 如何用10行代码轻松在ZYNQ MP上实现图像识别
如何用10行代码轻松在ZYNQ MP上实现图像识别
本文来自赛灵思高级产品应用工程师,张超。如今各种机器学习框架的普及使得个人搭建和训练一个机器学习模型越来越容易。然而现实中大量的机器学习模型训练完后需要在边缘端部署,那么我们看看借助Xilinx Vitis-AI工具,如何仅仅使用10行代码,就能在ZYNQ MP器件上部署深度学习模型实现图像分类。
简介
Xilinx Vitis-AI 是用于 Xilinx 硬件平台上的 AI 推理的开发堆栈。它由优化的 IP、工具、库、模型和示例设计组成。
简单来说,它主要包含:
AI推理加速器IP,即DPU;
支持将AI模型优化 (Optimizer)、量化 (Quantizer)、最后编译 (Compiler) 成DPU运行指令集的整套工具;
支撑模型运行的运行时库(Vitis-AI runtime, Vitis-AI library);
更多具体介绍请 访问如下链接至官方文档:
https://github.com/Xilinx/Vitis-AI
https://www.xilinx.com/support/documentation/sw_manuals/vitis_ai/1_4/ug1414-vitis-ai.pdf
本案例中,我们将使用 Xilinx Kria KV260开发板(包含ZynqMP器件)为目标运行设备。
本文使用的Vitis-AI 版本为1.4, 使用的platform基于Vitis/Vivado 2020.2。为了方便快速部署,我们直接使用官方发布的Linux系统启动镜像, 并且使用Vitis-AI library为编程接口。
准备工作
开始工作前我们需要先搭建好运行环境,包括设置host端(X86机器)的交叉编译环境,以及 target端(KV260)的启动镜像烧写。
本文的主要目的是阐述 Vitis-AI Library 的使用,故运行环境的搭建不做过多介绍,可以完全参考以下链接中的步骤
“Step1: Setup cross-compiler”
“Step2: Setup the Target”
https://github.com/Xilinx/Vitis-AI/tree/master/setup/mpsoc/VART
注意因为KV260 的Vitis-AI 1.4 platform基于Vitis/Vivado 2020.2, 配置交叉编译环境使用的脚本为host_cross_compiler_setup_2020.2.sh
因为我们使用官方启动镜像,Step2中标注为“Optional”的步骤我们都可以省略。
当KV260成功启动,我们会在console中看到如下提示符:
root@xilinx-k26-starterkit-2020_2:~#
程序编译
可通过如下方式获得本案例中的代码,
git clone https://github.com/lobster1989/Image-classification-on-edge-with-10-lines-of-code.git
主要用到的文件为classification.cpp和Makefile。另外几个Jpeg文件可用于后续测试输入。
安装准备工作章节中配置好交叉编译环境后,切换到源码目录中直接运行make。make完成后文件夹中会生成执行文件“classification”。
运行演示
KV260 连接好串口,从SD卡启动运行(记得提前把执行文件和测试图片拷贝到SD下),
切换到执行文件和测试图片目录下,运行 ./classification.JPEG
分类结果如下:

代码分析
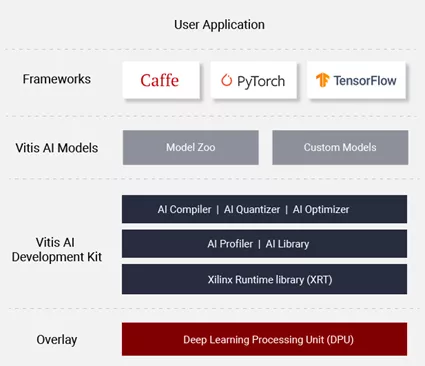
Vitis-AI包含了两组编程接口:VART (Vitis-AI Runtime) 比较底层,提供更大的自由度;Vitis-AI library属于高层次API,构建于 VART 之上,通过封装许多高效、高质量的神经网络,提供更易于使用的统一接口。
Vitis-AI Library的组成如下图,包含 base libraries, model libraries, library test samples, application demos几个部分:
base libraries提供底层接口;
model libraries是重要的部分,提供了主流模型(classification, detection, segmentation…) 的调用方法;
library test samples和application demos主要提供library的使用示例;
更多Vitis-AI library的细节可参考官方文档,
https://www.xilinx.com/support/documentation/sw_manuals/vitis_ai/1_4/ug1354-xilinx-ai-sdk.pdf
再来看本例子,如何用简单到10行代码实现图片分类:
int main(int argc, char* argv[]) {
std::string image_name = argv[1];
auto image = cv::imread(image_name);
auto network = vitis::create("resnet50");
auto result = network->run(image);
cout << "Classification result:" << endl;
for (const auto &r : result.scores){
cout << result.lookup(r.index) << ": " << r.score << endl;
}
}
源文件中除去include部分,只有10行代码,代码中最重要的有两句,第一句调用create方法创建了Classification类的一个实例,第二句调用run方法来运行神经网络获得推理结果。
auto network = vitis::create("resnet50");
auto result = network->run(image);
vitis::Classification 是 model libraries 中的一个基础类,其作用是进行图片分类,这个类中包含如下方法:
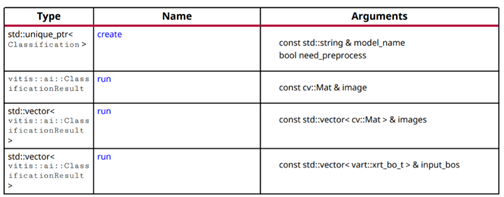
其中create方法接受一个模型名称作为参数,返回一个Classification类的实例。在安装了Vitis-AI Library的开发板上,已经训练编译好的模型文件放在开发板的/usr/share/vitis_ai_library/models/目录下,Vitis-AI Library会通过传递给create方法的模型名称来调用这些模型文件,比如我们用到的resnet50模型文件位置如下,

如果用户训练并编译好了自己的模型,也可以把自己的模型文件放到对应位置来使用。
run方法接受一个/一组图片作为输入,输出这个/这些图片的分类结果。其工作简单来说就是把模型文件和图片数据传送给DPU, DPU运行并输出推理结果,CPU再读回结果。
再看下添加了注释的代码片段,整个过程实际上非常简单明了。
int main(int argc, char* argv[]) {
std::string image_name = argv[1];
auto image = cv::imread(image_name); // 读入图片
auto network = vitis::create("resnet50"); // 用resnet50模型创建Classification类实例
auto result = network->run(image); //运行模型
cout << "Classification result:" << endl;
for (const auto &r : result.scores){
cout << result.lookup(r.index) << ": " << r.score << endl; //输出模型运行结果
}
}
除了Classification基础类, Vitis-AI Library包含了非常多的常用机器学习任务(classification, detection, segmentation…)的基础类。这些类的使用方法基本一致,
首先通过create方法创建基础类的实例,
通过getInputWidth()/getInputHeight()来获取模型需要的图片尺寸,
resize图片,
运行run方法来运行网络获得输出。
总结
通过这个例子,我们看到通过Vitis-AI工具,可以大大缩减模型到部署之间的距离。Vitis-AI包含了常用模型的Model-Zoo, 提供简单易用的编程接口,甚至可以让不熟悉机器学习或者FPGA的软件开发者都可以在极短的时间内在FPGA/SoC器件上部署神经网络应用。
编辑:jq
-
MP
+关注
关注
0文章
38浏览量
36028 -
图像识别
+关注
关注
8文章
445浏览量
37905 -
代码
+关注
关注
30文章
4554浏览量
66723 -
Zynq
+关注
关注
9文章
598浏览量
46608
原文标题:开发者分享 | 10行代码轻松在ZYNQ MP上实现图像识别
文章出处:【微信号:gh_2d1c7e2d540e,微信公众号:XILINX开发者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度学习视角下的猫狗图像识别实现

基于DSP的快速纸币图像识别技术研究
【瑞芯微RK1808计算棒试用申请】图像识别以及芯片评测
如何利用STM32F779微控制器来设置和执行图像识别
研发干货丨基于OK3399-C平台android系统下实现图像识别
使用ART-PI获取OV7670的图像来做图像处理和图像识别
如何实现图像识别?为什么要入局图像识别?
如何在APT-Pi上实现图像识别功能

10行代码轻松在ZYNQ MP上实现图像识别
模拟矩阵在图像识别中的应用






 工商网监
工商网监
评论