 使用Xilinx 20nm工艺的UltraScale FPGA来降低功耗的19种途径
使用Xilinx 20nm工艺的UltraScale FPGA来降低功耗的19种途径
在绝大部分使用电池供电和插座供电的系统中,功耗成为需要考虑的第一设计要素。Xilinx决定使用20nm工艺的UltraScale器件来直面功耗设计的挑战,本文描述了在未来的系统设计中,使用Xilinx 20nm工艺的UltraScale FPGA来降低功耗的19种途径。
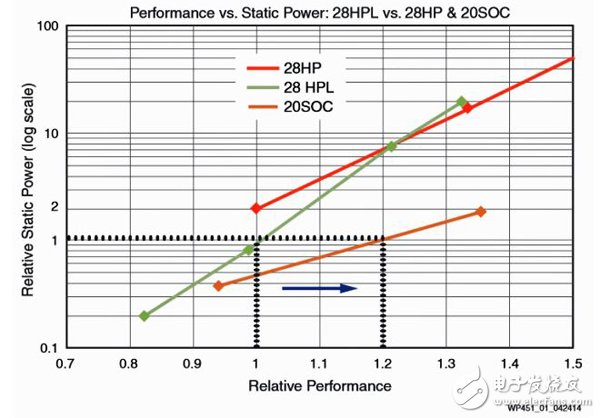
1、制造工艺:TSMC使用20SoC工艺来生产Xilinx 20nm的UltraScale器件,该工艺采用TSMC第二代gate-last HKMG(high-K绝缘层+金属栅极)技术和第三代SiGe (silicon-germanium)应变技术来实现在低功耗时提高性能。跟TSMC 28nm工艺相比,20SoC工艺技术能做到器件密度增加1.9倍,同时速度提升30%。
2、电压调整:TSMC 20SoC工艺有两种模式,一种是高性能模式(Vcc = 0.95V),还有一种是低功耗模式(Vcc = 0.9V)。20SoC高性能模式与TSMC 28HP和28HPL工艺相比,能提供更高的性能以及更低的静态功耗。低功耗模式跟TSMC 28HP工艺相比,静态功耗要低65%,使用TSMC 20SoC工艺制造的器件的Vcc空间使得Xilinx能选择功耗分布曲线上的合适的部分,即在Vcc降低到0.9V时,在性能上仍然有不错的表现,但此时的动态功耗却可以下降大约10%。
20nm工艺UltraScale器件,性能和功耗对比:非常显著的优势
3、选择功耗最低的器件:Xilinx 20nm UltraScale FPGA中,在0.95V或者0.9V下都可以工作的器件被定义为-1L,这是基于它们在0.95V下的速度等级来定义的。-1L UltraScale器件的性能和0.95V,速度等级为-1的器件性能相同,和工作在0.9V,速度等级为-1的器件性能也一致,但是-1L的定义表示,这类器件的静态功耗是特别低。在0.9V时,光是Vcc的下降就可以使得静态功耗下降大约30%。相比其他UltraScale FPGA器件,Xilinx对-1L器件的速度和漏电有着更加严格的定义标准,换句话说,只有那些漏电最低、性能最高的UltraScale器件才能称为-1L器件。
4、管理3D IC的工艺变动:20nm UltraScale FPGA规模较大,实际上是3D IC,采用了Xilinx第二代堆叠硅片互联(SSI)技术,它可以把一个封装里的多个FPGA die连接起来。Xilinx通过在一个封装中组合较高和较低漏电的die(都在说明书中)来控制整个3D IC的静态漏电功耗,结果是整个封装器件的漏电功耗要远远低于只使用一个die(具备相同可编程逻辑容量)的封装。
5、通过3D IC集成来缩减I/O功耗:和传统的多芯片设计相比,在具备相同的I/O带宽的情况下,基于SSI的3D IC技术可以使I/O互连功耗减小100倍。这个激动人心的结果就是通过把所有的连接都保留在芯片内部来实现的,与把信号驱动到芯片外部相比,这种做法的功耗显著降低,这种设计理念可以在低功耗的情况下获得令人难以置信的高速度。
6、低功耗设计不仅仅停留在工艺级别:在20nm工艺节点上,Xilinx从每一个角度去聚焦功耗效率。基于动态功耗能减少的百分比,Xilinx对很多选项都进行了评估,每一项都会产生相应的风险以及实现的时间。每一个降低功耗的技术,它在性能、成本、设计流程方法以及总体进度方面的影响也会被评估,被挑选出来的选项最终实现在所有Xilinx 20nm UltraScale器件中。
7、类似ASIC的时钟设计使得功耗降低:跟所有以往的FPGA架构相比,UltraScale架构中的时钟布线和时钟buffer进行了彻底地重新设计,可以提供更大程度的灵活性。在纵横两个方向上,大量的时钟布线和时钟分布路径产生了许许多多的全局时钟buffer,数量是以往架构中的20倍以上,那个架构有着无数个布局的选项。实际上,在一个UltraScale FPGA中,时钟网络的“中心点”(时钟偏移开始累积的起始点)可以被放在任何一个时钟域。和ASIC相同的是,哪里需要时钟,哪里的时钟网络才开始工作。UltraScale架构可以向可编程逻辑设备提供偏移最小、性能最快的时钟网络,这些时钟网络只有在源需要向目的发送时钟信号时才产生功耗。

UltraScale 类ASIC时钟设计
8、精细化的时钟门控:可以通过精细化的时钟门控技术来进一步降低动态时钟功耗。在一个设计中,当相关逻辑不需要工作的时候,可以动态门控关闭时钟驱动。这个特性可以静态或者以一个时钟周期的粒度来动态执行。最大的20nm UltraScale器件中,除了常见的全局门控时钟之外,还有数以千计的末梢门控时钟。时钟树功耗(CV2f)实际上大部分是发生在横向buffer和时钟树末梢时钟这一级,因为在这一级上,驱动了数以千计的负载,这一级上的时钟门控可以使得动态功耗消减非常明显。另外,降低扇出可以减小时钟buffer功耗,因为这个时候,时钟buffer仅仅驱动几个负载,这也能降低时钟树的功耗。因为有着大量的可门控的时钟,一些基于20nm UltraScale器件的设计可以节省10-15%的时钟树功耗,当然,这还要取决于时钟的使能率。
9、充分使用每一个CLB来减少CLB的使用数量:UltraScale架构采用了加强的可配置逻辑单元(CLB),可以效率更高地使用这些可用的CLB资源。对于可能的封装选项而言,CLB结构上的许多改变提供了更多的灵活性。每一个6-输入LUT都是由两个触发器组成,每个触发器都有专用的输入和输出信号,使得一个CLB中的所有部件既可以一起使用,也可以完全独立。控制信号在数量和灵活性上的提高使得触发器更加易用,包括:可用的时钟使能信号数量翻倍;可选择“忽略”时钟使能和复位端口的输入;可选择复位信号反向,使得同一个CLB中的触发器的复位信号电平既可以是高有效,也可以是低有效;一个额外的时钟信号用于移位寄存器和分布式RAM。总而言之,这些加强特性可以让Vivado设计套件把更多的设计部件(经常是在功能上相互没有关系)封装在一个CLB中。通过对器件总体利用上的最大化来消耗尽可能最低的功耗。
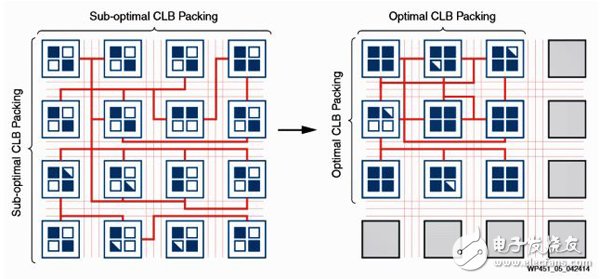
充分使用每一个UltraScale CLB来减少CLB的使用数量
10、更少的CLB意味着CLB之间的布线更少:CLB利用率的显著提高使得设计的封装更紧密,性能更高。紧密的封装最终体现为更短的连线长度,因此连线电容更小,这有助于一个设计的总体功耗的降低。
11、关掉不用的Block RAM:UltraScale架构支持电源门控,可以关掉不用的Block RAM。降低Block RAM的静态漏电功耗对降低整个器件的漏电功耗非常有帮助。
12、Block RAM级联降低动态功耗:UltraScale 的Block RAM支持高速存储器级联(用于数据级联布线)以及输出复用,这样可以实现速度更快、动态功耗更低的大容量Block RAM阵列。多个Block RAM可以级联到一起而不影响Block RAM的时序,这个特性可以在任何特定时刻使工作的Block RAM数量最小化,这样可以进一步降低动态功耗。
13、使用更少的DSP Slice:尽管Virtex-7 FPGA的DSP Slice性能已经是业界的领导者,Xilinx还是在UltraScale架构中,对DSP Slice性能进行了较大的提升。这样,在布线更少、DSP外部逻辑资源使用更少的同时,实现更快的数字信号处理。举例来说,用UltraScale架构中DSP模块的27x18位宽的乘法器来实现IEEE Std 754双精度算法,所用的DSP模块资源比用Xilinx 7系列器件来实现相同功能要减少三分之二。
14、降低I/O功耗:对于总体功耗而言,I/O功耗已经成为一个重要的组成部分。随着可编程器件的技术改进,内核功耗已经有了很大的减少,但是直到最近(随着Xilinx 7系列可编程器件的出现),I/O功耗的降低却并不明显,特别是对于一些存储器密集型的应用来说,大量的I/O带来的功耗会占到一个设计的总体功耗的50%。Xilinx在7系列FPGA中,通过可编程的电压转换速率和驱动强度来降低I/O功耗,UltraScale器件采用了相同的节省功耗的方法。
15、使用DDR4存储器:UltraScale架构升级了存储器接口,支持多个DDR3/4兼容的SDRAM存储器控制器,并且把DDR物理层接口(PHY)模块集成到片内。当从DDR3到DDR4转变时,你可以看到功耗上有20%的下降,原因是DDR4工作在一个更低的1.2V的电压下。
16、降低高速串行收发器功耗:Xilinx 20nm UltraScale器件的SerDes都为了高性能和低抖动而进行了优化设计,能提供一些低功耗操作的特性。UltraScale架构中,对GTH收发器进行了重新设计,跟7系列FPGA中的GTX和GTH收发器相比,可以削减50%的总体的功耗。
17、在不需要DFE的时候关闭它:许多无背板的应用场合不需要在SerDes收发器中使用判决反馈均衡器(DFE)电路。因为DFE需要消耗额外的功耗,因此,当SerDes端口用作其它用途时,Xilinx UltraScale器件允许设计人员关闭DFE。为了节省功耗,你可以关掉DFE电路,而使用线性均衡器(LE),跟DFE相比,因为LE自身更低的Rx增益和最小化的电路,所以功耗要小很多。
18、增加硬IP模块:用集成的硬核模块来代替软IP,可以降低10倍的功耗。Xilinx实现了一个集成的Interlaken IP核用于片间的连接,可以达到150Gbps。Xilinx的IP核是基于业界领导和最广泛的部署来实现的,对Interlaken接口协议规范rev1.2的实现具有灵活性、高性能和低功耗的特点,可以支持12.5Gbps和25Gbps的收发器。结合了UltraScale架构的收发器技术以及灵活的协议层,集成IP核可以实现片间互连的管脚个数和功耗的最小化。同相同的软IP解决方案相比,集成IP核的延迟更小,这样可以预先知道IP的性能。
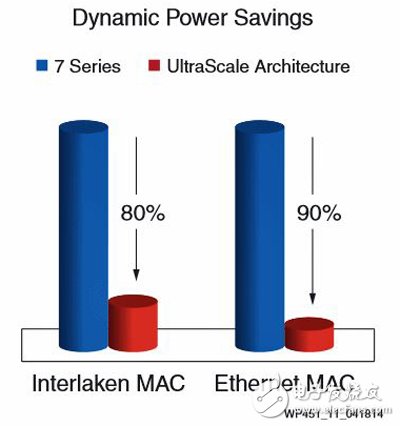
使用硬IP核节省功耗
19、把降低功耗的思想深入到设计工具中:Vivado设计套件直接可以支持UltraScale架构的许多降功耗的特性,比如说,Vivado设计套件为了能够把设计的一部分进行电源门控,会产生一些逻辑来驱动时钟末梢buffer的开关。这个工具还会自动产生逻辑来支持对Block RAM的静态和动态功耗的门控,能推断出是否要把Block RAM进行级联。
-
Xilinx
+关注
关注
70文章
2119浏览量
119363 -
UltraScale
+关注
关注
0文章
113浏览量
31326
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论