 Linux下最常用命令之一copy引发的思考
Linux下最常用命令之一copy引发的思考
cp 引发的思考
cp 是啥 ? 是的,就是 Linux 是 Linux 下最常用的命令之一,copy 的简写,小伙伴 100% 都用过。
cp 命令处于 Coreutils 库里,是 GNU 项目维护的一个核心项目,提供 Linux 上核心的命令。
今天用 cp 命令,把小伙伴惊到了,引发了我对其中细节的思考。
背景是这样的,奇伢今天用 cp 拷贝了一个 100 GiB 的文件,竟然一秒不到就拷贝完成了。一个 SATA 机械盘的写能力能到 150 MiB/s (大部分的机械盘都是到不了这个值的)就算非常不错了,所以,正常情况下,copy 一个 100G 的文件至少要 682 秒 ( 100 GiB/ 150 MiB/s ),也就是 11 分钟。
sh-4.4# time cp 。/test.txt 。/test.txt.cp
real 0m0.107s
user 0m0.008s
sys 0m0.085s
上面是我们理论分析,最少要 11 分钟,实际情况却是我们 cp 一秒没到就完成了工作,惊呆了,为啥呢?并且还有一个更诡异的我文件系统大小才 40 GiB,为啥里面会有一个 100 G的文件呢?
分析文件
我们先用 ls 看一把文件,显示文件确实是 100 GiB.
sh-4.4# ls -lh
-rw-r--r-- 1 root root 100G Mar 6 12:22 test.txt
但是再用 du 命令看却只有 2M ,这是怎么回事?(且所在的文件系统总空间都没 100G 这么大)
sh-4.4# du -sh 。/test.txt
2.0M 。/test.txt
再看 stat 命令显示的信息:
sh-4.4# stat 。/test.txt
File: 。/test.txt
Size: 107374182400 Blocks: 4096 IO Block: 4096 regular file
Device: 78h/120d Inode: 3148347 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-03-13 1200.888871000 +0000
Modify: 2021-03-13 1246.562243000 +0000
Change: 2021-03-13 1246.562243000 +0000
Birth: -
stat 命令输出解释:
Size 为 107374182400(知识点:单位是字节),也就是 100G ;
Blocks 这个指标显示为 4096(知识点:一个 Block 的单位固定是 512 字节,也就是一个扇区的大小),这里表示为 2M;
划重点:
Size 表示的是文件大小,这个也是大多数人看到的大小;
Blocks 表示的是物理实际占用空间;
所以,注意到一个新概念,文件大小和实际物理占用,这两个竟然不是相同的概念。为什么会这样?
这里先梳理下文件系统的基础知识,文件系统究竟是怎么存储文件的?(以 Linux 上 ext系列的文件系统举例)
文件系统
文件系统听起来很高大上,通俗话就用来存数据的一个容器而已,本质和你的行李箱、仓库没有啥区别。只不过文件系统存储的是数字产品而已。我有一个视频文件,我把这个视频放到这个文件系统里,下次来拿,要能拿到我完整的视频文件数据,这就是文件系统,对外提供的就是存取服务。
现实的存取场景
就跟你在火车站使用的寄存服务一样,包裹我能存进去,稍后我能取出来,就可以了。问题来了,存进去?怎么取?仔细回忆下存储行李的场景。
存行李的时候,是不是要登记一些个人信息?对吧,至少自己名字要写上。可能还会给你一个牌子,让你挂手上,这个东西就是为了标示每一个唯一的行李。
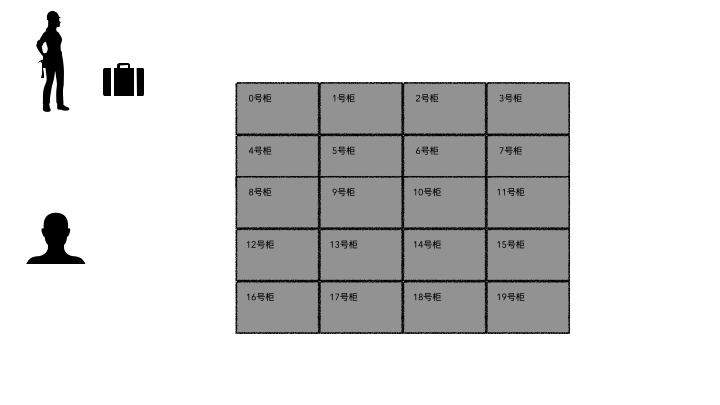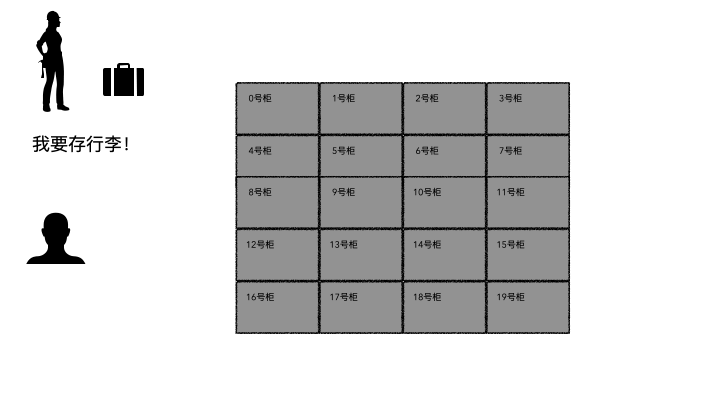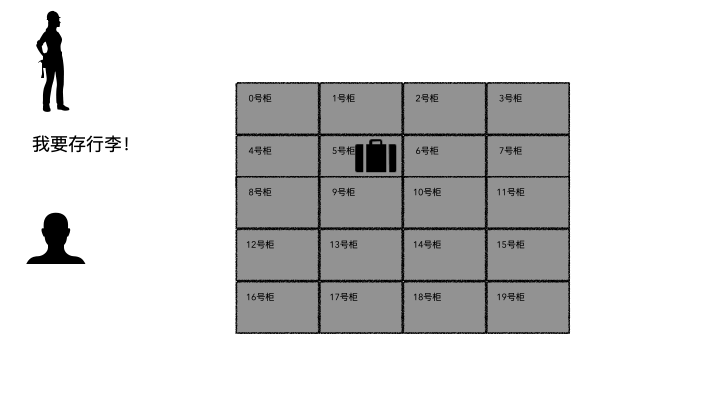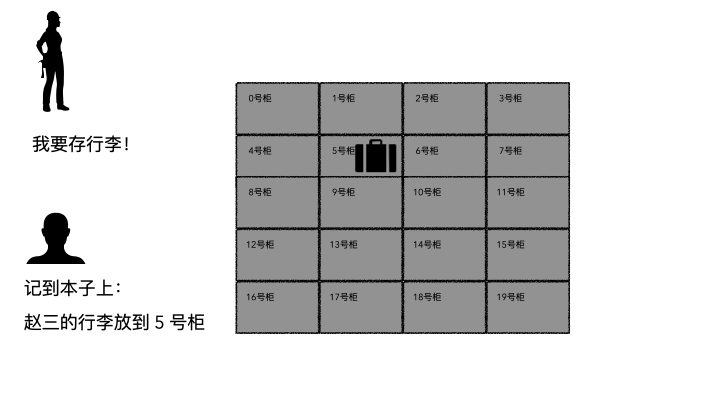
取行李的时候,要报自己名字,有牌子的给他牌子,然后工作人员才能去特定的位置找到你的行李(不然机场那么多人,行李都长差不多,他肯定不知道你的行李是哪个)。
划重点:存的时候必须记录一些关键信息(记录ID、给身份牌),取的时候才能正确定位到。
文件系统
回到我们的文件系统,对比上面的行李存取行为,可以做个简单的类比;
登记名字就是在文件系统记录文件名;
生成的牌子就是元数据索引;
你的行李就是文件;
寄存室就是磁盘(容纳东西的物理空间);
管理员整套运行机制就是文件系统;
上面的对应并不是非常严谨,仅仅是帮助大家理解文件系统而已,让大家知道其实文件系统是非常朴实的一个东西,思想都来源于生活。
划重点:文件系统的存储介质是磁盘,文件系统是软件层面的,是管理员,管理怎么使用磁盘空间的软件系统而已。
空间管理
现在思考文件系统是怎么管理空间的?
如果,一个连续的大磁盘空间给你使用,你会怎么使用这段空间呢?
直观的一个想法,我把进来的数据就完整的放进去。

这种方式非常容易实现,属于眼前最简单,以后最麻烦的方式。因为会造成很多空洞,明明还有很多空间位置,但是由于整个太大,形状不合适(数据大小),哪里都放不下。因为你要放一个完整的空间。
这种不能利用的空间我们称之为碎片,准确的说是外部碎片,这种碎片在内存池分配内存的时候最常见,产生的原理是一样的。
怎么改进?有人会想,既然整个放不进去,那就剁碎了呗。这里塞一点,那里塞一点,就塞进去了。
对,思路完全正确。改进的方式就是切分,把空间按照一定粒度切分。每个小粒度的物理块命名为 Block,每个 Block 一般是 4K 大小,用户数据存到文件系统里来自然也是要切分,存储到每一个 Block 。Block 粒度越小则外部碎片则会越少(注意:元数据量会越大),可以尽可能的利用到空间,并且完整的用户数据文件存储到磁盘上则不再连续,而是切成一个个 Block 大小的数据块存到磁盘的各个角落上。
图示标号表示这个完整对象的 Block 的序号,用来复原对象用的。
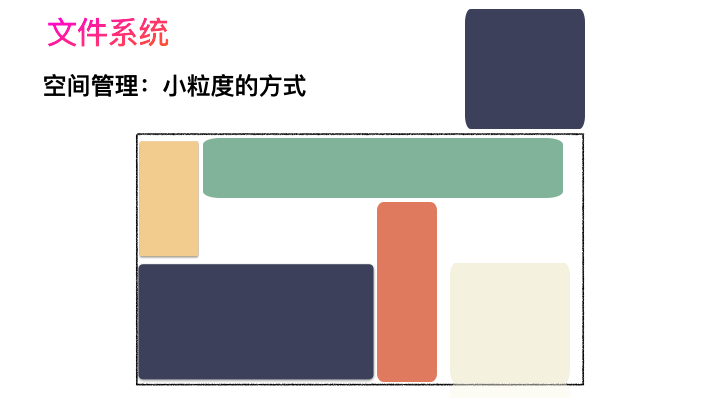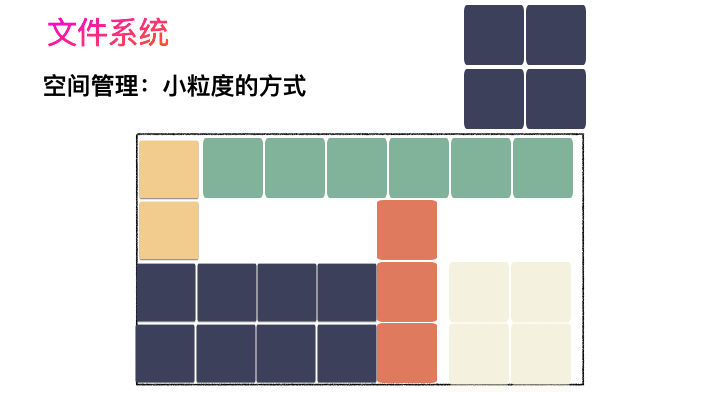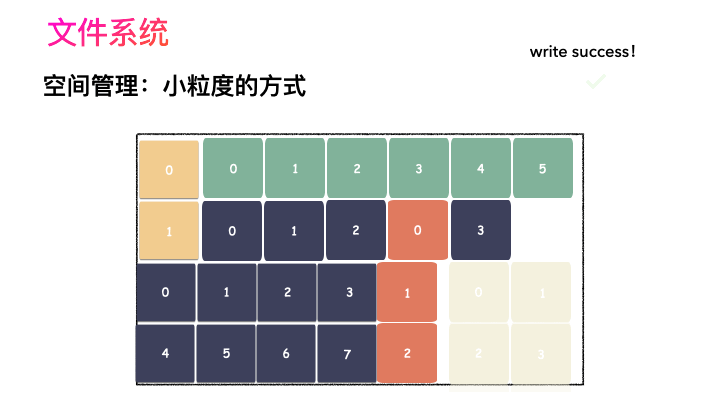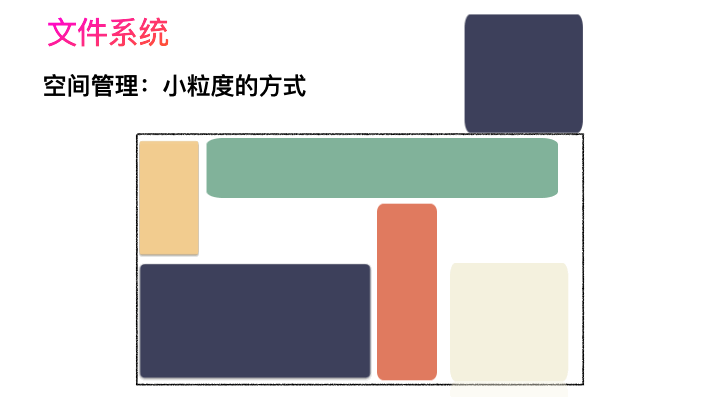
随之而来又有一个问题:你光会切成块还不行,取文件数据的时候,要给完整的用户数据出去,用户不管你内部怎么实现,他只想要的是最初的样子。所以,要有一个表记录该文件对应所有 Block 的位置,要把每一个 Block 的位置记录好,取文件的时候,对照这表恢复出一个完整的块给到用户。
所以,写流程再完善一下就是这样子:
先写数据:数据先按照 Block 粒度存储到磁盘的各个位置;
再写元数据:然后把 Block 所在的各个位置保存起来,这也就是元数据,文件系统里叫做 inode(我用一本书来表示);

文件读流程则是:
先读元数据,找到各个 Block 的位置;
然后读数据,构造一个完整的文件,给到用户;
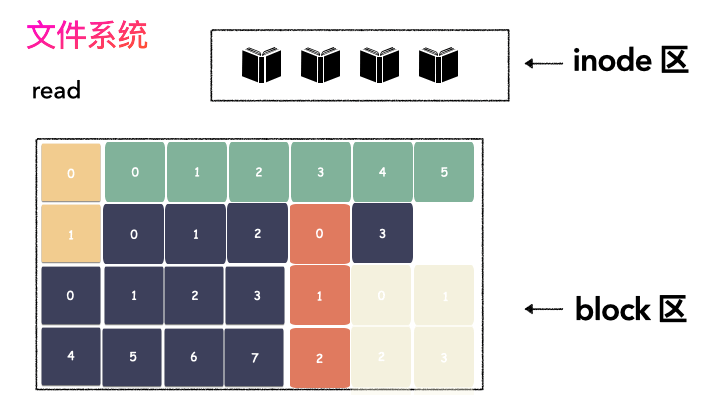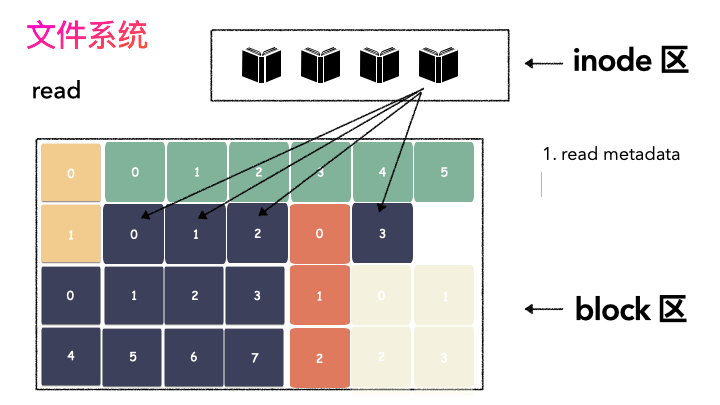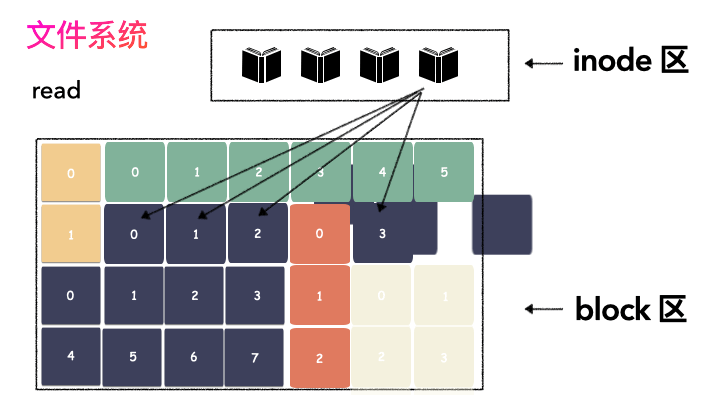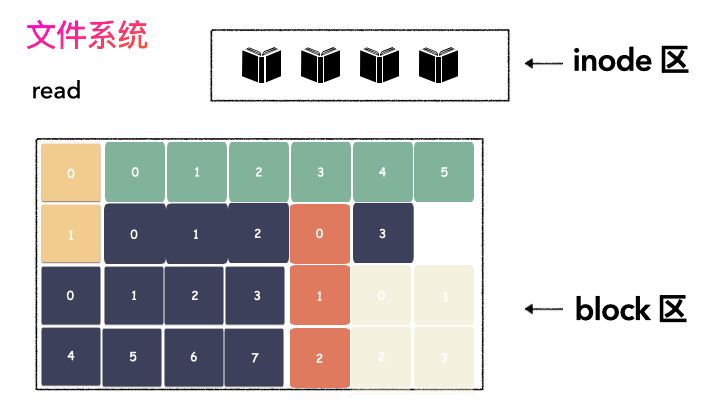
inode/block 概念
好,现在我们引出了两个概念:
磁盘空间是按照 Block 粒度来划分空间的,存储数据的区域全都是 Block,我们叫做数据区域;
文件存储不再连续存储在磁盘上,所以需要记录元数据,这个我们叫做 inode;
文件系统中,一个 inode 唯一对应一个文件,inode 的个数则是在文件系统格式化的时候就确定好了的,换言之,一个 local 文件系统支持的文件数是天然就有上限的。
block 固定大小,每个 4k(大部分文件系统都是,这里不做纠结),block 意图存储打散的用户数据。
无论是 inode 区,还是 block 区,本质上都是在线性的磁盘空间上。文件系统的空间层次如下:

一个文件的对应一个 inode,这个文件需要按照 Block 切分存储在磁盘上,存储的位置则由 inode 记录起来,通过 inode 则能找到 block,也就获取到用户数据。
现在有一个新的小问题,inode 区和 block 区都是在初始化就构造好的。存储一个文件的时候,需要取一个空闲的 inode,然后把数据切分成 4k 大小存储到空闲的 block 上,对吧?
划重点:空闲的inode,空闲的 block。 这个很关键,已经存储了数据的地方不能再让写,不然会把别人的数据覆盖掉。
那么,怎么区分空闲和已经在用的 inode ,block 呢?
答案是 :inode 区和 block 区分别需要另一张表,用来表示 inode 是否在用,block 是否在用,这个表的名字我们叫做 bitmap 表。bitmap 是一个 bit 数组,用 0 表示空闲,1 表示在用,如下:
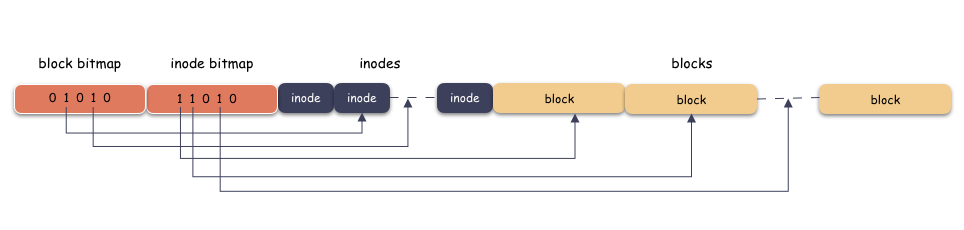
bitmap 什么时候用呢?自然是写的时候,也就是分配 inode 或者 block 的时候,因为只有分配的时候,你才需要找空闲的空间。
上图我为了突出本质思想,类似于超级块,块描述符都省略了,这个感兴趣可以自己扩展,这里只突出主干哈。
小结一下:
bitmap 本质是个 bit 数组,占用空间极其少,用 0 来表示空闲,1 表示在用。使用时机是在创建文件,或者写数据的时候;
inode 则对应一个文件,里面存储的是元数据,主要是数据 block 的位置信息;
block 里面存储的是用户数据,用户数据按照 block 大小(4k)切分,离散的分布在磁盘上。读的时候只有依赖于 inode 里面记录的位置才能恢复出完整的文件;
inode 和 block 的总个数在文件系统格式化的时候就确定了,所以文件数和文件大小都是有上限的;
一个文件真实的模样
上面是抽象的样子,现在我们看一个真实的 inode -》 block 的样子。一个文件除了数据需要存储之外,一些元信心也需要存储,例如文件类型,权限,文件大小,创建/修改/访问时间等,这些信息存在 inode 中,每个文件唯一对应一个inode 。
看一下 inode 的数据结构(就以 linxu ext2 为例,该结构定义在 linux/fs/ext2/ext2.h 头文件中 ):
struct ext2_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Creation time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks; /* Blocks count */
__le32 i_flags; /* File flags */
__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
__le32 i_file_acl; /* File ACL */
__le32 i_dir_acl; /* Directory ACL */
__le32 i_faddr; /* Fragment address */
};
重点:
上面的结构 mode,uid,size,time 等信息就是我们常说的文件类型,大小,创建修改等时间元数据;
注意到 i_block[EXT2_N_BLOCKS] 这个字段,这个字段将会带你找到数据, 因为里面存储的就是 block 所在的位置,也就是 block 的编号;
再来,理解下什么叫做 block 的位置(编号)。

位置就是编号,记录位置就是记录编号,编号就是索引。
我们看到有一个数组:i_block[EXT2_N_BLOCKS],这个数组是存储 block 位置的数组。其中 EXT2_N_BLOCKS 是一个宏定义,值为 15 。也就是说,i_block 是一个 15 个元素的数组,每个元素是 4 字节(32 bit)大小。
举个例子,假设我们现在有一个 6k 的文件,那么只需要 2 个 block 就可以存下了,假设现在数据就存储在编号为 3 和 101 这两个 block 上,那么如下图:
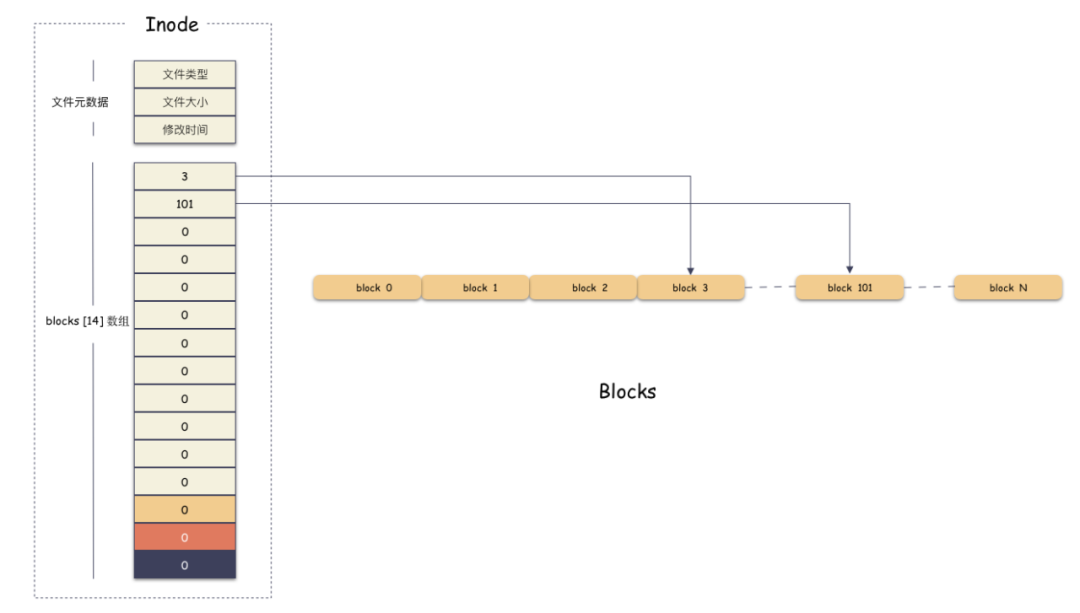
i_block[15] 第一个元素存的是 3,第二个存储的是 101,其他槽位没用用到,由于 inode 的内存是置零分配的,所以里面的值为 0,表示没有在使用 。 我们通过 [3, 101] 这两个 block 就能拼装出完整的用户数据了。用户的 6k 文件组成如下:
第一个 4k 数据在 [3*4K, 4*4K] 范围;
第二个 2k 数据在 [ 101*4K, 101*4K+2K] 范围;
好,现在我们知道了每个定长 block 都有唯一编号,我们的 i_block[15] 数组 通过有序存储这个编号找到文件数据所在的位置,并且拼装出完整文件。
思考问题:区分文件的切分成 4k 块的编号和 磁盘上物理 4k 块的编号的区别。
举个栗子,一个文件 12K 的大小,那么按照 4K 切分会存储到 3 个 物理 block 上。
文件第 0 个 4k 存储到了 101 这个物理 block 上;文件第 1 个 4k 存储到了 30 这个物理 block 上;文件第 2 个 4k 存储到了 11 这个物理 block 上;
文件逻辑空间上的编号是从 0 开始,到 2 结束,对应存储的物理块编号分别是 101,30,11 。
思考问题:这么一个 inode 结构能够表示多大的文件?
我们看到 inode-》i_block[15] 是一个一维数组,里面能存 15 个元素。也就是能存 15 个 block 的编号,那么如果直接存储文件的 block 编号最大能表示 60K (15*4K) 的文件。换句话说,如果我拿着 15 个槽位全部用来存储文件的编号,这个文件系统支撑的最大文件却就是 60K。惊呆了?(注意:ext2 文件系统是可以创建 4T 以内的文件的!!)
那我们自然会思考,怎么解决呢?怎么才能支撑更大的文件?
最直接思考就是用更大的数组,把 inode-》i_block 数组变得更大。比如,如果你想要支持 100G 的文件:
那么,需要 i_block 数组大小为 26214400 (计算公式:100*1024*1024/4),也就是要分配一个 i_block[26214400] 的数组。
每个编号占用 4 字节,这个数组就占用 100M 的空间(计算公式:(26214400*4)/1024/1024)。100M !这里就有点夸张了,注意到 i_block 只是一个 inode 内部的字段,是一个静态分配的数组,也就是说,这个文件系统为了支持最大 100G 的文件存入,每一个 inode 都要占用 100M 的内存,就算你是一个 1K 的文件,inode 也会占用这么大的内存空间。并且,这种方案扩展性差,支持的文件 size 越大,i_block[N] 消耗内存情况越严重。这是无法接受的。
思考问题:怎么才能让你既能表示更大的文件,又能不浪费占用空间?
我们仔细分析这个问题,你会发现,这里有 2 个核心问题:
第一点,核心在于浪费内存空间(关键点是要保证 inode 内存结构的稳定,无论文件怎么变,inode 结构本身不能变);
第二点,仔细思考你会发现,无论是什么神仙方案,如果你要存储一个按照 4k 切分的 100G 文件,都是需要 100M 的空间来存储索引( block 编号),但是 99.99% 的文件可能都没有这么大;
我们前面用一个大数组来一把存储 block 编号的方案固然简单,但是问题在于太过死板。核心问题在于存储 block 编号的数组是预分配的,为了还没有发生并且 99% 场景都不会发生的事情(文件大小达到 100G),却不管三七二十一,提前准备好了完整的 block 索引数组,预分配就是浪费的根源。
那么知道了这两个问题,下一步分析下一个个解决:
索引存磁盘
问题一的解决:索引存磁盘:
既然问题在于浪费内存,inode 内存分配不灵活,那就可以看把 inode-》i_block 下放到磁盘。
为什么?
因为磁盘的空间比内存大了不止一个量级。100M 对内存来说很大,对磁盘来说很小。换句话说,用把用户数据所在的 block 编号存到磁盘上去,这个也需要物理空间,使用的也是 block 来存储,只不过这种 block 存储的是 block 编号信息,而不是用户数据。
那么我们怎么通过 inode 找到用户数据呢?
因为这个 block 本身也有编号,我们则需要把这个存储用户 block 编号的 block 所在块的编号存储在 inode-》i_block[15] 里,当读数据的时候,我们需要先找到这个存储编号的 block,然后再通过里面存储的用户数据所在的 block 编号找到用户所在的 block ,去读数据。
这个存储用户 block 编号的 block 所在块的编号我们叫做间接索引,然后我们根据跳转的次数可以分类成一级索引,二级索引,三级索引。顾名思义,一级索引就是跳转 1 次就能定位到用户数据,二级索引就是跳转 2 次,三级索引就是跳转 3 次才能定位到用户数据。那么 inode-》i_block[15] 里面存储的可以直接定位到用户数据的 block 就是直接索引。
终于可以说回 ext2 的使用了,ext2 的 inode-》i_block[15] 数组。知识点来了,按照约定,这 15 个槽位分作 4 个不同类别来用:
前 12 个槽位(也就是 0 - 11 )我们成为直接索引;
第 13 个位置,我们称为 1 级索引;
第 14 个位置,我们称为 2 级索引;
第 15 个位置,我们称为 3 级索引;

好,那我们在来看下直接索引,一级,二级,三级索引的表现力。
直接索引:能存 12 个 block 编号,每个 block 4K,就是 48K,也就是说,48K 以内的文件,只需要用到 inode-》i_block[15] 前 12 个槽位存储编号就能完全 hold 住。
一级索引:
inode-》i_block[12] 这个位置存储的是一个一级索引,也就是说这里存储的编号指向的 block 里面存储的也是 block 编号,里面的编号指向用户数据。一个 block 4K,每个元素 4 字节,也就是有 1024 个编号位置可以存储。
所以,一级索引能寻址 4M(1024 * 4K)空间 。
二级索引:
二级索引是在一级索引的基础上多了一级而已,换算下来,有了 4M 的空间用来存储用户数据的编号。所以二级索引能寻址 4G (4M/4 * 4K) 的空间。
三级索引:
三级索引是在二级索引的基础上又多了一级,也就是说,有了 4G 的空间来存储用户数据的 block 编号。所以二级索引能寻址 4T (4G/4 * 4K) 的空间。
最后,看一眼完整的表示图:
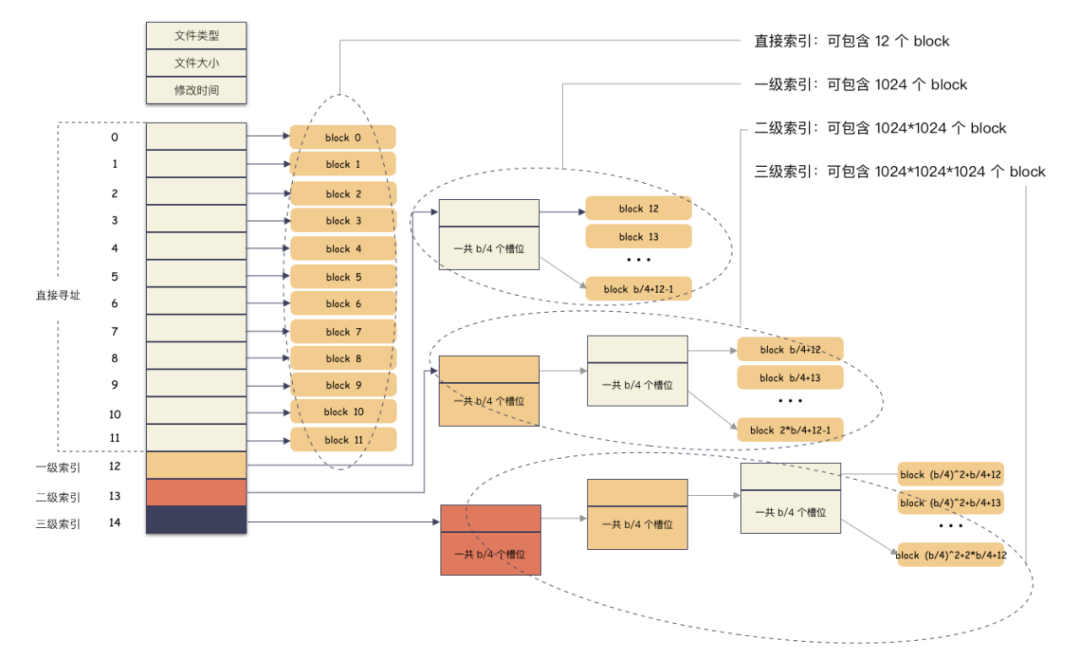
所以,在我们 ext2 的文件系统上,通过这种间接块索引的方式,最大能支撑的文件大小 = 48K + 4M + 4G + 4T ,约等于 4 T。文件系统最大支撑 16T 空间,因为 4 Byte 的整形最大数就是 2^32=4294967296 , 乘以 4K 就等于 16 T。
ext2 文件系统支持的最大单文件大小和文件系统最大容量就是这么算出来的(温馨提示:ext4 文件系统不仅兼容间接块的实现,还使用的是 extent 模式来管理的空间,最大支持单文件 16 TB ,文件系统最大 1 EB)。
思考:这种多级索引寻址性能表现怎么样?
在不超过 12 个数据块的小文件的寻址是最快的,访问文件中的任意数据理论只需要两次读盘,一次读 inode,一次读数据块。访问大文件中的数据则需要最多五次读盘操作:inode、一级间接寻址块、二级间接寻址块、三级间接寻址块、数据块。
多级索引和后分配
问题二解决:多级索引和后分配
一级索引不够,表现力太差,预留空间又太浪费,不预留空间又无法扩展,怎么解决?
既然问题在于预分配,我们使用后分配(瘦分配,或精简分配)解决。也就是说用户文件数据有多大,我才分配出多大的数组。举个例子,我们存储 100 G 的文件,那么就要用到三级索引块,最多分配 26214400 个槽位的数组(因为要 26214400 个 block)。如果是存储 6K 的文件,那么只需要 2 个槽位的数组。
索引数组的后分配
后分配这里说的是 block 索引编号数组的后分配,需要用到的时候才分配,而不是说,现在用户存储一个 1k 的文件,我上来就给他分配一个 100M 的索引数组,只是为了以后这个文件可能增长到 100 G。
数据的后分配
既然这里说到,关于后分配还有一个层面,就是数据所占的空间也是用到了才分配,这个也就是涉及到今天 cp的秘密的核心问题。
实际的栗子
先看下下正常的文件写入要做的事情(注意这里只描述主干,实际流程可能,有优化):
创建一个文件,这个时候分配一个 inode;
在 [ 0,4K ] 的位置写入 4K 数据,这个时候只需要 一个 block 假设编号 102,把这个编号写到 inode-》i_block[0] 这个位置保存起来;
在 [ 1T,1T+4K ] 的位置写入 4K 数据,这个时候需要分配一个 block 假设编号 7,因为这个位置已经落到三级索引才能表现的空间了,所以需要还需要分配出 3 个索引块;
写入完成,close 文件;
这里解释下文件偏移位置 [1T, 1T+4K] 为什么落到三级索引。
offset 为 1T,按照 4K 切分,也就是 block 268435456 块(注意这个是虚拟文件块,不是物理位置);
先算出范围:直接索引的范围是 [0, 11] 个,一级索引 [12, 1035],二级索引 [1036, 1049611], 三级索引 [1049612, 1074791435],(有人如果不知道怎么来的话,可以往前看看 inode 的结构,直接索引 12个,一级索引 1024 个,二级 1M 个,三级 1G 个,然后算出来的);
268435456 落在三级索引 [1049612, 1074791435] 这个范围;
实际存储如图:
计算索引:
12 + 1024 + 1024 * 1024 + 1024 * 1024 * 254 + 1024 * 1022 + 1012 = 268435456
实际的物理分配如图:
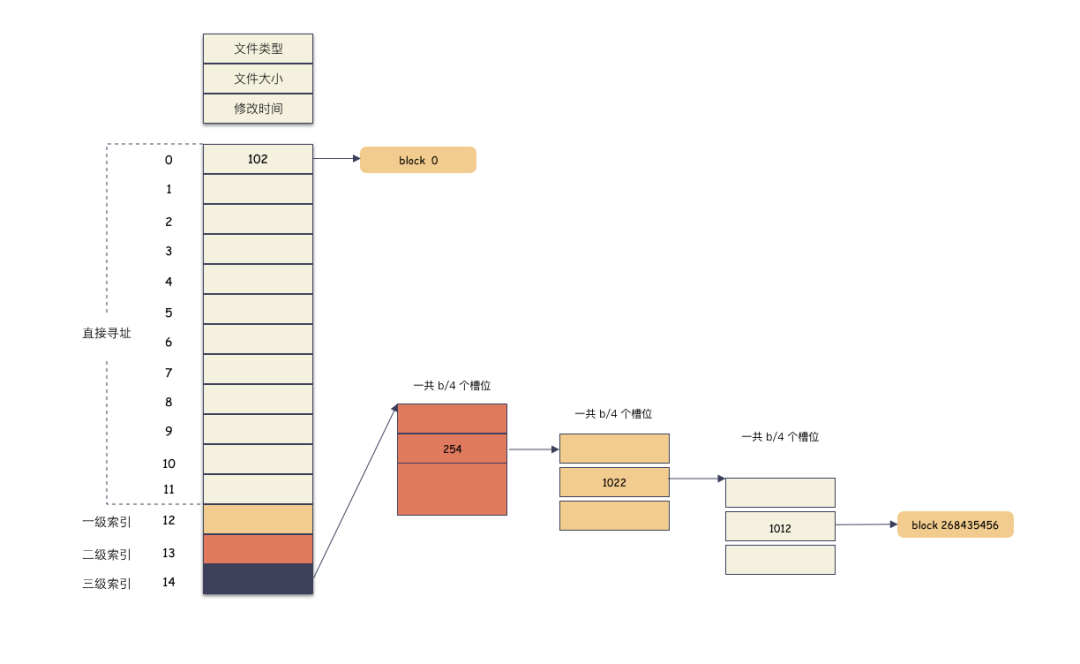
因为偏移已经用到了 3 级索引,所以除了用户数据的两个 block ,中间还需要 3 个间接索引 block 分配出来。
如果要读 [1T, 1T+4K] 这个位置的数据怎么办?
流程如下:
计算 offset 得出在第 268435456 的位置;
读出三级索引 inode-》i_block[14] 里存储的 block 编号,找到对应的物理 block,这个是第一级的 block;
然后读该 block 的第 254+1 个槽位里的数据,里面存储的是第二级的 block 编号,把这个编号读出来,通过这个编号找到对应的物理 block;
读该 block 的第 1022 +1 个操作的数据,里面存储的是第三级的 block 编号,通过这个编号可以找到物理 block 的数据,里面存储的是用户数据所在 block 的编号;
读该 block 第 1012+1 个槽位里存储的编号,找到物理 block,这个 block 里存的就是用户数据了;
这个时候,我们的文件看起来是超大文件,size 等于 1T+4K ,但里面实际的数据只有 8 K,位置分别是 [ 0,4K ] ,[ 1T,1T+4K ]。
重点:文件 size 只是 inode 里面的一个属性,实际物理空间占用则是要看用户数据放了多少个 block 。
划重点:没写数据的地方不用分配物理 block 块。
没写数据不分配物理块?那是什么?那就是我们下面要说的稀疏文件。
文件的稀疏语义
什么是稀疏文件
终于到我们文件的稀疏语义了,稀疏语义什么意思?
稀疏文件英文名 sparse file 。稀疏文件本质上就是计算机文件,用户不感知,文件系统支持稀疏文件只是为了更有效率的使用磁盘空间而已。稀疏文件就是后分配空间的一种实现形式,做到真正用时才分配,最大效率的利用磁盘空间。
就以上面举的栗子,文件大小 1T,但是实际数据只有 8K,这种就是稀疏文件,逻辑大小和实际物理空间是可以不等的。文件大小只是一个属性,文件只是数据的容器,没有用户数据的位置可以不分配空间。
为什么要支持稀疏语义?
还是以上面 1T 的文件举例,如果这 1T 的文件只有首尾分别写了 4K 的数据,而文件系统却要分配 1T 的物理空间,这里将带来巨大的浪费。何不等存了用户数据的时候再分配了,实际数据有多少,才去分配多大的 block ,何必着急的预分配呢?
后分配本着用多少给多少的原则,尽量有效的利用空间。
后分配还有一个优点,这也减少了首次写入的时间,怎么理解?
因为,如果文件大小 1T,就要分配 1T 的空间,那么初始分配需要写入全零到空间,否则上面的数据可能是随机数。
对于稀疏文件空洞的地方,不占用物理空间,但要保证读的时候返回全 0 数据的语义,即可。
又一个知识点:有时候稀疏文件的空洞和用户真正的全 0 数据是无法区分的,因为对外表现是一样的。
稀疏文件也要文件系统支持,并不是所有的文件系统都支持稀疏语义,比如 ext2 就没有,ext4 才有稀疏语义,支持的标志是实现文件系统的 fallocate 接口。
怎么创建一个稀疏文件?
可以使用 truncate 命令在一个 ext4 的文件系统创建一个文件。
truncate -s 100G test.txt
你 ls -lh 。/test.txt 命令看会发现是一个 100 G 的文件;
但是 du -sh 。/test.txt 会发现是一个 0 字节的文件;
stat 。/test.txt 会发现是 Size: 107374182400 Blocks: 0 的文件;
这就是一个典型的稀疏文件。size 只是文件的逻辑大小,实际的物理空间占用还是得看 Blocks 这个数值。
下面这种 1T 的文件,因为只写了头尾 8K 数据,所以只需要分配 2 个 block 存储用户数据即可。
好,我们再深入思考下,文件系统为什么能做到这个?
这也是为什么理解稀疏语义要先了解文件系统的实现的原因。
首先,最关键的是把磁盘空间切成离散的、定长的 block 来管理;
然后,通过 inode 能查找到所有离散的数据(保存了所有的索引);
最后,实现索引块和数据块空间的后分配;
这三点是层层递进的。
稀疏语义接口
为了知识的完整性,简要介绍稀疏语义的几个接口:
preallocate(预分配):提供接口可以让用户预占用文件内指定范围的物理空间;
punch hole(打洞):提供接口可以让用户释放文件内指定范围的物理空间;
这两个操作刚好相反。
预分配的意思是?
就是说,当你创建一个 1T的文件,如果你没写数据,这个时候其实没有分配物理空间的,支持稀疏语义的文件系统会提供一个 fallocate 接口给你,让你实现预分配,也就是说把这 1T 的物理空间现在就分配出来。
思考:这个有什么好处呢?
第一,如果你命中注定要 1T 的空间,预分配是有好处的,把空间分配的工作量集中在初始化的时候一把做了,避免了实时现场分配的开销;
第二,如果不提前占坑,很有可能等你想要的时候已经没有空间可占用了。所以你把物理空间先占好,就可以安心使用了;
linux 提供了一个 fallocate 命令,可以用来预分配空间。
fallocate -o 0 -l 4096 。/test.txt
这个命令的意思就是给 text.txt 这个文件 [0, 4K] 的位置分配好物理空间。
打洞(punch hole) 是干啥的呢?
这个调用允许你把已经占用的物理空间释放掉,从而达到快速释放的目的。这种操作在虚拟机镜像的场景用得多,通常用于快速释放空间,punch hole 能够让业务更有效的利用空间。
linux 提供了一个 fallocate 命令也可以用来 punch hole 空间。
fallocate -p -o 0 -l 4096 。/test.txt
这个命令的意思是把 test.txt [ 0, 4K ] 的物理空间释放掉。
Go 语言实现
稀疏文件本身和编程语言无具体关系,可以用任何语言实现,我下面以 Go 为例,看下稀疏文件的预分配和打洞(punch hole)是怎么实现的。
预分配实现:
func PreAllocate(f *os.File, sizeInBytes int) error {
// use mode = 1 to keep size
// see FALLOC_FL_KEEP_SIZE
return syscall.Fallocate(int(f.Fd()), 0x0, 0, int64(sizeInBytes))
}
punch hole 实现:
// mode 0 change to size 0x0
// FALLOC_FL_KEEP_SIZE = 0x1
// FALLOC_FL_PUNCH_HOLE = 0x2
func PunchHole(file *os.File, offset int64, size int64) error {
err := syscall.Fallocate(int(file.Fd()), 0x1|0x2, offset, size)
if err == syscall.ENOSYS || err == syscall.EOPNOTSUPP {
return syscall.EPERM
}
return err
}
可以看到,本质上都是系统调用 fallocate ,然后带不同的参数而已。指定文件偏移和长度,就能预分配物理空间或者释放物理空间了。
这里有一个知识点:punch hole 的调用要保证 4k 对齐才能释放空间。
举个例子,比如:
punch hole [0, 6k] 的数据,你会发现只有 [0, 4k] 的数据物理块被释放了,[4k, 6k] 所占的 4k 物理块还占着空间呢。
这个很容易理解,因为磁盘的物理空间是划分成 4k 的 block,这个是最小单位了,不能再分了,你无法切割一个最小的单位。
值得注意的是,就算你没有 4k 对齐的发送调用,fallocate 也不会报错,这个请注意了。
cp 的秘密
铺垫了这么久的基础知识,终于到我们的 cp 命令的解密了。回到最开始的问题,cp 一个 100G 的文件 1 秒都不到,为什么这么快?
说到现在,这个问题就很清晰了,这个 100G 的文件是个稀疏文件,盲猜一手:cp 的时候只拷贝了有效数据,空洞是直接跳过的。 往前看 stat 命令和 ls 命令显示的差距就知道了。
接下来我们具体看一下 cp 的实现。
cp 有一个参数 --sparse 很有意思,sparse 这个参数控制这 cp 命令对稀疏文件的行为,这个参数有三个值可选:
--sparse=always :空间最省;
--sparse=auto :默认值,速度最快;
--sparse=never :吭呲吭呲 copy,最傻;
cp 默认的时候,sparse 是 auto 策略。auto,always,never 分别是什么策略呢?
spare 三大策略
auto 策略
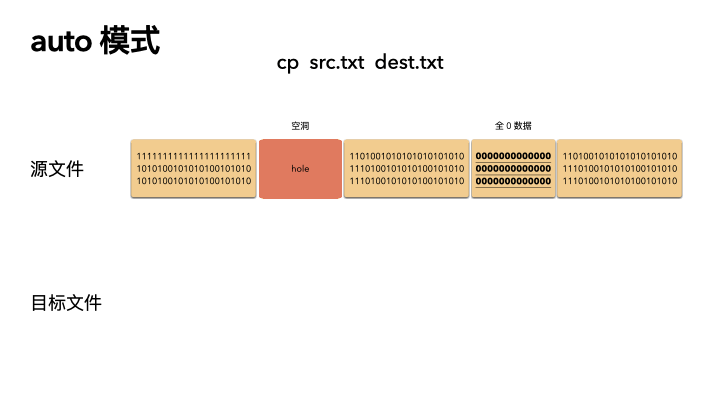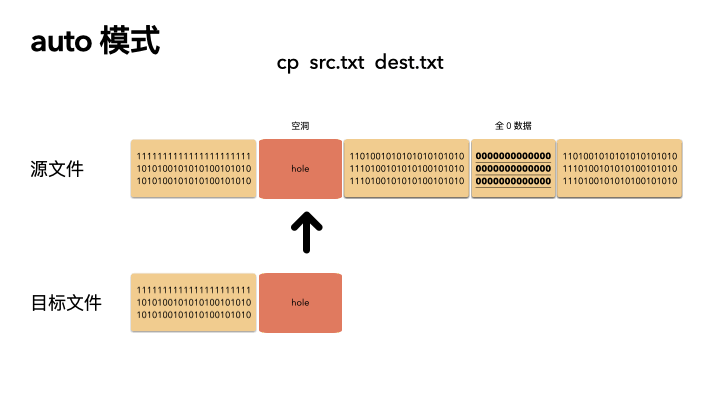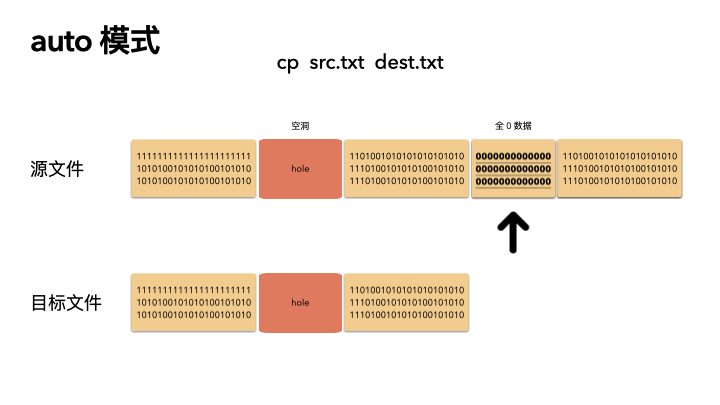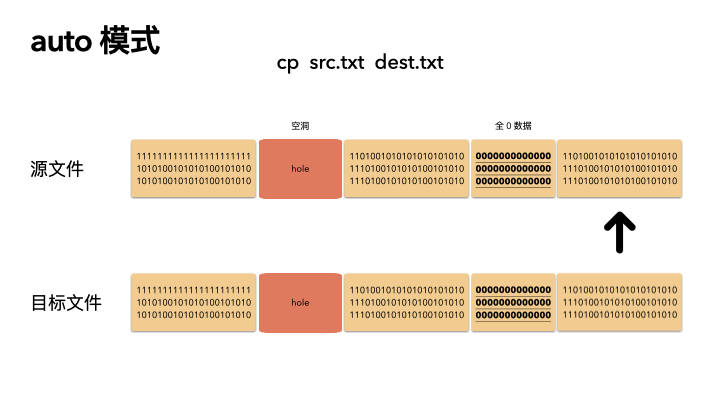
默认的情况下,cp 会检查源文件是否具有稀疏语义,对于不占物理空间的位置,目标文件不会写入数据,从而形成空洞。
所以,对于我们的例子,真实的就只进行了 2M 的 IO ,预期的 100G 文件,只拷贝了 2M 的数据,自然飞快了,自然惊艳所有人。
auto 是默认策略,使用该模式的时候,cp 内部实现是通过系统调用拿到文件的空洞位置情况,然后对这些位置目标文件会保持空洞。
注意,不会对非空洞位置的文件内容做判断,如果用户数据占用了物理块,但是是全 0 数据,这种情况下,auto 模式不会识别,会以全零的数据写入到目标文件。这个是跟 always 最大的区别。
auto 策略下 cp 的文件的文件,size,物理 block 数量都和源文件一致。
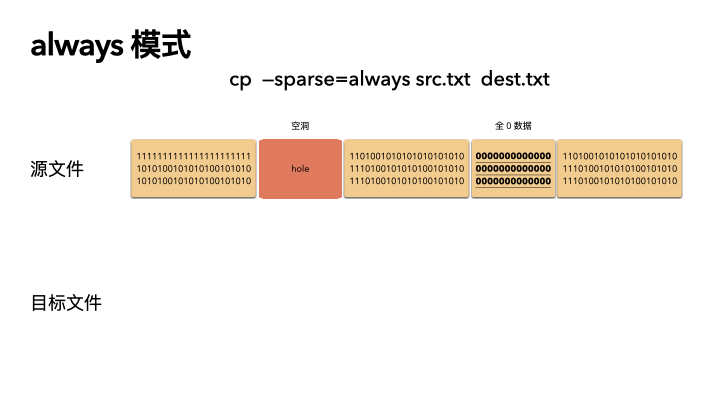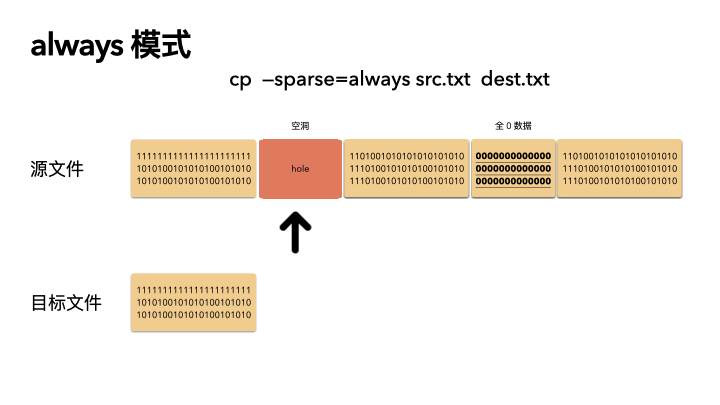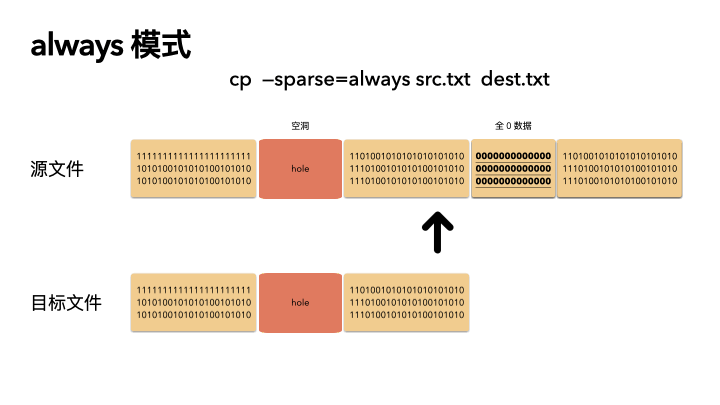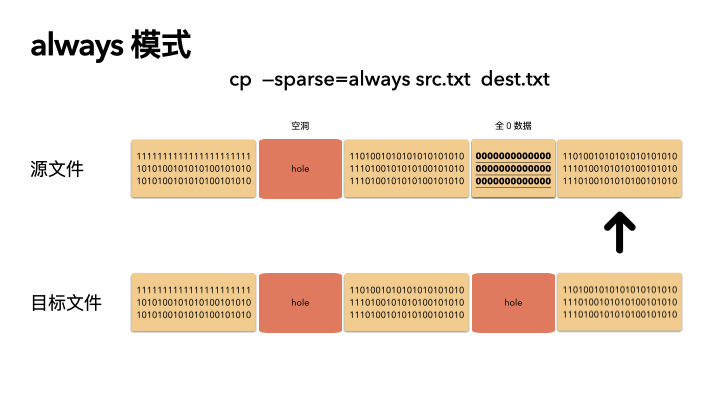
always
这种方式是最激进的,追求空间的最小化。在 auto 的基础之上,还多做了一步:对源文件内容做了判断。
在读出源数据之后,就算这块数据位置在源文件不是空洞,也会自己在程序里做一次判断,判断是否是全 0 的数据,如果是,那么也会在目标文件里对应的位置创建空洞(不分配物理空间)。
这种方式则会导致源文件的 size 和目标文件一样(三种策略下,文件size 都是不变的),但是 物理 blocks 占用却更小。
never
这种方式最保守,实现也最简单。不管源文件是否是稀疏文件,cp 完全不感知,读出来的任何数据都直接写入目标文件。也就是说,如果一个 100G 的文件,就算只占用了 4K 的物理空间,也会创建出一个 100G 的目标文件,物理空间就占用 100G。
所以,如果你 cp 的时候带了这个参数,那么将会非常非常慢。
深入剖析 cp --sparse 源码
上面的都是结论,现在我们通过源码再深入理解下 cp 的原理,一起围观下 cp 的代码实现。
cp 命令源码在 GNU 项目的 coreutils 项目中,为 Linux 提供外围的基础命令工具。看似极简的 cp,其实代码实现还挺有趣的。
cp 的入口代码在 cp.c 文件中(以下基于 coreutils 8.30 版本):
以一个 cp 文件的命令举例,我们一起走一下源码视角的旅途:
cp 。/src.txt dest.txt
首先,在 main 函数里初始化参数:
switch (c)
{
case SPARSE_OPTION:
x.sparse_mode = XARGMATCH (“--sparse”, optarg,
sparse_type_string, sparse_type);
break;
这里会根据用户传入的参数,对应翻译成一个枚举值,该枚举值就是 SPARSE_NEVER,SPARSE_AUTO,SPARSE_ALWAYS 其中之一,默认用户没带这个参数的话,就会是 SPARSE_AUTO:
static enum Sparse_type const sparse_type[] =
{
SPARSE_NEVER, SPARSE_AUTO, SPARSE_ALWAYS
};
所以,main 函数里赋值了 x.sparse_mode 这个参数,这个参数也是稀疏文件行为的指导参数,后面怎么处理稀疏文件,就依赖于这个参数。
下面就是依次调用 do_copy ,copy,copy_internal 函数,do_copy,copy 这两个函数就是处理一些封装,校验,包括涉及目录的一些逻辑,跟我们本次稀疏文件解密关系不大,直接略过。
copy_internal 则是一个巨长的函数,里面的逻辑多数是一些兼容性,适配场景的考虑,也和本次关系不大。对于一个普通文件( regular 类型) 最终调用到 copy_reg 函数,才是普通文件 copy 的实现所在。
else if (S_ISREG (src_mode)
|| (x-》copy_as_regular && !S_ISLNK (src_mode)))
{
copied_as_regular = true;
// 普通文件的拷贝
if (! copy_reg (src_name, dst_name, x, dst_mode_bits & S_IRWXUGO,
omitted_permissions, &new_dst, &src_sb))
goto un_backup;
普通文件的 copy 就是从函数 copy_reg 才真正开始的。在这个函数里,首先 open 源文件和目标文件的句柄,然后进行数据拷贝。
static bool
copy_reg( 。.. )
{
// 确认要拷贝数据
if (data_copy_required)
{
// 获取到块大小,buffer 大小等参数
size_t buf_alignment = getpagesize ();
size_t buf_size = io_blksize (sb);
size_t hole_size = ST_BLKSIZE (sb);
bool make_holes = false;
// 关键函数来啦,is_probably_sparse 函数就是用来判断源文件是否是稀疏文件的;
bool sparse_src = is_probably_sparse (&src_open_sb);
if (S_ISREG (sb.st_mode))
{
if (x-》sparse_mode == SPARSE_ALWAYS)
// sparse_always 模式,也是追求极致空间效率的策略;
// 所以这种方式不管源文件是否真的是稀疏文件,都会生成稀疏的目标文件;
make_holes = true;
// 如果是 sparse_auto 的策略,并且源文件是稀疏文件,那么目标文件也会是稀疏文件(也就是可以有洞洞的文件)
if (x-》sparse_mode == SPARSE_AUTO && sparse_src)
make_holes = true;
}
// 如果到这里判断不是目标不会是稀疏文件,那么就使用更有效率的方式来 copy,比如用更大的 buffer 来装数据,一次 copy 更多;
if (! make_holes)
{
// 略
}
// 源文件是稀疏文件的情况下,可以使用 extent_copy 这种更有效率的方式进行拷贝。
if (sparse_src)
{
if (extent_copy (source_desc, dest_desc, buf, buf_size, hole_size,
src_open_sb.st_size,
make_holes ? x-》sparse_mode : SPARSE_NEVER,
src_name, dst_name, &normal_copy_required))
goto preserve_metadata;
}
// 如果源文件判断不是稀疏文件,那么就使用标准的 sparse_copy 函数来拷贝。
if (! sparse_copy (source_desc, dest_desc, buf, buf_size,
make_holes ? hole_size : 0,
x-》sparse_mode == SPARSE_ALWAYS, src_name, dst_name,
UINTMAX_MAX, &n_read,
&wrote_hole_at_eof))
{
return_val = false;
goto close_src_and_dst_desc;
}
// 略
}
}
以上对于 copy_reg 的代码我做了极大的简化,把关键流程梳理了出来。
小结:
copy_reg 函数才是真正 cp 一个普通文件的逻辑所在,源文件的打开,目标文件的创建和数据的写入都在这里;
拷贝之前,会先用 is_probably_sparse 函数来判断源文件是否属于稀疏文件;
如果是 sparse always 模式,那么无论源文件是否是稀疏文件,那么都会尝试生成稀疏的目标文件(这种模式下,源文件如果是非稀疏文件,会判断是否是全 0 数据,如果是的话,还是会在目标文件中打洞);
如果是 sparse auto 模式,源文件是稀疏文件,那么生成的目标文件也会是稀疏文件;
源文件为稀疏文件的时候,会尝试使用效率更高的 extent_copy 函数来拷贝数据;
如果是 never 模式,那么是调用 sparse_copy 函数来拷贝数据,并且里面不会尝试 punch hole,拷贝过程会非常慢,会生成一个实打实的目标文件,物理空间占用完全和文件size一致;
上面的小结,提到几个有意思的点,我们一起探秘下几个问题。
问题一:is_probably_sparse 函数是怎么来判断源文件的?
看了源码你会发现,非常简单,其实就是 stat 一下源文件,拿到文件大小 size,还有物理块的占用个数(假设物理块 512 字节),比一下就知道了。
static bool
is_probably_sparse (struct stat const *sb)
{
return (HAVE_STRUCT_STAT_ST_BLOCKS
&& S_ISREG (sb-》st_mode)
&& ST_NBLOCKS (*sb) 《 sb-》st_size / ST_NBLOCKSIZE);
}
举个例子,文件大小 size 为 100G,物理占用块 8 个,那么 100G/512字节 》 8,所以就是稀疏文件。
文件大小 size 为 4K,物理占用块 8 个,那么 4K/512字节 == 8,所以就不是稀疏文件。
问题二:extent_copy 为什么更有效率?
关键在于里面的一个子函数 extent_scan_read 的实现,extent_scan_read 位于 extent-scan.c 文件中。extent_scan_read 位于 extent_copy 开头,用来获取到源文件的空洞位置信息。这个就是 extent_copy 高效率的根本原因。extent_scan_read 通过这个函数能够拿到文件的空洞的详细位置,那么拷贝数据的时候,就能针对性的跳过这些空洞,只拷贝有效的位置即可。
那么,不禁又要问, extent_scan_read 又是怎么实现的呢?
答案是:ioctl 系统调用,搭配 FS_IOC_FIEMAP 参数,也就是 fiemap 的调用。
/* Call ioctl(2) with FS_IOC_FIEMAP (available in linux 2.6.27) to obtain a map of file extents excluding holes. */
fiemap 这个是一个非常关键的特性,ioctl 搭配 FS_IOC_FIEMAP 这个函数能够拿到文件的物理空间分配关系,能够让用户知道长达 100G 的文件中,哪些位置才是真正有物理块存储数据的,哪些位置是空洞。
这个特性则由文件系统提供,也就是说,只有文件系统提供了这个对外接口,我们才能拿得到,比如 ext4,就支持这个接口,ext2 就没有。
问题二:sparse_copy 为什么慢,里面哟是做了啥?
这个函数是标准的 copy 函数,对比 extent_copy 来说,没有 fiemap 的加持,那么这个函数就自己判断是否是空洞,怎么判断?
sparse_copy 认为,只要大块连续的全 0 数据,那么就认为是空洞,目标文件就不用写入,直接打洞即可。
判断是否全 0 的函数是is_nul,位于 system.h 头文件中,实现非常简单,就是看整个内存块是否全部为 0 。
举个例子,现在 sparse_copy 从源文件里读出 4k 的数据,发现全都是 0,那么目标文件对应的位置就不会写入,而是直接 punch hole 打洞,节省空间。
但是注意了,这种行为只有在激进的 sparse always 策略才是这样的。如果是其他策略,sparse_copy 不会做这样做,而是老老实实的拷贝数据,哪怕是全 0 的数据,也要如实的写入到目标文件。
所以,always 模式下,目标文件所占物理空间比源文件小的根本原因就在于 sparse_copy 这个函数的实现。
cp 快速的原因
梳理到这里,cp 的秘密已经彻底揭开了,cp 一个 100G 的文件为什么那么快?
因为源文件是稀疏文件啊,文件看似 100G,实际只占用了 2M 的物理空间。文件系统将文件大小和物理空间占用这两个概念解耦,使得有更灵活的使用姿势,更有效的使用物理空间。
cp 默认的情况下,通过文件系统提供的 fiemap 接口,获取到文件所有的空洞信息,然后跳过这些空洞,只 copy 有效的数据,极大的减少了磁盘 io 的数据量,所以才那么快。
总结下 cp --sparse 三个参数的特点:
auto 模式:默认模式,最一致的模式(如果没有用户全0 块数据,那么可能也是速度最快的),会根据源文件的实际空间占用复制数据,目标文件和源文件一致。无论是文件 size 还是物理 blocks;
always 模式:追求最小空间占用的模式,就算源文件不是稀疏文件,而仅仅是有些连续大块的全 0 数据,也会尝试在目标文件上 punch hole,从而节省空间,这种方式会导致目标文件的物理 blocks 可能比源文件要小;
never 模式:最低效,速度最慢的方式。这种方式无论源文件是啥,全都是实打实的复制,不管是空洞还是全 0 数据,都会在目标文件写入;
动画演示(精髓):
精髓所在,前面知识点就算全都忘了,只记得这三张图,你也赚了。
cp src.txt dest.txt
cp --sparse=always src.txt dest.txt
cp --sparse=never src.txt dest.txt
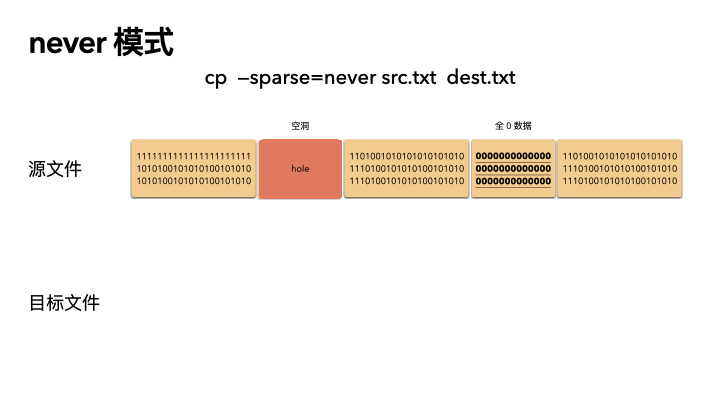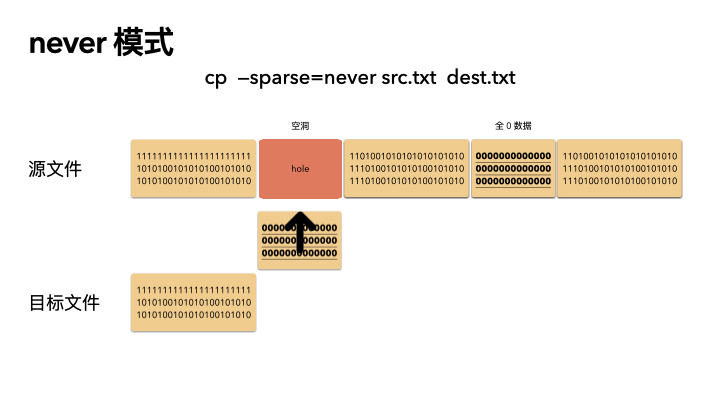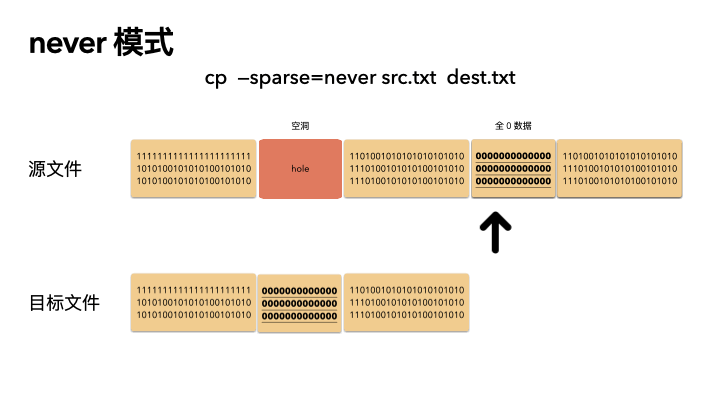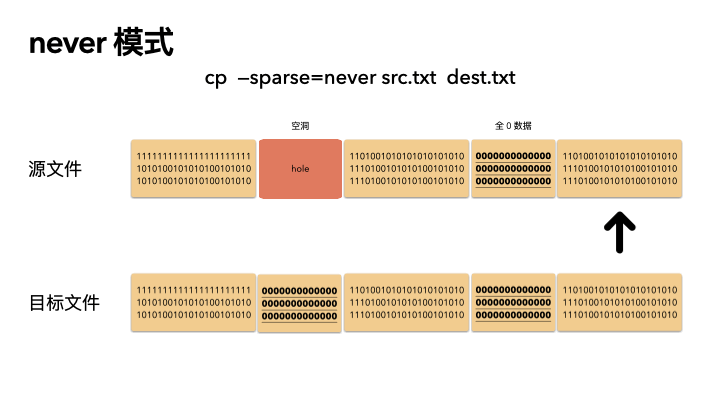
稀疏文件的应用
稀疏文件在哪些地方有应用呢?
数据库快照:生成一个数据库快照时会生成一个稀疏文件,稀疏文件一开始并不会占用磁盘空间。当源数据库发生写操作时,就把修改前的原数据块复制且只复制一次到稀疏文件中;
MySQL5.7 有一种数据压缩方式,其原理就是利用内核Punch hole特性,对于一个16kb的数据页,在写文件之前,除了 Page 头之外,其他部分进行压缩,压缩后留白的地方使用 punch hole 进行 “打洞”,在磁盘上表现为不占用空间,从而达到快速释放物理空间的目的;
qemu 磁盘镜像文件的空间回收场景;
一起做个实验
最后我们演示下实验,检验看下你懂了吗?找一台 linux 机器,跟着运行下面的命令。
初始条件准备
步骤一:创建一个文件(预期占用 1 个 block)。
echo =========== test ======= 》 test.txt
步骤二:truncate 成 1G 的稀疏文件。
truncate -s 1G 。/test.txt
步骤三:把 1M 到 1M+4K 的位置预分配出来(并且是写 0 分配,预期到这里要占用 2 个 block,也就是 8K 数据)。
fallocate -o 1048576 -l 4096 -z 。/test.txt
步骤四:stat 命令检查下情况。
sh-4.4# stat test.txt
File: test.txt
Size: 1073741824 Blocks: 16 IO Block: 4096 regular file
Device: 6ah/106d Inode: 3148347 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-03-12 1554.427903000 +0000
Modify: 2021-03-12 1500.456246000 +0000
Change: 2021-03-12 1500.456246000 +0000
Birth: -
我们看到 Size: 1073741824 Blocks: 16 ,Size 大小等于 1G,stat 显示的 Blocks 是扇区(512字节)的个数,也就是说,物理空间占用 8K,符合预期。
也就是说:
文件大小为 1G;
实际数据在 [0, 4K] 和 [1M, 1M+4K] 这两个位置才有写入;
其中 [0, 4K] 范围为正常数据, [1M, 1M+4K] 这段范围的数据为全 0 数据;
好,初始条件准备好了,下面我们开始对 cp --sparse 的三个行为做实验。
cp 的实验验证
默认策略:
cp 。/test.txt 。/test.txt.auto
always 策略:
cp --sparse=always 。/test.txt 。/test.txt.always
never 策略(这条命令敲下去可能有点慢哦,并且要预留好足够空间):
cp --sparse=never 。/test.txt 。/test.txt.never
以上三个命令敲完,生成了三个文件,给大家 1 秒钟的思考时间,思考下 test.txt.auto,test.txt.always,test.txt.never,这三个文件的属性有何异同。
。..。. 。..。. 。..。.
结果揭秘:
test.txt.auto
sh-4.4# stat 。/test.txt.auto
File: 。/test.txt.auto
Size: 1073741824 Blocks: 16 IO Block: 4096 regular file
Device: 6ah/106d Inode: 3148348 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-03-13 1557.395725000 +0000
Modify: 2021-03-13 1557.395725000 +0000
Change: 2021-03-13 1557.395725000 +0000
Birth: -
Size: 1073741824:文件大小 1G
Blocks: 8:物理空间占用 8K
test.txt.always
sh-4.4# stat 。/test.txt.always
File: 。/test.txt.always
Size: 1073741824 Blocks: 8 IO Block: 4096 regular file
Device: 6ah/106d Inode: 3148349 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-03-13 1501.064725000 +0000
Modify: 2021-03-13 1501.064725000 +0000
Change: 2021-03-13 1501.064725000 +0000
Birth: -
Size: 1073741824:文件大小 1G
Blocks: 8:物理空间占用 4K
test.txt.never
sh-4.4# stat 。/test.txt.never
File: 。/test.txt.never
Size: 1073741824 Blocks: 2097160 IO Block: 4096 regular file
Device: 6ah/106d Inode: 3148350 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-03-13 1504.774725000 +0000
Modify: 2021-03-13 1505.977725000 +0000
Change: 2021-03-13 1505.977725000 +0000
Birth: -
Size: 1073741824:文件大小 1G
Blocks: 2097160:物理空间占用 1G
所以,你学会了吗?
知识点总结
文件系统对外提供文件语义,本质只是管理磁盘空间的软件而已;
经典的文件系统主要划分 3 大块 superblock 区,inode 区,block 区(块描述区,bitmap区这里暂不介绍)。一个文件在文件系统的内部形态由一个 inode 记录元数据加上 block 存储用户存储用户数据样子;
文件系统的 size 是文件大小,是逻辑空间大小,文件大小 size 和真实的物理空间并不是一个概念;
稀疏语义是文件系统提供的一种特性,根本用途是用来更有效的利用磁盘空间;
后分配空间是空间利用最有效的方式,公有云的云盘靠什么赚钱?就是后分配,你买了 2T 的云盘,在没有写入数据的时候,一个字节都没给你分配,你却是付出 2T 的价格;
stat 命令能够查看物理空间占用,Blocks 表示的是扇区(512字节)个数;
稀疏文件的空洞和用户真正的全 0 数据是无法区分的,因为对外表现是一样的(这点非常重要);
cp 命令通过调用 ioctl(fiemap)系统调用,可以获取到文件空洞的分布情况,cp 过程中跳过这些空洞,极大的提高了效率(100G 的源文件,cp 只做了十几次 io 搞定了,所以 1 秒足以);
cp 的 sparse 参数从速度最快,空间最省,数据最拷贝最多,各有特点,小小的 cp 命令出来的目标文件,其实和源文件并不相同,只不过你没注意到;
预分配和 punch hole 其实都是fallocate 调用,只是参数不同而已,调用的时候,注意要 4k 对齐才能达到目的;
稀疏文件的 punch hole 应用有很多场景,通常是用来快速释放空间,比如镜像文件。
原文标题:深度剖析 Linux cp 命令的秘密
文章出处:【微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
Linux
+关注
关注
87文章
10969浏览量
206654 -
命令
+关注
关注
5文章
637浏览量
21845
原文标题:深度剖析 Linux cp 命令的秘密
文章出处:【微信号:LinuxHub,微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Jlink.exe(Jlink commander)的常用命令
linux常用命令有哪些
《Linux常用命令自学手册》工具书永远是常备的秘籍
《Linux常用命令自学手册》+一本手边linux速查字典
《Linux常用命令自学手册》+入门Linux的命令,就看这本书保你成高手
FTP常用命令的使用方法
《Linux常用命令自学手册》+试读报告
华为设备常用命令汇总
linux的常用命令





 工商网监
工商网监
评论