 剖析GPU分支分歧对性能的影响
剖析GPU分支分歧对性能的影响
在先前文章中,我们谈到现代GPU发展出SIMT(Single Instruction Multiple Thread)的执行结构,硬件线程池的线程们有相对独立的运行上下文,以Warp为单位分发到一组处理单元按SIMD的模式运行。
这些Warp内的线程共享同样的PC,以锁步的方式执行指令,但是每个线程又可以有自己的执行分支。很自然衍生的一个问题就是现代GPU如何有效的处理Branch Divergence(分支分歧)?
一方面为适应复杂图形渲染以及通用计算的要求,GPU编程语言像其它高级语言一样需要支持各种各样的流控制(Flow Control)指令,比如ifswitchdoforwhile等等,这些指令都会导致分支分歧。
另一方面GPU并行计算的特点要求所有处理单元整齐划一地执行相同指令,才能够取得性能最大化。如何较好地解决这两种不同要求导致的冲突,一直是GPU研究中的热点难点问题。在这里笔者没有能力深入探讨,只是浅尝辄止做一般介绍,主要求这个系列内容完整,不足甚至谬误之处,请各位看官不吝指正。
一,分支分歧对性能的影响
这一节我们首先来讨论下分支分歧对GPU性能的影响。以如下ifelse代码为例,我们看下GPU一般是如何来处理分支分歧的?
if (cond) {。。。} else {。。。}
假设一个Warp中有16个线程判断条件为真,另外16个线程条件为假,所以一半线程会执行if中的语句,另一半线程执行else中的语句。这看起来像个悖论,我们知道Warp中的线程同一时刻只能执行相同的指令。
实际上遇到分支分歧时GPU会顺序执行每个分支路径,而禁用不在此路径上的线程,直到所有有线程使能的分支路径都走完,线程再重新汇合到同一执行路径。每个分支都有些线程不干活或者干无用功,Warp实际上需要执行的指令数目大增。
假设每个分支任务量大致相同,分支分歧造成的性能损失少则原先的一半,最坏的情况如果每个线程执行分支都不一致,性能下降为最高时候的1/32。
所以无论在设计算法还是分配处理数据的时候,我们都要小心尽量避免同一个Warp内线程出现分支分歧的状况,在遇到流控制指令的时候,最好能够选择同样的路径。
二,如何实现Reconvergence
上一节我们讲了Warp的线程产生了分支分歧之后,为求性能最佳,不可能让它们一直放任自流,最终还是要尽可能在合适时机把它们重新汇合(Reconverge)起来。但这一切是如何实现的呢?
按照参考1的说法,“The SM uses a branch synchronization stack to manage independent threads that diverge and converge” 。下面根据可接触到的文献我们看看大概是如何实现的,不一定跟GPU产商的实际做法一致。
我们称这个Warp运行时栈为SIMT Stack,每个Warp拥有一个SIMT栈用于处理SIMT执行模式中的分支分歧。
首先我们需要先确定分支分歧的最近重汇合点(Reconvergence Point),一般可以选用造成分支分歧节点的直接后序支配节点(Immediate post-dominator,若控制流图的节点n 到终结节点的每一条路径均要经过节点d,则称节点d后序支配节点n,如d与n之间没有任何其他节点后序支配n,则称节点d直接后序支配节点n)。
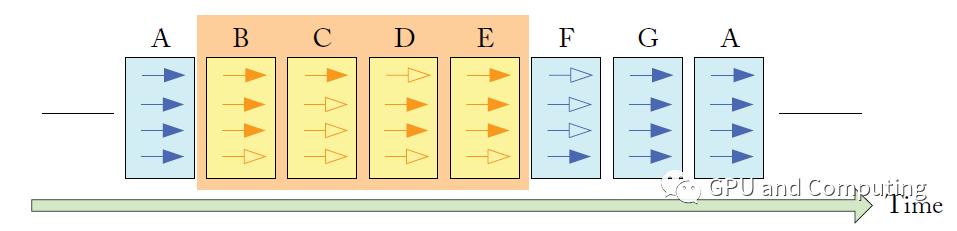
这可以通过编译时的控制流分析得到。左边是我们假想的一段GPU伪代码,右边是对应的控制流图,我们假设SIMD通道的数目是4,每个节点边上的掩码数字代表通道上线程在该节点基本块有没有使能。
SIMT栈结构每个条目由执行指令PC、分支重汇合PC(RPC)和使能线程掩码三部分组成。执行流从节点B分支分歧到节点E重新汇合时SIMT栈的更新过程。执行的时候,遇到流控制指令,我们将各个分支依次入栈,栈顶条目的PC会被送到取指单元开始相应分支路径的处理。
只有条目掩码中使能的线程会处于活跃状态,当下一条PC等于栈顶条目RPC的时候,说明该分支已经到了汇合点,栈顶条目会被弹出,开始下一分支的处理以至所有执行线程汇合并共同执行接下来的指令。值得注意的是真实环境下GPU都设计有一些特殊指令来维护SIMT栈。
下图表示上面代码在时间轴上的执行过程,实心箭头表示对应线程在该执行节点处于活跃状态,反之空心箭头代表不活跃状态。
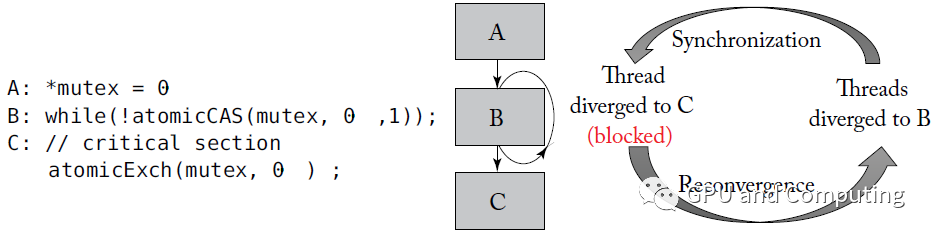
基于SIMT栈的Reconvergence方案并不完美,其中一个很大的问题是Warp内线程细粒度同步的时候很容易引发死锁。按照Nvidia的说法,“algorithms requiring fine-grainedsharing of data guarded by locks or mutexes can easily lead to deadlock,depending on which warp the contending threads come from.”。
以下面代码为例,某幸运线程拿到锁之后,在最近重汇合点C等着与大部队接头,不幸的是它无法执行下面的Exch指令以释放锁,导致其它线程只能在B处空转,形成死锁。
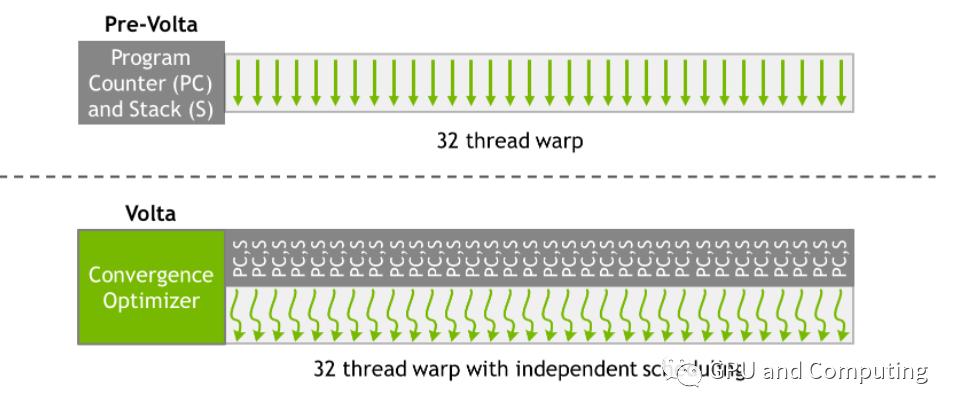
从更高的层次上理解,分支分歧导致的顺序执行只发生在Warp内的线程,Warp之间却相互不受干扰,这种不一致的处理方式对算法移植的适应性还是可预测性都会带来影响。Nvidia从Volta GPU开始做出了改进。
提出了“Independent Thread Scheduling”的方法,使得所有线程无关所在Warp可以具有同样并发执行能力,为此相比之前的GPU其Warp内所有线程共享PC以及运行栈,Volta GPU的线程都分别有各自的PC和运行栈,如下图所示。
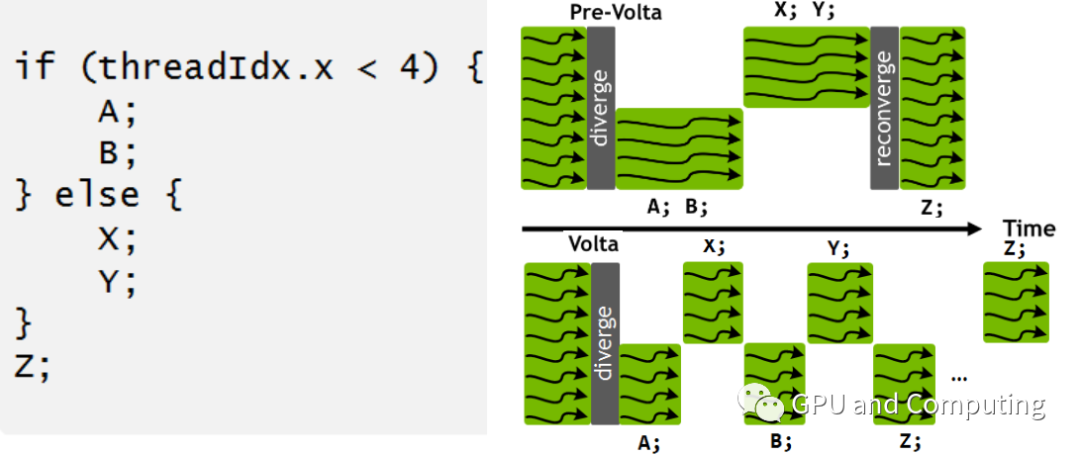
如此针对同样的GPU程序以及分支分歧,Volta与之前的GPU相比有截然不同的调度行为。我们注意到在Volta中所有的Warp线程并没有一起强制汇合执行Z基本块,主要考虑到Z可能作为生产者需要提供其它执行分支依赖的的数据。
回到我们先前死锁的例子,在Volta中这个死锁便可迎刃而解。如果我们明显了解相关分支不存在同步行为,为优化性能计,CUDA提供了 __syncwarp() 函数以便强制汇合。
主要参考资料:
NVIDIA Tesla: A Unified Graphics and Computing Architecture
Dynamic Warp Formation and Scheduling for Efficient GPU Control Flow
https://developer.nvidia.com/blog/inside-volta/
General-Purpose Graphics Processor Architectures
编辑:jq
-
gpu
+关注
关注
27文章
4400浏览量
126539 -
PC
+关注
关注
9文章
1948浏览量
152765 -
编程
+关注
关注
88文章
3438浏览量
92316
原文标题:近距离看GPU计算(3)
文章出处:【微信号:gh_6fde77c41971,微信公众号:FPGA干货】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NVLink技术之GPU与GPU的通信

超微gpu服务器评测
英伟达和华为/海思主流GPU型号性能参考

揭秘GPU: 高端GPU架构设计的挑战

Git命令之本地分支与远程分支关联和解除

GPU在深度学习中的应用与优势
Mali GPU性能分析工具
一文带你详解芯片--SL8541e-系统性能优化
UWA推出全新GPU性能测评工具,支持多款PowerVR芯片优化
Bifrost GPU可编程核心的顶级布局、优势和着色器核心功能
Mali-Valhall系列GPU可编程内核
基于磁贴的GPU架构优缺点
NVIDIA Hopper GPU上的新cuBLAS12.0功能和矩阵乘法性能





 工商网监
工商网监
评论