & UnicodeDecodeError 根源
基本概念
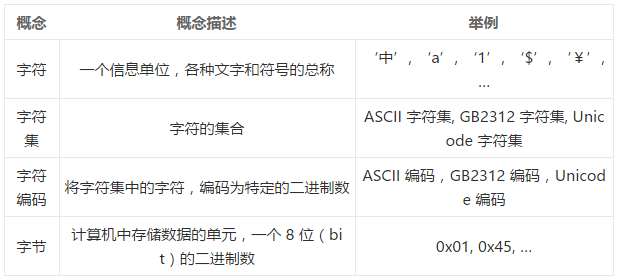
在电脑和电信领域中,字符是一个信息单位,它是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。比如,一个汉字,一个英文字母,一个标点符号等都是一个字符。
字符集(Character set)
字符集是字符的集合。字符集的种类较多,每个字符集包含的字符个数也不同。比如,常见的字符集有 ASCII 字符集、GB2312 字符集、Unicode 字符集等,其中,ASCII 字符集共有 128 个字符,包含可显示字符(比如英文大小写字符、阿拉伯数字)和控制字符(比如空格键、回车键);GB2312 字符集是中国国家标准的简体中文字符集,包含简化汉字、一般符号、数字等;Unicode 字符集则包含了世界各国语言中使用到的所有字符,
字符编码(Character encoding)
字符编码,是指对于字符集中的字符,将其编码为特定的二进制数,以便计算机处理。常见的字符编码有 ASCII 编码,UTF-8 编码,GBK 编码等。一般而言,字符集和字符编码往往被认为是同义的概念,比如,对于字符集 ASCII,它除了有「字符的集合」这层含义外,同时也包含了「编码」的含义,也就是说,ASCII 既表示了字符集也表示了对应的字符编码。
下面我们用一个表格做下总结:
常见字符编码简介
常见的字符编码有 ASCII 编码,GBK 编码,Unicode 编码和 UTF-8 编码等等。这里,我们主要介绍 ASCII、Unicode 和 UTF-8。
ASCII
计算机是在美国诞生的,人家用的是英语,而在英语的世界里,不过就是英文字母,数字和一些普通符号的组合而已。
在 20 世纪 60 年代,美国制定了一套字符编码方案,规定了英文字母,数字和一些普通符号跟二进制的转换关系,被称为 ASCII (American Standard Code for Information Interchange,美国信息互换标准编码) 码。
比如,大写英文字母 A 的二进制表示是 01000001(十进制 65),小写英文字母 a 的二进制表示是 01100001 (十进制 97),空格 SPACE 的二进制表示是 00100000(十进制 32)。
Unicode
ASCII 码只规定了 128 个字符的编码,这在美国是够用的。可是,计算机后来传到了欧洲,亚洲,乃至世界各地,而世界各国的语言几乎是完全不一样的,用 ASCII 码来表示其他语言是远远不够的,所以,不同的国家和地区又制定了自己的编码方案,比如中国大陆的 GB2312 编码 和 GBK 编码等,日本的 Shift_JIS 编码等等。
虽然各个国家和地区可以制定自己的编码方案,但不同国家和地区的计算机在数据传输的过程中就会出现各种各样的乱码(mojibake),这无疑是个灾难。
怎么办?想法也很简单,就是将全世界所有的语言统一成一套编码方案,这套编码方案就叫 Unicode,它为每种语言的每个字符设定了独一无二的二进制编码,这样就可以跨语言,跨平台进行文本处理了,是不是很棒!
Unicode 1.0 版诞生于 1991 年 10 月,至今它仍在不断增修,每个新版本都会加入更多新的字符,目前最新的版本为 2016 年 6 月 21 日公布的 9.0.0。
Unicode 标准使用十六进制数字,而且在数字前面加上前缀 U+,比如,大写字母「A」的 unicode 编码为 U+0041,汉字「严」的 unicode 编码为 U+4E25。更多的符号对应表,可以查询 unicode.org,或者专门的汉字对应表。
UTF-8
Unicode 看起来已经很完美了,实现了大一统。但是,Unicode 却存在一个很大的问题:资源浪费。
为什么这么说呢?原来,Unicode 为了能表示世界各国所有文字,一开始用两个字节,后来发现两个字节不够用,又用了四个字节。比如,汉字「严」的 unicode 编码是十六进制数 4E25,转换成二进制有十五位,即 100111000100101,因此至少需要两个字节才能表示这个汉字,但是对于其他的字符,就可能需要三个或四个字节,甚至更多。
这时,问题就来了,如果以前的 ASCII 字符集也用这种方式来表示,那岂不是很浪费存储空间。比如,大写字母「A」的二进制编码为 01000001,它只需要一个字节就够了,如果 unicode 统一使用三个字节或四个字节来表示字符,那「A」的二进制编码的前面几个字节就都是 0,这是很浪费存储空间的。
为了解决这个问题,在 Unicode 的基础上,人们实现了 UTF-16, UTF-32 和 UTF-8。下面只说一下 UTF-8。
UTF-8 (8-bit Unicode Transformation Format) 是一种针对 Unicode 的可变长度字符编码,它使用一到四个字节来表示字符,例如,ASCII 字符继续使用一个字节编码,阿拉伯文、希腊文等使用两个字节编码,常用汉字使用三个字节编码,等等。
因此,我们说,UTF-8 是 Unicode 的实现方式之一,其他实现方式还包括 UTF-16(字符用两个或四个字节表示)和 UTF-32(字符用四个字节表示)。
Python 的默认编码
Python2 的默认编码是 ascii,Python3 的默认编码是 utf-8,可以通过下面的方式获取:
Python2
Python2.7.11(default,Feb242016,10:48:05)
[GCC4.2.1Compatible AppleLLVM7.0.2(clang-700.1.81)]on darwin
Type"help","copyright","credits"or"license"formoreinformation.
>>>importsys
>>>sys.getdefaultencoding()
'ascii'
Python3
Python3.5.2(default,Jun292016,13:43:58)
[GCC4.2.1Compatible AppleLLVM7.3.0(clang-703.0.31)]on darwin
Type"help","copyright","credits"or"license"formoreinformation.
>>>importsys
>>>sys.getdefaultencoding()
'utf-8'
Python2 中的字符类型
Python2 中有两种和字符串相关的类型:str 和 unicode,它们的父类是 basestring。其中,str 类型的字符串有多种编码方式,默认是 ascii,还有 gbk,utf-8 等,unicode 类型的字符串使用 u'...' 的形式来表示,下面的图展示了 str 和 unicode 之间的关系:
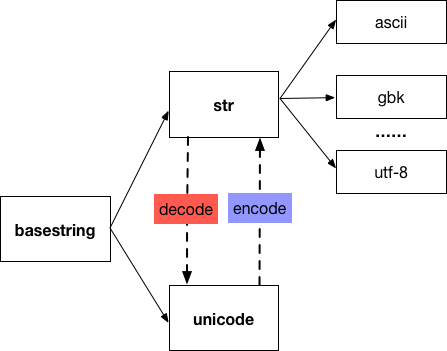
两种字符串的相互转换概括如下:
把 UTF-8 编码表示的字符串 ‘xxx’ 转换为 Unicode 字符串 u’xxx’ 用 decode('utf-8') 方法:
>>>'中文'.decode('utf-8')
u'中文'
把 u’xxx’ 转换为 UTF-8 编码的 ‘xxx’ 用 encode('utf-8') 方法:
>>>u'中文'.encode('utf-8')
'ä¸æ'
UnicodeEncodeError & UnicodeDecodeError 根源
用 Python2 编写程序的时候经常会遇到 UnicodeEncodeError 和 UnicodeDecodeError,它们出现的根源就是如果代码里面混合使用了 str 类型和 unicode 类型的字符串,Python 会默认使用 ascii 编码尝试对 unicode 类型的字符串编码 (encode),或对 str 类型的字符串解码 (decode),这时就很可能出现上述错误。
下面有两个常见的场景,我们最好牢牢记住:
在进行同时包含 str 类型和 unicode 类型的字符串操作时,Python2 一律都把 str 解码(decode)成 unicode 再运算,这时就很容易出现 UnicodeDecodeError。
让我们看看例子:
>>>s='你好'# str 类型, utf-8 编码
>>>u=u'世界'# unicode 类型
>>>s+u# 会进行隐式转换,即 s.decode('ascii') + u
Traceback(most recent calllast):
File"
UnicodeDecodeError:'ascii'codeccan'tdecodebyte0xe4inposition0:ordinalnotinrange(128)
为了避免出错,我们就需要显示指定使用 ‘utf-8’ 进行解码,如下:
>>>s='你好'# str 类型,utf-8 编码
>>>u=u'世界'
>>>
>>>s.decode('utf-8')+u# 显示指定 'utf-8' 进行转换
u'你好世界'# 注意这不是错误,这是 unicode 字符串
如果函数或类等对象接收的是 str 类型的字符串,但你传的是 unicode,Python2 会默认使用 ascii 将其编码成 str 类型再运算,这时就很容易出现 UnicodeEncodeError。
让我们看看例子:
>>>u_str=u'你好'
>>>str(u_str)
Traceback(most recent calllast):
File"
UnicodeEncodeError:'ascii'codeccan'tencode charactersinposition0-1:ordinalnotinrange(128)
在上面的代码中,u_str 是一个 unicode 类型的字符串,由于 str() 的参数只能是 str 类型,此时 Python 会试图使用 ascii 将其编码成 ascii,也就是:
u_str.encode('ascii') // u_str 是 unicode 字符串
上面将 unicode 类型的中文使用 ascii 编码转,肯定会出错。
再看一个使用 raw_input 的例子,注意 raw_input 只接收 str 类型的字符串:
>>>name=raw_input('input your name: ')
inputyourname:ethan
>>>name
'ethan'
>>>name=raw_input('输入你的姓名:')
输入你的姓名:小明
>>>name
'å°æ'
>>>type(name)
>>>name=raw_input(u'输入你的姓名: ')# 会试图使用 u'输入你的姓名'.encode('ascii')
Traceback(most recent calllast):
File"
UnicodeEncodeError:'ascii'codeccan't encode characters in position 0-5: ordinal not in range(128)
>>> name = raw_input(u'输入你的姓名:'.encode('utf-8')) #可以,但此时 name 不是 unicode 类型
输入你的姓名: 小明
>>> name
'xe5xb0x8fxe6x98x8e'
>>> type(name)
>>> name = raw_input(u'输入你的姓名:'.encode('utf-8')).decode('utf-8') # 推荐
输入你的姓名:小明
>>> name
u'u5c0fu660e'
>>> type(name)
再看一个重定向的例子:
hello=u'你好'
printhello
将上面的代码保存到文件 hello.py,在终端执行 python hello.py 可以正常打印,但是如果将其重定向到文件 python hello.py > result 会发现 UnicodeEncodeError。
这是因为:输出到控制台时,print 使用的是控制台的默认编码,而重定向到文件时,print 就不知道使用什么编码了,于是就使用了默认编码 ascii 导致出现编码错误。
应该改成如下:
hello=u'你好'
printhello.encode('utf-8')
这样执行 python hello.py > result 就没有问题。
小结
UTF-8 是一种针对 Unicode 的可变长度字符编码,它是 Unicode 的实现方式之一。
Unicode 字符集有多种编码标准,比如 UTF-8, UTF-7, UTF-16。
在进行同时包含 str 类型和 unicode 类型的字符串操作时,Python2 一律都把 str 解码(decode)成 unicode 再运算。
如果函数或类等对象接收的是 str 类型的字符串,但你传的是 unicode,Python2 会默认使用 ascii 将其编码成 str 类型再运算。
-
计算机
+关注
关注
19文章
6631浏览量
84370 -
编码
+关注
关注
6文章
835浏览量
54452 -
字符
+关注
关注
0文章
229浏览量
24883 -
python
+关注
关注
51文章
4667浏览量
83443
原文标题:Python字符编码全解析
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【量子计算机重构未来 | 阅读体验】+ 了解量子叠加原理
计算机文化基础课程教学大纲
计算机中的电磁兼容情况
计算机中丢失OpenNI2.dll相关资料下载
8086微型计算机常用字符编码
在计算机中不同硬件对Hz的定义相同吗
微型计算机中采用的逻辑元件是什么
基于嵌入式实时软件在计算机中的应用研究
计算机编码全解析(中)
计算机编码全解析(下)






 工商网监
工商网监
评论