 AMD祭出杀手锏,首个百亿亿级GPU
AMD祭出杀手锏,首个百亿亿级GPU
AMD祭出杀手锏,首个百亿亿级GPU
在不久前结束的 “加速数据中心”发布会上,AMD正式公开了下一代服务器CPU Milan-X和GPU加速卡Instinct MI200。这两大产品系列不仅面向数据中心,也将面向一系列HPC和超算应用,把通用计算和AI性能推向极致。Instinct MI200作为GPU加速卡,更是成为超级计算机百亿亿级(Exascale)的算力的基本构成单元。
在市场合作上,AMD更是开始了新一轮的攻城略地,前不久刚和腾讯联合发布了星星海服务器产品后,如今Azure等一众公有云厂商也开始部署基于Milan-X的服务器,甚至将刚改名为Meta的Facebook也被拉拢至AMD阵营,宣布将在其数据中心部署AMD的服务器产品。
Milan-X:6nm的大缓存怪兽
继上一代Milan处理器推出后不到一年,AMD就发布了该芯片的6nm改进版Milan-X。今年上半年通过融合Chiplet和Die堆叠两大技术,在Ryzen桌面处理器上做了3D Chiplet架构的演示。如今第三代Epyc处理器Milan-X,将成为首个使用该技术的服务器产品。通过在Chiplet上堆叠缓存,Milan-X的L3缓存是Milan的三倍,达到了可怕的768MB。

MilanX / AMD
与英特尔一样,AMD在正式发售前并没有公布Milan-X的具体性能细节,而是通过合作伙伴的测试来展示了Milan-X在EDA和公有云应用中表现。在新思的VCS功能验证中,Milan-X在1小时内完成了40.6项任务,而同样核心数的Milan仅完成了24.4项。微软在基于Milan-X的Azure服务器中进行了早期测试,无论是在航天模拟,还是在汽车碰撞测试建模中,Milan-X都做到了50%以上的性能提升。
除此之外,AMD CEO苏资丰博士还透露了下一代5nm Epyc处理器Genoa的情报。基于Zen 4架构的Genoa将具备2倍的晶体管密度和2倍的能效,性能可以达到上一代的1.25倍以上。Genoa最高支持96个Zen 4核心,同时也将加入一系列新标准的支持,比如DDR5、PCIe 5.0和CXL。AMD还将推出基于5nm的Zen 4C核心的处理器Bergamo,专门针对要求多核多线程的云原生计算,最高核心数将达到128核,晚于Genoa发布。
Genoa计划在2022年量产和发布,届时很可能就是英特尔的Sapphire Rapids和AMD的Genoa在通用计算领域争雄了。
Instinct MI200:GPU终于迎来MCM时代了?
除了Milan-X之外,发布会的最大亮点其实是全球首个MCM GPU,Instinct MI200。同样基于台积电的6nm工艺,Instinct MI200系列单芯片的晶体管数目达到580亿,最高集成了220个计算单元。作为首个采用AMD CDNA2架构的服务器GPU,Instinct MI200的目标很明确,那就是将计算能力推向ExaScale级。
在CDN2架构和第二代HPC&AI专用矩阵核心的支持下,Instinct MI200实现了远超竞品的性能表现。数据对比环节,AMD选择拿Nvidia目前最强的A100加速卡开刀。MI250X的FP64向量计算能力达到47.9TF,FP64矩阵计算能力达到95.7TF,均为A100的4.9倍。而在AI领域常用的FP16和BF16矩阵计算中,MI250X的算力也达到了383TF,是A100的1.2倍。即便两者都用上了HBM2E,MI200的内存带宽也达到了3.2TB/s,远超A100的2TB/s。不过MI250X的功耗确实要高出不少,峰值状态下的功耗可以达到560W,而A100的峰值功耗为300W。
与英特尔这种IDM厂商不同,AMD在封装上基本吃透了与台积电合作带来的技术红利,尤其是台积电的3D Fabric封装技术集合,而Instinct MI200则是这些技术的集大成之作。作为首个采用多Die设计的GPU,Instinct MI200选用了两个SoC+8个HBM2E的方案,AMD在发布会上宣称这一设计的实现要归功于2.5D的Elevated Fanout Bridge(EFB)架构。
从图解上来看,AMD的EFB与台积电的InFO-L 2.5D封装技术可以说是从一个模子里刻出来的。在专门用于HBM集成的方案,目前可以做到这种规模的异构似乎也只有台积电的InFO-L和CoWoS-L,利用LSI(本地硅互联)芯片,为SoC到SoC与SoC到HBM提供高布线密度的互联。
其实英特尔也有类似的2.5D封装方案EMIB,只不过该方案是在基板内放入一个硅桥die。而反观AMD的EFB和台积电的LSI方案则是将其至于基板的模具中,模具内分布着一系列铜柱。相较之下,EMIB虽然可以做到更低的寄生电感,却也对于基板的加工提出了很高的要求,这也是为何只有英特尔这个基板大厂才使用EMIB的原因之一。不过随着IDM 2..0模式的展开,英特尔也将公开提供自己的制程、IP和封装技术,未来也许会有其他厂商的芯片开始用上EMIB。但目前来看,虽然增加了高度控制的挑战,但为了使用标准的基板降低成本,EFB和LSI明显是最优解。
在外观尺寸上,AMD选择了OAM和PCIe两种形式。OAM为开放计算项目(OCP)定下的通用加速器模组标准,对于想要规模化部署GPU或其他加速器来说,OAM可以提供更大的带宽。作为Facebook和微软共同推行的公开标准,OAM已经在服务器领域有了不小的规模,不仅是英特尔、AMD和英伟达这些半导体厂商,浪潮、联想、百度和阿里巴巴等其他服务器与公有云厂商也开始支持这一标准。
目前OAM的MI250和MI250X已经进入可交付阶段,从今年第三季度起,AMD就已经在为美国能源部的橡树岭国家实验室持续交付MI250X GPU了,用于组成美国首个ExaScale级别的超级计算机Frontier。除了OAM模组外,AMD也将在不久提供PCIe版本的MI210,用于非密集运算的场景。
结语
随着英特尔、三星和台积电在2.5D/3D封装技术上的逐渐成熟,服务器芯片将成为受益最大的产品,未来2+8甚至3+8的MCM GPU可能更加常见。英伟达、AMD与英特尔三家在服务器/数据中心市场上的动向,也侧面体现了IDM与Fabless厂商之间在技术选择上的差异。英特尔如果不能尽快在制程和封装上超越台积电这样的晶圆代工厂,在服务器市场的优势可能会越来越小。
在不久前结束的 “加速数据中心”发布会上,AMD正式公开了下一代服务器CPU Milan-X和GPU加速卡Instinct MI200。这两大产品系列不仅面向数据中心,也将面向一系列HPC和超算应用,把通用计算和AI性能推向极致。Instinct MI200作为GPU加速卡,更是成为超级计算机百亿亿级(Exascale)的算力的基本构成单元。
在市场合作上,AMD更是开始了新一轮的攻城略地,前不久刚和腾讯联合发布了星星海服务器产品后,如今Azure等一众公有云厂商也开始部署基于Milan-X的服务器,甚至将刚改名为Meta的Facebook也被拉拢至AMD阵营,宣布将在其数据中心部署AMD的服务器产品。
Milan-X:6nm的大缓存怪兽
继上一代Milan处理器推出后不到一年,AMD就发布了该芯片的6nm改进版Milan-X。今年上半年通过融合Chiplet和Die堆叠两大技术,在Ryzen桌面处理器上做了3D Chiplet架构的演示。如今第三代Epyc处理器Milan-X,将成为首个使用该技术的服务器产品。通过在Chiplet上堆叠缓存,Milan-X的L3缓存是Milan的三倍,达到了可怕的768MB。
MilanX / AMD
与英特尔一样,AMD在正式发售前并没有公布Milan-X的具体性能细节,而是通过合作伙伴的测试来展示了Milan-X在EDA和公有云应用中表现。在新思的VCS功能验证中,Milan-X在1小时内完成了40.6项任务,而同样核心数的Milan仅完成了24.4项。微软在基于Milan-X的Azure服务器中进行了早期测试,无论是在航天模拟,还是在汽车碰撞测试建模中,Milan-X都做到了50%以上的性能提升。
除此之外,AMD CEO苏资丰博士还透露了下一代5nm Epyc处理器Genoa的情报。基于Zen 4架构的Genoa将具备2倍的晶体管密度和2倍的能效,性能可以达到上一代的1.25倍以上。Genoa最高支持96个Zen 4核心,同时也将加入一系列新标准的支持,比如DDR5、PCIe 5.0和CXL。AMD还将推出基于5nm的Zen 4C核心的处理器Bergamo,专门针对要求多核多线程的云原生计算,最高核心数将达到128核,晚于Genoa发布。
Genoa计划在2022年量产和发布,届时很可能就是英特尔的Sapphire Rapids和AMD的Genoa在通用计算领域争雄了。
Instinct MI200:GPU终于迎来MCM时代了?
除了Milan-X之外,发布会的最大亮点其实是全球首个MCM GPU,Instinct MI200。同样基于台积电的6nm工艺,Instinct MI200系列单芯片的晶体管数目达到580亿,最高集成了220个计算单元。作为首个采用AMD CDNA2架构的服务器GPU,Instinct MI200的目标很明确,那就是将计算能力推向ExaScale级。
在CDN2架构和第二代HPC&AI专用矩阵核心的支持下,Instinct MI200实现了远超竞品的性能表现。数据对比环节,AMD选择拿Nvidia目前最强的A100加速卡开刀。MI250X的FP64向量计算能力达到47.9TF,FP64矩阵计算能力达到95.7TF,均为A100的4.9倍。而在AI领域常用的FP16和BF16矩阵计算中,MI250X的算力也达到了383TF,是A100的1.2倍。即便两者都用上了HBM2E,MI200的内存带宽也达到了3.2TB/s,远超A100的2TB/s。不过MI250X的功耗确实要高出不少,峰值状态下的功耗可以达到560W,而A100的峰值功耗为300W。
与英特尔这种IDM厂商不同,AMD在封装上基本吃透了与台积电合作带来的技术红利,尤其是台积电的3D Fabric封装技术集合,而Instinct MI200则是这些技术的集大成之作。作为首个采用多Die设计的GPU,Instinct MI200选用了两个SoC+8个HBM2E的方案,AMD在发布会上宣称这一设计的实现要归功于2.5D的Elevated Fanout Bridge(EFB)架构。
从图解上来看,AMD的EFB与台积电的InFO-L 2.5D封装技术可以说是从一个模子里刻出来的。在专门用于HBM集成的方案,目前可以做到这种规模的异构似乎也只有台积电的InFO-L和CoWoS-L,利用LSI(本地硅互联)芯片,为SoC到SoC与SoC到HBM提供高布线密度的互联。
其实英特尔也有类似的2.5D封装方案EMIB,只不过该方案是在基板内放入一个硅桥die。而反观AMD的EFB和台积电的LSI方案则是将其至于基板的模具中,模具内分布着一系列铜柱。相较之下,EMIB虽然可以做到更低的寄生电感,却也对于基板的加工提出了很高的要求,这也是为何只有英特尔这个基板大厂才使用EMIB的原因之一。不过随着IDM 2..0模式的展开,英特尔也将公开提供自己的制程、IP和封装技术,未来也许会有其他厂商的芯片开始用上EMIB。但目前来看,虽然增加了高度控制的挑战,但为了使用标准的基板降低成本,EFB和LSI明显是最优解。
在外观尺寸上,AMD选择了OAM和PCIe两种形式。OAM为开放计算项目(OCP)定下的通用加速器模组标准,对于想要规模化部署GPU或其他加速器来说,OAM可以提供更大的带宽。作为Facebook和微软共同推行的公开标准,OAM已经在服务器领域有了不小的规模,不仅是英特尔、AMD和英伟达这些半导体厂商,浪潮、联想、百度和阿里巴巴等其他服务器与公有云厂商也开始支持这一标准。
目前OAM的MI250和MI250X已经进入可交付阶段,从今年第三季度起,AMD就已经在为美国能源部的橡树岭国家实验室持续交付MI250X GPU了,用于组成美国首个ExaScale级别的超级计算机Frontier。除了OAM模组外,AMD也将在不久提供PCIe版本的MI210,用于非密集运算的场景。
结语
随着英特尔、三星和台积电在2.5D/3D封装技术上的逐渐成熟,服务器芯片将成为受益最大的产品,未来2+8甚至3+8的MCM GPU可能更加常见。英伟达、AMD与英特尔三家在服务器/数据中心市场上的动向,也侧面体现了IDM与Fabless厂商之间在技术选择上的差异。英特尔如果不能尽快在制程和封装上超越台积电这样的晶圆代工厂,在服务器市场的优势可能会越来越小。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
amd
+关注
关注
25文章
5190浏览量
132631 -
cpu
+关注
关注
68文章
10434浏览量
206521 -
gpu
+关注
关注
27文章
4413浏览量
126640
发布评论请先 登录
相关推荐
Nvidia与AMD新芯片,突破PCIe瓶颈
AMD 和 Nvidia 的 GPU 都依赖 PCI 总线与 CPU 进行通信。CPU 和 GPU 有两个不同的内存域,数据必须通过 PCI 接口从 CPU 域移动到 GPU 域(并返
AMD将推新GPU,效能媲美英伟达RTX 4080
据悉,AMD正努力研制新品级GPU,性能堪比英伟达的RTX 4080,而售价却只有后者的一半。据多个在线社区反映,AMD即将发布的Radeon RX 8000系列GPU效能与NVIDI
深入解读AMD最新GPU架构
GCN 取代了 Terascale,并强调 GPGPU 和图形应用程序的一致性能。然后,AMD 将其 GPU 架构开发分为单独的 CDNA 和 RDNA 线路,分别专门用于计算和图形。
发表于 01-08 10:12
•448次阅读
RISC-V内核突破百亿颗 RVV1.0如何解锁端侧AI市场应用潜能
RISC-V内核增长迅猛,2022年就实现了破百亿颗出货量。作为一款开源的RISC架构,其凭借轻量化、优秀的可扩展性与不断增强的软件兼容性吸引越来越多的企业采用。不断扩张的生态版图之下,RISC-V
发表于 12-01 13:17

NVIDIA与NTT DOCOMO联手打造全球首个GPU加速5G网络,欧盟要求苹果开放生态
大家好,欢迎收看河套IT WALK第113期。 NVIDIA与NTT DOCOMO合作推出了全球首个GPU加速的5G网络,这一突破性技术将改变我们对5G网络的认知和使用方式。欧盟对苹果提出了一个灵魂

英特尔第一超算Aurora:峰值性能达2百亿亿次,拥有世界最大GPU集群
计算机。 作为位于伊利诺伊州阿贡国家实验室的Aurora超级计算机的首席架构师和首席研究员,Olivier Franza在实现这一最具雄心的科学仪器中发挥了领导作用,更不用说它还是世界上最大的GPU集群了。 这给了Franza一些压力,他是Intel的22年资深员工,2016年作为系统硬件架构师加入Aurora项
拥有气场杀手锏!览邦F9 FreeBuds Plus多模式降噪耳机助你成为焦点!
一款拥有气场杀手锏的览邦F9 FreeBuds Plus多模式降噪耳机,让你轻松成为焦点! 作为一款顶级降噪耳机,览邦F9 FreeBuds Plus采用了最先进的多模式降噪技术。它能够有效地消除各种噪音干扰,让你在任何环境下都能享受到清晰的音乐质

景嘉微42亿元定增募资获受理 强化GPU芯片领域布局
据jonpeddie research称,英特尔的pc gpu市场份额在2020年至2022年保持在60%至72%,其余几乎由英伟达和amd占据。在除pc以外的gpu方面,nvidia从2020
首台2百亿亿次超级计算机安装完成!
Aurora超级计算机预计在2023年晚些时候投入使用。它将使用数万个Xeon Max“Sapphire Rapids”处理器、大量HBM2E内存和数据中心GPU Max“Ponte Vecchio”计算GPU,具备超过2 FP64 ExaFLOPS的性能。
AMD带领GPU进入Chiplet时代 RDNA3架构深入解读
11月3日,AMD 透露了其 RDNA 3 GPU 架构和 Radeon RX 7900 系列显卡的关键细节。

GPU平台生态:英伟达CUDA和AMD ROCm对比分析
成熟且完善的平台生态是 GPU 厂商的护城河。相较于持续迭代的微架构带来的技术壁垒硬实力,成熟的软件生态形成的强大用户粘性将在长时间内塑造 GPU厂商的软实力。以英伟达 CUDA 为例的软硬件

GPU的预测瞬态仿真分析
如今,图形处理单元 (GPU) 具有数百亿个晶体管。随着每一代新一代 GPU 的出现,GPU 中的晶体管数量不断增加,以提高处理器性能。然而,晶体管数量的增加也导致功率需求呈指数增长,
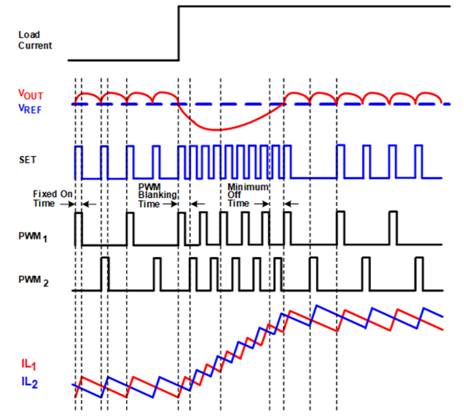
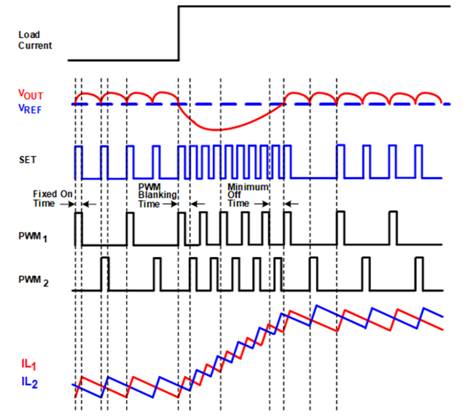
GPU的预测瞬态仿真分析
如今,图形处理单元 (GPU) 具有数百亿个晶体管。随着每一代新一代 GPU 的出现,GPU 中的晶体管数量不断增加,以提高处理器性能。然而,晶体管数量的增加也导致功率需求呈指数增长,





 工商网监
工商网监
评论