 NVIDIA GPU助力提升模型训练和推理性价比
NVIDIA GPU助力提升模型训练和推理性价比
无量推荐系统承载着腾讯PCG(平台与内容事业群)的推荐场景,包括: 腾讯看点(浏览器、QQ看点、商业化)、腾讯新闻、腾讯视频、腾讯音乐、阅文、应用宝、小鹅拼拼等。无量推荐系统支持日活跃用户达数亿级别,其中的模型数量达数千个,日均调用服务达到千亿级别。无量推荐系统,在模型训练和推理都能够进行海量Embedding和DNN模型的GPU计算,是目前业界领先的体系结构设计。
传统推荐系统面临挑战
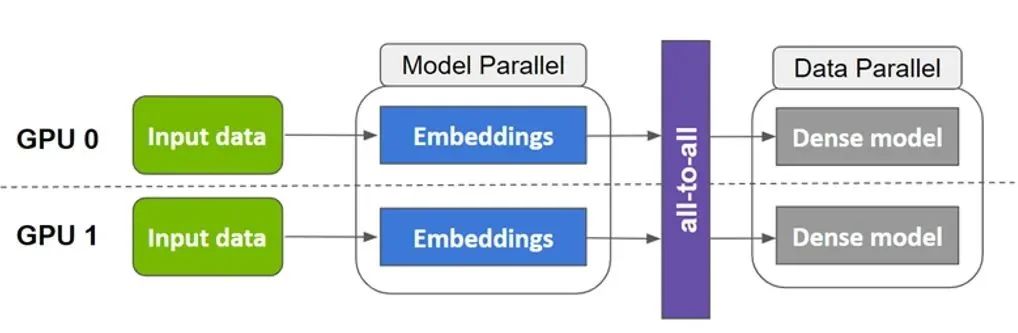
传统推荐系统具有以下特点: 训练是基于参数服务器的框架,解决海量数据和稀疏特征的分布式训练问题。推理通常分离大规模Embedding和DNN,只能进行DNN的GPU加速。 所以,传统的推荐系统架构具有一些局限性:1. 大规模分布式架构有大量的额外开销,比如参数和梯度的网络收发。2. 随着DNN模型复杂性的的进一步提升,CPU的计算速度开始捉襟见肘。 随着业务的快速增长,日活用户增多,对其调用数量快速增加,给推荐系统后台带来了新的挑战:1. 模型更加复杂,计算量更大,但是参数服务器的分布式架构有效计算比很低。2. 海量Embedding因为规模庞大,查询和聚合计算难以有效利用GPU高性能显存和算力的优势。
GPU助力提升模型训练和推理性价比
基于以上的挑战,腾讯PCG(平台与内容事业群)选择使用基于NVIDIA A100 GPU的分布式系统架构来创建无量推荐系统。
1. 通过多级存储和Pipeline优化,在HPC上完成大规模推荐模型的GPU的高性能训练。2. 基于特征访问Power-law分布的特性,GPU缓存高频特征参数,同时从CPU中动态获取低频特征参数,实现了大规模推荐模型完整的GPU端到端模型推理。
腾讯PCG有多种类型的推荐业务场景。比如信息流推荐的QQ浏览器、QQ看点、新闻推荐的腾讯新闻、视频推荐的腾讯视频、微视、App推荐的应用宝、以及腾讯音乐的音乐推荐和阅文集团的文学推荐。
无量推荐系统承载了这些推荐业务场景的模型训练和推理服务。基于传统的推荐系统架构,无量推荐系统使用大量CPU资源,通过分布式架构可以扩展到TB级模型的训练和部署,取得了巨大的成功。随着业务的快速增长,日活用户增多,对其调用数量快速增加,传统架构局限性限制了推荐系统的架构扩展和性能提升。
通过使用GPU训练和推理,单机多卡的GPU算力可以达到数十台CPU机器的算力,节省了大量的额外分布式开销。通过充分利用A100 GPU高性能显存快速访问Embedding,以及并行算力处理DNN推理,单张A100 GPU可以在相同的延迟下推理10倍于CPU的打分样本。目前基于GPU的推荐架构可以提升模型训练和推理性价比1~3倍。
未来,无量推荐系统将不断优化推荐模型在GPU上的应用,利用HPC多机多卡,混合精度等能力,进一步提高推荐场景使用GPU的性价比。
重磅!NVIDIA行业微站一睹为快!内容涵盖NVIDIA主要的12大行业方案,以及NVIDIA当期重点产品资料。
责任编辑:haq
-
NVIDIA
+关注
关注
14文章
4588浏览量
101702
原文标题:NVIDIA A100 GPU助力腾讯PCG加速无量推荐系统
文章出处:【微信号:murata-eetrend,微信公众号:murata-eetrend】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
利用NVIDIA组件提升GPU推理的吞吐
自然语言处理应用LLM推理优化综述

Torch TensorRT是一个优化PyTorch模型推理性能的工具

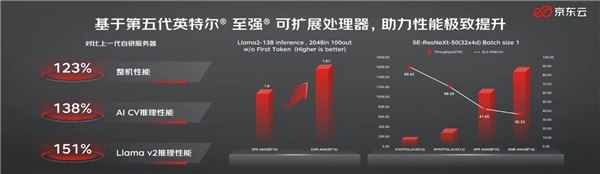
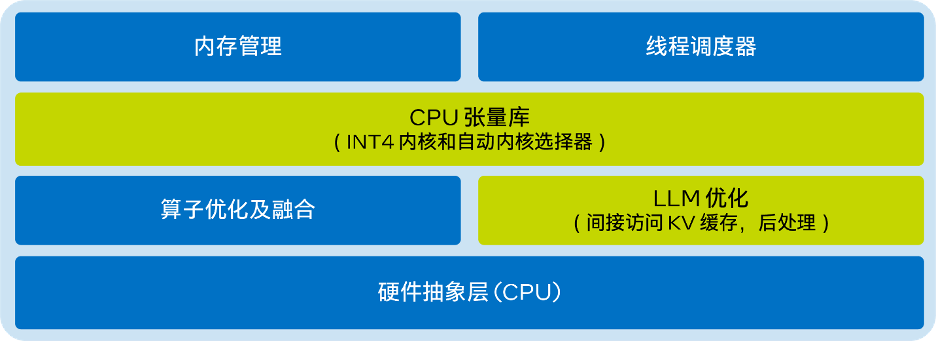
CPU也可以完美运行大模型 英特尔第五代至强重磅发布
用上这个工具包,大模型推理性能加速达40倍
NVIDIA 为部分大型亚马逊 Titan 基础模型提供训练支持

NVIDIA Merlin 助力陌陌推荐业务实现高性能训练优化
中国计算机大会现场王海峰揭秘文心大模型4.0
现已公开发布!欢迎使用 NVIDIA TensorRT-LLM 优化大语言模型推理

Nvidia 通过开源库提升 LLM 推理性能
最新MLPerf v3.1测试结果认证,Gaudi2在GPT-J模型上推理性能惊人

求助,为什么将不同的权重应用于模型会影响推理性能?
如何提高YOLOv4模型的推理性能?
NVIDIA AI 技术助力 vivo 文本预训练大模型性能提升

NVIDIA GPU 助力三维家打造 3D 垂类大模型,引领家居设计变革






 工商网监
工商网监
评论