 绕开CPU和内存,你浏览的内容或来自SSD的推荐
绕开CPU和内存,你浏览的内容或来自SSD的推荐
绕开CPU和内存,你浏览的内容或来自SSD的推荐
相信不少人都还记得今年AI芯片公司Esperanto发布的千核RISC-V处理器ET-SoC-1,随着这款7nm的芯片于第二季度成功流片返回后,Esperanto得以在芯片上运行代码,以及尝试新的应用方向,其中之一就是AI-SSD。在近期举办的三星Foundry活动上,Esperanto公开了自己AI-SSD的概念模型。
个性化推荐系统的挑战
在我们刷短视频、听歌和浏览社交网络时,一部分内容来自于我们已经关注的用户,但绝大多数来自于推荐系统的推送。推荐系统的准确程度很大程度决定了软件的用户体验,也是如今互联网经济系统的命脉。但这类推荐也往往是服务器上消耗最大的AI处理负载,优化推荐系统可以提高推荐系统的速度,减少在服务器上的成本。

DLRM深度学习推荐模型 / Meta
谈到推荐系统就不得不谈到嵌入,嵌入是当下推荐系统中关键的组成部分。尽管每家都有着不同的推荐模型,但或多或少都是采用查找嵌入表的方法来实现分类特征的处理。在这个过程中,嵌入表存储在DRAM中,而CPU对嵌入表进行操作,这就对内存带宽和内存容量提出了双重挑战。
在内存带宽上,像美团和腾讯等厂商纷纷采用多GPU加速的方式,充分利用GPU的带宽,但这种方式依然需要多个GPU或多个服务器的支持才能解决容量问题。固然厂商也可以选择像HBM这种大带宽的内存方案,但带来的成本提升也是巨大的。
根据Meta给出的说法,在Facebook社交网站的个性化推荐系统中,大规模的嵌入表可达到百万行以上,导致推荐模型的大小达到10GB左右,一个神经推荐模型中所有嵌入表甚至需要TB级别以上的空间。比如Meta旗下的Instagram已经在开发10TB的推荐模型,而百度的广告排名模型也达到了10TB。这种级别的容量需求对硬盘来说或许足够,但对于内存来说过于奢侈了。
因此为了解决容量问题,不少人也提出了SSD的存储解决方案,目前传统的SSD虽然可以毫不费力地存储下大规模推荐系统,但读取延迟和带宽都要更差一筹,从而显著降低推理的性能。
专为推荐而生的SSD
Esperanto与三星合作开发出了一种AI-SSD的概念模型,来研究将所有嵌入表处理全部移到SSD内部会有怎么样的影响,从而省去推荐系统中经过CPU和DRAM的环节。三星展示了使用Esperanto的ET-SoC-1芯片与其PM9A3 SSD结合的成果。
在AI-SSD中,所有嵌入表都被存储在SSD里,CPU负责所有的用户数据输入和深度神经网络,而SSD内部的ET-SoC-1负责嵌入表的查询和交互运算。此外由于选择了这种存内计算的方式,最小化了PCIe链路上的数据传输,降低了读写的高延迟,最终的分类数据直接交给CPU生成推荐结果。
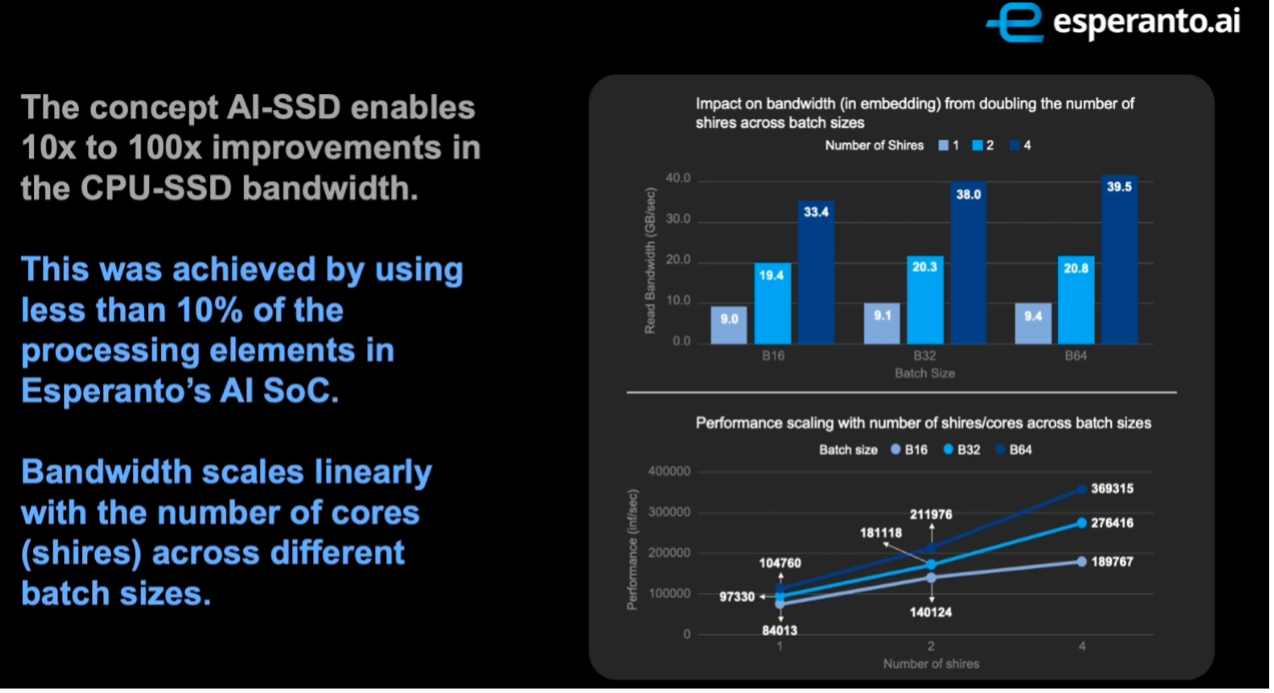
AI-SSD带宽性能测试结果 / Esperanto
测试环节中,Esperanto选用了Meta的开源推荐模型DLRM,将AI-SSD与传统的CPU-SSD方式进行对比。在不同的模型配置下,AI-SSD实现了10到100倍的读取带宽提升,而且带宽随着使用核心数的上升还能继续线性提升。
要知道在这次测试中,Esperanto最多只用到了四个子节点(Minion Shire),每个节点只有32个核心。而一整个ET-SoC-1有34个子节点1088颗核心,如果所有计算单元全部用于SSD的话,提升幅度将达到数百倍以上,十分适合数据中心级别的SSD产品。而ET-SoC-1的扩展性也可以让它缩减核心数,用于一些边缘端的推荐系统。
拿计算换空间
不过即便用上了AI-SSD,这也是一种增加硬件成本的路线,除了不差钱的大公司会利用这种产品外,一些小的互联网应用可能并不会直接选择更换SSD的方式,如此一来,也就只有继续优化推荐模型一途。
佐治亚理工学院和Meta的研究院为DLRM提出了一种张量训练压缩的方式,名为TT-Rec。该方法通过将嵌入表分为多个小矩阵相乘的方式进行压缩,进一步降低嵌入表的大小,不过这多出来的计算是肯定躲不掉的额外消耗,好在其评估结果足够优秀。
在Kaggle和Terabyte数据集的测试训练下,TT-Rec分别将数据从2.16GB和12.57GB压缩至18.36MB和0.11GB,整体的大小压缩均在百倍以上,甚至可以做到几乎没有精度损失。而多出来的运算则反映到了训练时间上,分别增加了14.3%和13.9%。因此在实际使用中,必须对内存容量、模型精度和训练时间做出一定的取舍。
小结
尽管从推荐系统配置的角度来说,仍有不少可选的解决方案,但存算一体方面的研究已经全面铺开了。存储市场正在迅速与计算市场发生重叠,像三星、西数和希捷等存储厂商纷纷开始了这块的布局,传统的冯诺依曼架构也将被近数据处理替代。
相信不少人都还记得今年AI芯片公司Esperanto发布的千核RISC-V处理器ET-SoC-1,随着这款7nm的芯片于第二季度成功流片返回后,Esperanto得以在芯片上运行代码,以及尝试新的应用方向,其中之一就是AI-SSD。在近期举办的三星Foundry活动上,Esperanto公开了自己AI-SSD的概念模型。
个性化推荐系统的挑战
在我们刷短视频、听歌和浏览社交网络时,一部分内容来自于我们已经关注的用户,但绝大多数来自于推荐系统的推送。推荐系统的准确程度很大程度决定了软件的用户体验,也是如今互联网经济系统的命脉。但这类推荐也往往是服务器上消耗最大的AI处理负载,优化推荐系统可以提高推荐系统的速度,减少在服务器上的成本。
DLRM深度学习推荐模型 / Meta
谈到推荐系统就不得不谈到嵌入,嵌入是当下推荐系统中关键的组成部分。尽管每家都有着不同的推荐模型,但或多或少都是采用查找嵌入表的方法来实现分类特征的处理。在这个过程中,嵌入表存储在DRAM中,而CPU对嵌入表进行操作,这就对内存带宽和内存容量提出了双重挑战。
在内存带宽上,像美团和腾讯等厂商纷纷采用多GPU加速的方式,充分利用GPU的带宽,但这种方式依然需要多个GPU或多个服务器的支持才能解决容量问题。固然厂商也可以选择像HBM这种大带宽的内存方案,但带来的成本提升也是巨大的。
根据Meta给出的说法,在Facebook社交网站的个性化推荐系统中,大规模的嵌入表可达到百万行以上,导致推荐模型的大小达到10GB左右,一个神经推荐模型中所有嵌入表甚至需要TB级别以上的空间。比如Meta旗下的Instagram已经在开发10TB的推荐模型,而百度的广告排名模型也达到了10TB。这种级别的容量需求对硬盘来说或许足够,但对于内存来说过于奢侈了。
因此为了解决容量问题,不少人也提出了SSD的存储解决方案,目前传统的SSD虽然可以毫不费力地存储下大规模推荐系统,但读取延迟和带宽都要更差一筹,从而显著降低推理的性能。
专为推荐而生的SSD
Esperanto与三星合作开发出了一种AI-SSD的概念模型,来研究将所有嵌入表处理全部移到SSD内部会有怎么样的影响,从而省去推荐系统中经过CPU和DRAM的环节。三星展示了使用Esperanto的ET-SoC-1芯片与其PM9A3 SSD结合的成果。
在AI-SSD中,所有嵌入表都被存储在SSD里,CPU负责所有的用户数据输入和深度神经网络,而SSD内部的ET-SoC-1负责嵌入表的查询和交互运算。此外由于选择了这种存内计算的方式,最小化了PCIe链路上的数据传输,降低了读写的高延迟,最终的分类数据直接交给CPU生成推荐结果。
AI-SSD带宽性能测试结果 / Esperanto
测试环节中,Esperanto选用了Meta的开源推荐模型DLRM,将AI-SSD与传统的CPU-SSD方式进行对比。在不同的模型配置下,AI-SSD实现了10到100倍的读取带宽提升,而且带宽随着使用核心数的上升还能继续线性提升。
要知道在这次测试中,Esperanto最多只用到了四个子节点(Minion Shire),每个节点只有32个核心。而一整个ET-SoC-1有34个子节点1088颗核心,如果所有计算单元全部用于SSD的话,提升幅度将达到数百倍以上,十分适合数据中心级别的SSD产品。而ET-SoC-1的扩展性也可以让它缩减核心数,用于一些边缘端的推荐系统。
拿计算换空间
不过即便用上了AI-SSD,这也是一种增加硬件成本的路线,除了不差钱的大公司会利用这种产品外,一些小的互联网应用可能并不会直接选择更换SSD的方式,如此一来,也就只有继续优化推荐模型一途。
佐治亚理工学院和Meta的研究院为DLRM提出了一种张量训练压缩的方式,名为TT-Rec。该方法通过将嵌入表分为多个小矩阵相乘的方式进行压缩,进一步降低嵌入表的大小,不过这多出来的计算是肯定躲不掉的额外消耗,好在其评估结果足够优秀。
在Kaggle和Terabyte数据集的测试训练下,TT-Rec分别将数据从2.16GB和12.57GB压缩至18.36MB和0.11GB,整体的大小压缩均在百倍以上,甚至可以做到几乎没有精度损失。而多出来的运算则反映到了训练时间上,分别增加了14.3%和13.9%。因此在实际使用中,必须对内存容量、模型精度和训练时间做出一定的取舍。
小结
尽管从推荐系统配置的角度来说,仍有不少可选的解决方案,但存算一体方面的研究已经全面铺开了。存储市场正在迅速与计算市场发生重叠,像三星、西数和希捷等存储厂商纷纷开始了这块的布局,传统的冯诺依曼架构也将被近数据处理替代。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
SSD
+关注
关注
20文章
2688浏览量
115475 -
AI
+关注
关注
87文章
26424浏览量
264030
发布评论请先 登录
相关推荐
引领PCIe Gen5 SSD部署,铠侠在CFMS展出哪些旗舰产品?
电子发烧友原创 章鹰 3月20日,在深圳前海举办的2024CFMS峰会上,来自日本存储大厂铠侠CTO柳茂知表示,闪存价格出现上涨,今年存储市场的发展会有一些机遇和挑战,他非常期待市场的恢复和增长

【鸿蒙】webview内存泄漏问题的分析报告
1 关键字 webview;内存泄漏 2 问题描述 问题现象:在 3.1release 版本和 3.2bete1 版本中,在 RK3568 上使用 etsWeb 和其他浏览器时,webview 所占
如何通过浏览器访问Web页面进行固件更新的方法?
如果电脑没有安装 TIA PORTAL 软件,但是 CPU 之前激活了 Web 服务器功能,可以通过电脑联网 CPU,然后打开浏览器浏览到 CPU

求助,为什么 \" ld.w \" 导致某些内存内容被修改?
; 指令执行后,一些内存内容被更改。 这很难理解。 有人遇到过类似的问题吗。 以下是我的情况,
1) 在执行 " ld.w 之前 " 指令,来自
发表于 01-26 07:35
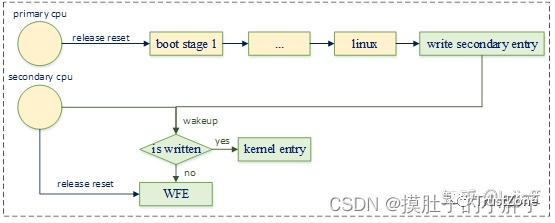
secondary cpu初始化状态设置
中,然后唤醒cpu。 secondary cpu被唤醒后,检查该内存的内容,确认内核已经向其写入了启动地址,就跳转到该地址执行启动流程。 secondary
EC SRAM映射到CPU Memory空间的共享内存设计
ShareMemory,顾名思义就是共享内存。这个概念在很多计算机系统中都存在,本文特指 EC SRAM 映射到 CPU Memory 空间的共享内存设计。
CPU、GPU和内存知识科普
本文内容包括CPU、内存和GPU知识,本期重点更新GPU和CPU部分知识。比如:GPU更新包括架构演进,最新产品A100、选型策略、架构分析、散热和规格分类等。

MMU原理:CPU是如何访问到内存的?
当CPU访问虚拟地址0的时候,MMU会去查上面页表的第0行,发现第0行没有命中,于是无论以何种形式(R读,W写,X执行)访问,MMU都会给CPU发出page fault,CPU自动跳到fault的代码去处理fault。
发表于 11-09 12:30
•342次阅读
路由器内存和cpu哪个重要
路由器内存和cpu哪个重要 在现代家庭网络中,路由器扮演着非常重要的角色。它是网络连接的枢纽,负责将互联网连接分发到家庭中的设备。作为家庭网络的中心,路由器的两个最重要的组件分别是CPU和内存
探索内存交换的新出路
内存交换技术是当内存紧缺的时候,将内存中的页面交换到交换设备中(如zRAM,SSD等)。随着SSD的性能越来越好,越来越多的交换设备采用





 工商网监
工商网监
评论