 存储与GPU性能皆已成倍增长,IO表现为何迟迟不见好转?
存储与GPU性能皆已成倍增长,IO表现为何迟迟不见好转?
存储与GPU性能皆已成倍增长,IO表现为何迟迟不见好转?
伴随着HPC、自动驾驶、深度学习和VR/AR需求的不断增加,IO性能也在逐步凸显瓶颈,尤其是GPU与存储之间的读写。处理器速度已经从KHz进化至了GHz,VRAM从KB进化至了GB,IO速度也从KB/s进化至了GB/s,然而GB/s的大幅度改善从直观角度来看依然像是MB/s。
比如在有线连接的VR应用中,图形需要经过电脑进行处理,再经有线传输显示在VR屏幕上,这就引发了高延迟和长读取时间等问题。这不禁让人开始遐想,在CPU、GPU和存储都已经革新换代的情况下,我们是否真正有效地应用了硬件性能?为此微软和英伟达都提出了直接存储的概念来改善IO的现状。
微软:Windows上的DirectStorage
微软在不久前的Windows 11发布会上重点提到了DirectStorage技术,这是一个最初为主机设计的DirectX API,如今微软也将把这一技术带到PC上。
在当前NVMe SSD和PCIe技术的演进下,存储带宽远超旧式的硬盘存储技术,过去10MB每秒的速度已经达到数GB每秒。但PC上的图形工作量也在逐步进化,数据量的增加对于读取提出了更高的要求。过去大量数据的读取只需要少量的IO请求,但如今的图形渲染会将材质等资源分成小块,只有在场景提出要求时载入所需的部分,如此一来虽然提高了效率,却引入了更多IO请求。

当前的GPU资源读取流程 / 微软
而目前的存储API并没有对大量IO请求作出优化,因此拖累了NVMe,使得读写瓶颈愈发明显。即便采用高端的PC硬件,也无法饱和利用存储带宽优势。除此之外,这些数据往往需要经过压缩传输下一个环节,传入内存后,还要CPU进行一部分解压工作,最后再传入GPU显存里,这样一来每个节点都存在效率损失。
而DirectStorage采用了全新的路径,从存储读取的数据传给内存后,直接传给GPU显存。而GPU对于这些数据的解压速度远快于CPU,所以极大地优化了IO性能。
英伟达:RTX IO和Magnum IO GPUDirect Storage
英伟达在RTX 30系列显卡上引入了RTX IO,面向消费市场,提升游戏场景下的读取速度。英伟达称RTX IO将与微软的DirectStorage结合,与传统硬盘下的存储API相比,可将IO性能提高百倍。过去需要数十个CPU内核的工作全部交由RTX GPU来处理。
值得一提的是,英伟达的RTX IO虽然也用到了微软的DirectStorage,但该技术并没有将数据传输到内存,而是直接由SSD转向GPU。微软一名图形开发者在GSL 2021大会上表示,未来DirectStorage的目标也是绕过系统内存。
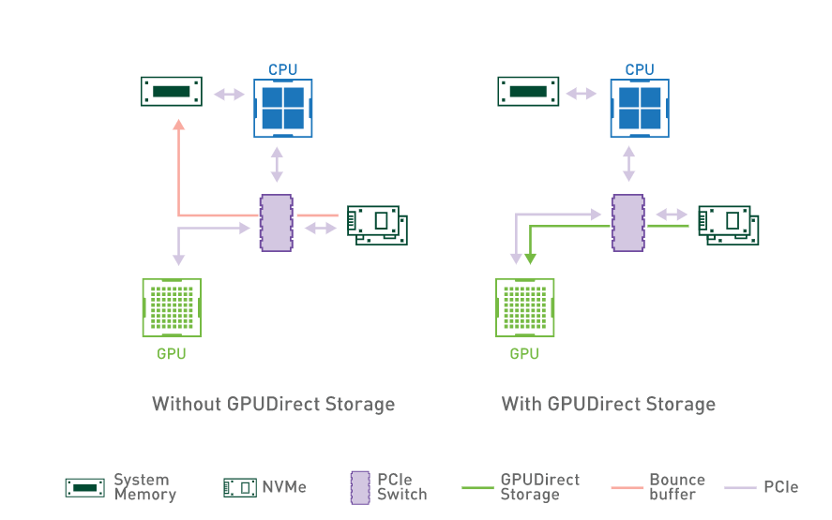
GDS技术 / 英伟达
除了消费市场外,英伟达在HPC市场也推出了对应的直接存储技术,Magnum IO GPUDirect Storage(GDS)。GDS技术同样是一个绕过CPU的技术,与消费级GPU不同,HPC场景下往往要用到多块GPU,如此一来受IO延迟和CPU的影响更大。GDS在本地存储与GPU显存之间建立直接的数据通道,消除了CPU引入的延迟和读写瓶颈。
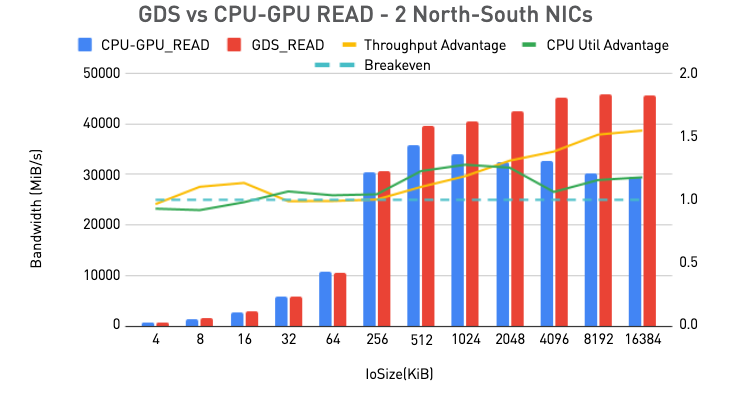
GDS与CPU传输至GPU读取性能对比 / 英伟达
在运用GDS后,带宽提升达到1.5倍,与传统CPU回弹缓冲的数据路径相比,CPU利用率也有2.8倍的提升。
目前英伟达已经将这一技术加入到其HGX AI超算中,DDN、VAST和WEKA三家公司已经开始了相关产品的量产,而IBM、美光等五家厂商也在积极引入这一技术。三星、铠侠、西数和戴尔等厂商也开始了GDS的早期集成与认证计划。
小结
直接存储技术进一步放大了GPU厂商与存储厂商的优势,目前HPC市场前景巨大,英伟达在相关业务上的盈利已经让其看到了商机。不仅是GPU,英伟达采用Arm架构的Grace CPU同样引入了NVLink这样的数据传输改善方案。在这样的性能改善下,即便存储方案不同,英伟达的GPU也很可能成为HPC应用的首选。
伴随着HPC、自动驾驶、深度学习和VR/AR需求的不断增加,IO性能也在逐步凸显瓶颈,尤其是GPU与存储之间的读写。处理器速度已经从KHz进化至了GHz,VRAM从KB进化至了GB,IO速度也从KB/s进化至了GB/s,然而GB/s的大幅度改善从直观角度来看依然像是MB/s。
比如在有线连接的VR应用中,图形需要经过电脑进行处理,再经有线传输显示在VR屏幕上,这就引发了高延迟和长读取时间等问题。这不禁让人开始遐想,在CPU、GPU和存储都已经革新换代的情况下,我们是否真正有效地应用了硬件性能?为此微软和英伟达都提出了直接存储的概念来改善IO的现状。
微软:Windows上的DirectStorage
微软在不久前的Windows 11发布会上重点提到了DirectStorage技术,这是一个最初为主机设计的DirectX API,如今微软也将把这一技术带到PC上。
在当前NVMe SSD和PCIe技术的演进下,存储带宽远超旧式的硬盘存储技术,过去10MB每秒的速度已经达到数GB每秒。但PC上的图形工作量也在逐步进化,数据量的增加对于读取提出了更高的要求。过去大量数据的读取只需要少量的IO请求,但如今的图形渲染会将材质等资源分成小块,只有在场景提出要求时载入所需的部分,如此一来虽然提高了效率,却引入了更多IO请求。
当前的GPU资源读取流程 / 微软
而目前的存储API并没有对大量IO请求作出优化,因此拖累了NVMe,使得读写瓶颈愈发明显。即便采用高端的PC硬件,也无法饱和利用存储带宽优势。除此之外,这些数据往往需要经过压缩传输下一个环节,传入内存后,还要CPU进行一部分解压工作,最后再传入GPU显存里,这样一来每个节点都存在效率损失。
而DirectStorage采用了全新的路径,从存储读取的数据传给内存后,直接传给GPU显存。而GPU对于这些数据的解压速度远快于CPU,所以极大地优化了IO性能。
英伟达:RTX IO和Magnum IO GPUDirect Storage
英伟达在RTX 30系列显卡上引入了RTX IO,面向消费市场,提升游戏场景下的读取速度。英伟达称RTX IO将与微软的DirectStorage结合,与传统硬盘下的存储API相比,可将IO性能提高百倍。过去需要数十个CPU内核的工作全部交由RTX GPU来处理。
值得一提的是,英伟达的RTX IO虽然也用到了微软的DirectStorage,但该技术并没有将数据传输到内存,而是直接由SSD转向GPU。微软一名图形开发者在GSL 2021大会上表示,未来DirectStorage的目标也是绕过系统内存。
GDS技术 / 英伟达
除了消费市场外,英伟达在HPC市场也推出了对应的直接存储技术,Magnum IO GPUDirect Storage(GDS)。GDS技术同样是一个绕过CPU的技术,与消费级GPU不同,HPC场景下往往要用到多块GPU,如此一来受IO延迟和CPU的影响更大。GDS在本地存储与GPU显存之间建立直接的数据通道,消除了CPU引入的延迟和读写瓶颈。
GDS与CPU传输至GPU读取性能对比 / 英伟达
在运用GDS后,带宽提升达到1.5倍,与传统CPU回弹缓冲的数据路径相比,CPU利用率也有2.8倍的提升。
目前英伟达已经将这一技术加入到其HGX AI超算中,DDN、VAST和WEKA三家公司已经开始了相关产品的量产,而IBM、美光等五家厂商也在积极引入这一技术。三星、铠侠、西数和戴尔等厂商也开始了GDS的早期集成与认证计划。
小结
直接存储技术进一步放大了GPU厂商与存储厂商的优势,目前HPC市场前景巨大,英伟达在相关业务上的盈利已经让其看到了商机。不仅是GPU,英伟达采用Arm架构的Grace CPU同样引入了NVLink这样的数据传输改善方案。在这样的性能改善下,即便存储方案不同,英伟达的GPU也很可能成为HPC应用的首选。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
微软
+关注
关注
4文章
6232浏览量
103075 -
gpu
+关注
关注
27文章
4410浏览量
126635 -
HPC
+关注
关注
0文章
279浏览量
23418 -
英伟达
+关注
关注
22文章
3316浏览量
87714
发布评论请先 登录
相关推荐
CXL技术:全面升级数据中心架构
作为全球最大数据产生国之一,随着数据规模的成倍增长,中国对更高性能数据中心的需求日益迫切。根据IDC Global DataSphere对每年数据产生量的预测,全球数据量的复合年增长率(CAGR
发表于 04-17 16:32
•71次阅读
英飞凌推出高密度功率模块,为AI数据中心提供基准性能,降低总体拥有成本
【 2024 年 3 月 1 日, 德国慕尼黑和加利福尼亚州长滩 讯】 人工智能(AI)正推动全球数据生成量成倍增长,促使支持这一数据增长的芯片对能源的需求日益增加。英飞凌科技股份公司近日推出
发表于 03-05 13:52
•599次阅读

鸿蒙这么大声势,为何迟迟看不见岗位?最新数据来了
对鸿蒙下一阶段的发展更具信心。
鸿蒙人才供需
报告中的数据显示,春节后第一周,鸿蒙相关职位数同比增长163%,投递人数同比增长349%,即分别增至去年同期的2.6倍、4.5倍,涨势突出。
这背后是自去年
发表于 02-29 20:53
南芯科技:逆势增长,模拟芯片市场逐步回暖
具体表现为,南芯科技在2023年第一季度至第三季度的营收均呈现环比增长态势,分别达到11.78%、31.19%和45.52%;归母净利润方面亦表现优异,连续两季度实现环比增长,增幅分别
华为P70系列广角摄像头升级,出货量预计增长100%至120%
早前郭明錤预测过,华为将于2024年上半年发布全新品牌P70系列,其中包含P70、P70 Pro与P70 Pro Art三款产品。同时,负责供应高品质镜头的大立光与舜宇光学厂商(前者占比较大)将会在该系列手机销售淡季间受益匪浅,因为出货量将成倍增长。
电压倍增器电路原理图
这是一个电压倍增电路。该电路采用倍增器原理来倍增电压。该电路具有一些优点,例如低电流供应、光电倍增管和阴极射线管所需的有吸引力的高电压。除此之外,该电路价格便宜。
后摩尔时代,3D封装成为重要发展方向
半导体集成电路代表科技发展的前沿,是信息化、数字化、智能化和算力的基石,随着芯片产业的迅速发展,芯片间数据交换也在成倍增长,传统的芯片封装方式已经不能满足巨大的数据量处理需求。
发表于 12-01 11:16
•287次阅读

2024年存储市场向上,国产模组厂商蓄势待发
预判。 存储市场怎样走? 对于内存市场,集邦咨询资深研究副总经理吴雅婷女士指出,回首2023年,因需求不断的衰退,且未见好转的迹象,存储器上下游都面临库存去化的压力。全球通货膨胀、国际冲突仍持续蔓延,使得市场需求能见度低
Banana Pi为何选择rk3588开发与Jetson Nano引脚兼容的嵌入式产品
功能和更大灵活性的需求也不断增长。因此,我们的公司决定采用RK3588芯片来开发一款全新的产品,以实现与Jetson Nano引脚的兼容性,同时提供更多性能和功能。
为何选择RK3588:
卓越的
发表于 11-02 12:30
重磅上线:《2023固态电池行业研究报告》
我国固态电池行业仍然处于发展初期的阶段,整体市场正在快速发展。据公开数据显示,2021年末,中国固态电池市场出货量达1.5GWh左右,到2022年,固态电池市场出货总量进一步上升至3GWh,比上年同期实现了成倍增长

Mali GPU性能分析工具
本文档描述了马里GPU性能分析工具2.2版中的已知勘误表。
这是一个贯穿整个产品生命周期的工作文档,因此,随着新信息的发现,其内容可能会被修改。
本文中包含的信息是ARM有限公司的财产,对错误或遗漏
发表于 09-05 07:08
PyTorch IO DataPipes可用性、性能和功能
数据,并将数据输入GPU,用于高输送量和低潜伏度的培训模式。 我们在此为皮托尔奇推出新的S3 IO DataPipes(S3 IO DataPipes),s3 文件列表器和s3 文件加载器为了提高记忆
现代异步存储访问API探索:libaio、io_uring和SPDK
最近的高性能存储设备暴露了现有软件栈的低效,因而催生了对I/O栈的改进。Linux内核的最新API是io_uring。作者提供了第一个针对io_uring的深度研究,并且和libaio

登顶!华为OceanStor Pacific存储达成IO500榜单全球第一
日前,国际最权威的存储性能排行榜—— IO500 最新榜单正式公布,以 华为 OceanStor Pacific 分布式存储 为核心底座的 Cheeloo-1 系统,以超越了历史最佳纪





 工商网监
工商网监
评论