 文件系统中的日志系统是如何实现的
文件系统中的日志系统是如何实现的
日志
本文来聊聊文件系统中的日志系统,来看一个简单的日志系统是如何实现的。本文是接着前面的 xv6 系列,用到的一些前导知识不再说明,没看的可以先看一下。
文件系统设计中通常要考虑错误恢复,这是因为文件系统会涉及对磁盘的多次写操作,如果在写的过程中系统崩溃了,就会使得磁盘上的文件系统处于不一致的错误状态。
日志就是设计来解决因为系统崩溃导致的错误问题,本文就 来讲解怎么实现一个简单的日志系统。在 的日志系统中,文件操作方面的系统调用并不会直接对磁盘进行写操作,而是把对磁盘写操作描述包装成一个日志写在磁盘中,当该系统调用执行完成之后,再提交一个记录到磁盘上。
为什么日志可以解决文件系统操作中出现的崩溃呢?如果崩溃发生在提交之前,那么磁盘上的日志文件就不会被标记为已完成,恢复系统的代码就会忽视它,磁盘的状态就好像写操作从未进行一样。如果是在提交之后崩溃的,恢复程序会重演所有的写操作。在任何一种情况下,日志文件都使得磁盘操作对于系统崩溃来说是原子操作:在恢复之后,要么所有的写操作都完成了,要么一个写操作都没有完成。
上面的理论大都来自 文档,我们能了解到,最为重要的是实现写操作的原子性,那么怎样实现呢? 在磁盘上分配了一片日志区,假如现在内存中有一个缓存块准备同步到磁盘区域 A, 并不立即将该缓存块的数据写到磁盘区域 A,而是先写到磁盘的日志区(提交)。如果没有问题则将日志区的数据写到相应的磁盘区域 A。如果有问题,在提交之前发生了崩溃,则恢复代码忽略日志信息,区域 A 根本就没进行过写操作,当然就能够保证数据的一致性。如果在提交之后发生了崩溃,则恢复代码将日志区的数据重新写到磁盘区域 A,也保证了数据的一致性。
日志区也需要相应的数据结构来组织管理,相关的结构定义如下:
结构定义超级块struct superblock {
uint size; // Size of file system image (blocks) 文件系统大小,也就是一共多少块
uint nblocks; // Number of data blocks 数据块数量
uint ninodes; // Number of inodes. //i结点数量
uint nlog; // Number of log blocks //日志块数量
uint logstart; // Block number of first log block //第一个日志块块号
uint inodestart; // Block number of first inode block //第一个i结点所在块号
uint bmapstart; // Block number of first free map block //第一个位图块块号
};
文件系统的超级块,超级块中记录了文件系统的元信息,比如上述 的超级块记录了数据块、i 结点、日志块的数量和第一块的块号。
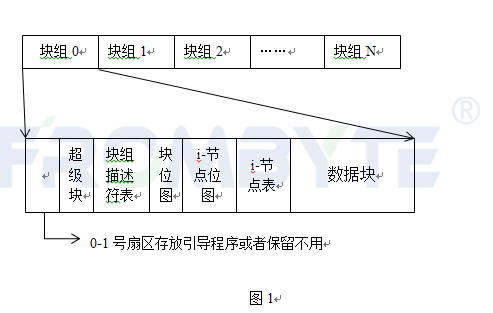
文件系统的总体布局如下:
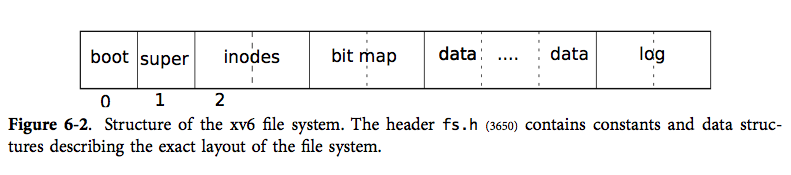
日志区位于文件系统的末尾,分为日志头(位于第一个日志块)和日志数据块。
日志头#define MAXOPBLOCKS 10 // max # of blocks any FS op writes#define LOGSIZE (MAXOPBLOCKS*3) // max data blocks in on-disk logstruct logheader { //日志头部
int n;
int block[LOGSIZE];
};
日志头用来记录每次日志的大小和位置关系信息。 来记录每次日志使用的空间大小,日志空间的总大小记录在超级块中(大小的单位是块),同时 也规定每次日志使用的块数也不能超过 。
是一个 型数组,元素个数最多为 ,用来记录位置关系。写入磁盘是先写入日志区,再写到磁盘的其他区域。这个日志区的磁盘块和其他区域的磁盘之间需要有一个映射关系,这个关系就记录在 数组中。举个例子: 表示日志块 记录的数据应放在 号磁盘块中。
struct log {
struct spinlock lock;
int start; //日志区第一块块号
int size; //日志区大小
int outstanding; // 有多少文件系统调用正在执行
int committing; // 正在提交
int dev; //设备,即主盘还是从盘,文件系统在从盘
struct logheader lh; //日志头
};
struct log log;
这个结构体只存在于内存,用来记录当前的日志信息。这个日志信息也是一个公共资源要避免竞争条件所以配了一把锁。 三个属性值从超级块中读取。其他的信息见注释,具体含义后面慢慢讲解。下面直接来看日志的函数实现:
函数实现void readsb(int dev, struct superblock *sb) //读超级块
{
struct buf *bp;
bp = bread(dev, 1); //读取超级块数据到缓存块
memmove(sb, bp-》data, sizeof(*sb)); //移动数据
brelse(bp); //释放缓存块
}
这个函数用来读取超级块的内容,超级块在第一块,第零块是引导块。调用 将数据从磁盘读取到缓存块中,然后将缓存块中超级块的数据复制一份到内存中定义的超级块数据结构中去,最后再释放缓存块的锁,因为 调用 获取了锁,使用完该缓存块就该释放,详见磁盘那篇文章
void initlog(int dev)
{
if (sizeof(struct logheader) 》= BSIZE)
panic(“initlog: too big logheader”);
struct superblock sb; //定义局部变量超级块sb
initlock(&log.lock, “log”); //初始化日志的锁
readsb(dev, &sb); //读取超级块
/*根据超级块的信息设置日志的一些信息*/
log.start = sb.logstart; //第一个日志块块号
log.size = sb.nlog; //日志块块数
log.dev = dev; //日志所在设备
recover_from_log(); //从日志中恢复
}
这个函数来初始化日志的信息,前面应该都很好理解,超级块中记录的有一些元数据,读取超级块来初始化一些日志信息,比如日志的大小位置。最后一点不太好理解的地方便是 故名思意,从日志中恢复,每次启动调用初始化函数它都会执行这个函数来保证文件系统的一致性,关于这个函数我们后面再详述。
static void install_trans(void)
{
int tail;
for (tail = 0; tail 《 log.lh.n; tail++) {
struct buf *lbuf = bread(log.dev, log.start+tail+1); // read log block 读取日志块
struct buf *dbuf = bread(log.dev, log.lh.block[tail]); // read dst 读取日志块中数据本身应在的磁盘块
memmove(dbuf-》data, lbuf-》data, BSIZE); // copy block to dst 将数据复制到目的地
bwrite(dbuf); // write dst to disk 同步缓存块到磁盘
brelse(lbuf); //释放 lbuf
brelse(dbuf); //释放 dbuf
}
}
就干了一件事:将磁盘中的日志块数据复制到应在的磁盘块中去,前面文章曾说过针对一些列的磁盘操作,都是先在对应的缓存块中操作再同步到相应的磁盘块中去。所以先读取两部分的数据到内存中的缓存块(不一定真的从磁盘中读出来,要视磁盘数据在内存中是否有缓存),在内存中把数据复制过去,再同步到磁盘块中去,最后释放掉缓存块。
典型的日志使用方式如下:
begin_op();
。..。..。..。
bp = bread(。..);
bp-》data[。..] = 。..;
log_write(bp);
。..。..。..。
end_op();
和 是一对儿,配套使用,表明一个文件系统调用的开始和结束。通常文件系统调用就是读写磁盘上的数据,所以同样的先调用 读取数据,然后修改,但是同步写到磁盘上不是直接调用 而是使用 来替代。为什么这么操作,我们按照上面的顺序一个一个来看:
void begin_op(void)
{
acquire(&log.lock);
while(1){
if(log.committing){ //如果日志正在提交,休眠
sleep(&log, &log.lock);
} else if(log.lh.n + (log.outstanding+1)*MAXOPBLOCKS 》 LOGSIZE){
// this op might exhaust log space; wait for commit. 如果此次文件系统调用涉及的块数超过日志块数上限,休眠
sleep(&log, &log.lock);
} else {
log.outstanding += 1; //文件系统调用加1
release(&log.lock); //释放锁
break; //退出循环
}
}
}
表明一个文件系统调用开始,它将一直等待直到日志处于未提交状态,直到有足够的日志空间保存当前所有调用的写入。这个足够的空间是保守估计的, 假设每个系统调用可能写入 个块, 表示正在执行的系统调用个数, 就表示加上自身这个系统调用,这个数乘以 就表示当前并发的系统调用可能写入的块数, 表示当前的日志空间已经使用的块数,它们两者之和如果小于日志空间,则可以继续下一步,否则等待。
若能继续下一步,表示日志空间的空闲区域足够容纳当前系统调用的写入操作,则执行该文件系统调用,将 数量加 ,表示当前正执行的系统调用个数增加 个。
void log_write(struct buf *b)
{
int i;
if (log.lh.n 》= LOGSIZE || log.lh.n 》= log.size - 1) //当前已使用的日志空间不能大于规定的大小
panic(“too big a transaction”);
if (log.outstanding 《 1) //如果当前正执行的系统调用小于1
panic(“log_write outside of trans”);
acquire(&log.lock);
for (i = 0; i 《 log.lh.n; i++) {
if (log.lh.block[i] == b-》blockno) // log absorbtion
break;
}
log.lh.block[i] = b-》blockno;
if (i == log.lh.n)
log.lh.n++; //日志空间使用量加1
b-》flags |= B_DIRTY; // prevent eviction 设置脏位,避免缓存块直接释放掉了
release(&log.lock);
}
就是 一个替代品, 直接设置缓存块的脏位然后请求磁盘同步到磁盘上去。而 只是设置缓存块的脏位并未立即进行磁盘请求,而是后面提交的时候统一同步写到磁盘。
同一个块在单个事务中多次写入的时候,会先在 数组中查找是否记录了当前缓存块,如果记录了,就使用当前的日志块,如果没有记录,分配一个日志块, 数组更新信息。这样操作即使一个块在单个事务中多次写入,也只会占用一个日志块,节省了日志空间,这种优化操作就叫做吸收。
如果调用了 之后调用 释放缓存块,这时候日志还没有提交,则可能会出现缓存块引用为 0,但数据脏的情况,具体例子可参考 函数。在这儿就回答了磁盘 一文遗留的一个问题,在 函数分配缓存块的时候一定要寻找引用为 0 且脏位没有设置的缓存块。因为就算缓存块的引用为 0,只要数据脏,则代表该缓存块仍在使用当中。
void end_op(void)
{
int do_commit = 0;
acquire(&log.lock); //取锁
log.outstanding -= 1; //文件系统调用减1
if(log.committing) //如果正在提交,panic
panic(“log.committing”);
if(log.outstanding == 0){ //如果正在执行的文件系统调用为0,则可以提交了
do_commit = 1;
log.committing = 1;
} else {
// begin_op() may be waiting for log space,
// and decrementing log.outstanding has decreased
// the amount of reserved space.
wakeup(&log); //唤醒因日志空间不够而休眠的进程
}
release(&log.lock);
if(do_commit){ //如果可以提交
// call commit w/o holding locks, since not allowed
// to sleep with locks.
commit(); //提交
acquire(&log.lock); //取锁
log.committing = 0; //提交完之后设为没有处于提交状态
wakeup(&log); //日志空间已重置,唤醒因正在提交和空间不够而休眠的进程
release(&log.lock); //释放锁
}
}
基本上是 相反的操作,它表示系统调用结束,将 减 1。如果 减为 0,表示当前没有文件系统调用在进行,则可以提交事务了:设置 和 t 属性为 1,具体提交操作在后面进行。
如果 不为 0,则唤醒休眠在 上的进程。前面 会因为日志空间可能不够用而休眠,在这儿唤醒。可能有朋友疑惑,在这儿唤醒有什么用, 减 1 但是日志空间已经被占用了,似乎在这儿唤醒无用。这里要注意 中的计算空间的式子:,这是一个很保守的估计,当前系统调用完成之后 的值会变大, 的值会减 1,因此这个式子的总和完全可能变小,所以在这儿唤醒是有作用的。
执行提交的过程主要就是调用 函数,提交之后修改日志提交状态为 0 表示并未处于提交状态,这时候日志空间也已经清空有足够的日志空间可以使用,所以唤醒休眠在 上的进程。
接下来看具体的日志提交:
static void commit()
{
if (log.lh.n 》 0) {
write_log(); // Write modified blocks from cache to log
write_head(); // Write header to disk -- the real commit
install_trans(); // Now install writes to home locations
log.lh.n = 0;
write_head(); // Erase the transaction from the log
}
}
static void write_log(void) //将缓存块写到到日志区
{
int tail;
for (tail = 0; tail 《 log.lh.n; tail++) {
struct buf *to = bread(log.dev, log.start+tail+1); // log block
struct buf *from = bread(log.dev, log.lh.block[tail]); // cache block
memmove(to-》data, from-》data, BSIZE);
bwrite(to); // write the log
brelse(from);
brelse(to);
}
}
static void write_head(void) //将日志头写到日志区第一块
{
struct buf *buf = bread(log.dev, log.start); //读取日志头
struct logheader *hb = (struct logheader *) (buf-》data); //类型转换
int i;
hb-》n = log.lh.n; //日志记录大小
for (i = 0; i 《 log.lh.n; i++) {
hb-》block[i] = log.lh.block[i]; //位置信息
}
bwrite(buf); //将日志头同步到磁盘
brelse(buf);
}
static void read_head(void) //读取日志头信息
{
struct buf *buf = bread(log.dev, log.start); //日志头在日志区第一块
struct logheader *lh = (struct logheader *) (buf-》data); //地址类型转换
int i;
log.lh.n = lh-》n; //当前日志块数
for (i = 0; i 《 log.lh.n; i++) {
log.lh.block[i] = lh-》block[i]; //当前日志位置信息
}
brelse(buf);
}
这几个函数应该很好理解了,看注释应该都能明白就不一一解释了,在这儿主要说一些提交的具体过程:
首先判断日志头中的 是否大于 0,大于 0 表示有日志要提交,否则日志为空,不用提交也无可提交。
如果有日志要提交,则先根据内存中的日志头中的 数组记录的信息,将内存中的缓存块写到日志区。
然后将内存中的日志头同步到磁盘的日志头中去。这一步代表提交点,完成这一步表示已提交,反之则没有提交。
经过提交点之后,再根据内存中的日志头中的 数组记录的信息,将日志区的数据复制到磁盘的其他区域。
之后将内存中的日志头的 设为 0,再同步日志头到磁盘。表示已完整的完成一次事务操作,清除日志空间,为下一次事务做准备。
static void recover_from_log(void)
{
read_head(); //读取日志头
install_trans(); // if committed, copy from log to disk
log.lh.n = 0;
write_head(); // clear the log
}
,从日志中恢复,可以看出这个函数与 很相似,只不过 需要从磁盘将日志头读出,而 的时候日志头本身就在内存当中不用读取,其他部分一模一样不再解释。
这里也解释了为什么这个日志是一个 ,可以看出如果能从日志中恢复,它是将提交所做的事情重新做了一遍。
在这儿再来看看为什么 能够进行错误恢复,使得磁盘中的数据保持一致性呢?如果在提交之前发生了崩溃,则磁盘上的日志不会被标记为已完成,也就是日志头中的 为 0。因此在进行恢复操作执行 函数时, 读取日志头的时候发现 n 为 0,则执行 的时候根本就不会进入 循环进行实际的操作。也即如果在提交之前发生崩溃,对磁盘所有的操作都发生日志区,恢复代码直接忽略该日志,不会将日志中的数据同步到磁盘的其他区域,也就保证了磁盘中文件系统的一致性。
如果崩溃发生在提交之后,则磁盘中的日志头 n 不为 0,恢复代码将根据 数组记录的信息,循环 n 次把所有使用的日志块同步到磁盘的其他区域。对磁盘所有的写入操作先是写入了日志区,恢复的时候又从日志区同步到磁盘相应的其他区域,这也就保证了磁盘中数据的一致性。
所以因为日志的存在,对磁盘所有的写入操作都先是写到日志区,再同步到磁盘的其他区域。使得对磁盘的写入操作是一种原子操作,要么写入操作全部完成,要么好像根本就没有进行写入操作一样(实际上日志区是有写入操作的),因此这种原子写入操作保证了磁盘文件系统的一致性。
好啦,关于 的文件系统的日志层就聊到这里,有什么错误还请批评指正,也欢迎大家来同我讨论交流学习进步。
责任编辑:haq
-
代码
+关注
关注
30文章
4553浏览量
66678 -
日志
+关注
关注
0文章
126浏览量
10522
原文标题:如何实现一个简单的日志系统
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【嵌入式SD NAND】基于FATFS/Littlefs文件系统的日志框架实现
【嵌入式SD NAND】基于FATFS/Littlefs文件系统的日志框架实现

鸿蒙轻内核源码分析:虚拟文件系统 VFS
服务器数据恢复—ocfs2文件系统被误格式化为Ext4文件系统的数据恢复案例
Linux的文件系统特点
如何把文件系统烧到EMMC并从EMMC加载

分布式文件系统的设计原理是什么?
事务性日志结构文件系统的设计及实现
服务器数据恢复- Ext4文件系统服务器数据恢复案例
谈谈什么是文件系统 文件系统的功能与特点
适用于Linux的最佳通用文件系统 Linux文件系统的安装

Linux proc文件系统详解







 工商网监
工商网监
评论