 预言未来今后的多核CPU是什么?
预言未来今后的多核CPU是什么?
随着莫尔定律的发展,IC设计者发现他们有许多硅,这些真实的资产来继续发展。David Chisnall有些他们要去尝试的冒险想法。
预言未来
明确的预言未来的技术是非常容易的,这东西将会变得更小,更快,更便宜。这将会在几个世纪里实现并且不大可能发生改变——至少到我们开车跑起来不加油的时候。这会变得更有趣,并且我们预计未来一些东西会变得更复杂。
一些受雇于未来主义者的人仅仅是尽量预测一些东西,和提起语言正在发生的人们,不久他们就忽略了一些正确的受争议的预测。这些接近工作有个限度,但是它不是非常有趣。
在计算机世界里一项好的技术看的是在大型计算机和超级计算机工作组上会发生什么和预测同样的排序运算在个人电脑领域会产生怎样的效果。当我在参加一个IBM 工程师关于他公司的新虚拟化技术的讨论时,这条规则对于像我开车回家。他谈论到他的公司有项优势是其他人的工作领域所没有的:不论什么时候他们被难住,他 们会独自去大厅的超级计算机设备那里去询问如何解决同样的问题在几十年前。
这种方法在未来是很好的指导:这些东西通常降下来,从低到高的消费阶层。
另一种趋势是昂贵高端的变得越来越小。SGI的错误是没有预料到这是正确的。大概10年前,SGI是一个生产高端昂贵图形硬件的公司。他们一直保持这种定 位;他们最后的硬件允许一些GPU共享同一个存储器因此紧紧的结合在一起工作。不同的是现在NVIDIA生产GPU。很多来自NVIDIA的人从前是在 SGI工作的,但是他们的管理部门不想让他们生产消费级别的图形加速设备,直到它能够和高端昂贵的硬件相媲美时。这些人们继续在自己的公司中,和现在他们 拥有20%的重要市场份额大于与SGI竞争的整个市场份额。更糟的是SGI的前途,一些十年前想要生产高端昂贵硬件的人们现在到了仅仅能够担负起消费税的 地步。新使用高端昂贵设备的经常会改变,但是最终消费部门追上。
这个阶段的成就
双核CPU第一次被商用领域的IBM制造出来的POWER4在几年之前。这个主意简单是:一些大型机器有许多CPU,如果把他们放在一个CPU中可以减少他们实际上的体积。
那些天,Intel和AMD跳跃到双核潮流上,它们的竞争朝向多核甚至更高。这是一个必然的开发环境,相应的到摩尔定律——其中一个重大的观察错误会在计算 中。莫尔定律的成立是在CPU中晶体管的数量每增加一倍需要12-24个月。(这个精确的周期有时变化,取决于你什么时候问戈登•摩尔,但是它通常报出是 18个月。)如果你想花费更多钱,你可以增加更多的晶体管;举个例子,Extreme Edition的Pentium系列把这些放在了更多缓存上。这个问题变成了他们增加了多于的晶体管。Pentium 2,1997发售,用了7.5亿晶体管。Itanium 2,2004年发售,用了592亿晶体管。它们大部分是缓存。CPU中加入缓存是好的,是一个增加晶体管的简单方法,缓存很简单,增加一些只是比芯片设计 的复制粘贴单元快了一些时间。不幸的是它开始减小,并且直接快速返回。一次全部工作进程转载入缓存,加入一些规则没用好处。
另一种手法是加入更多 核心,看最后的两个CPU的晶体管个数,我们看到2004年有必要生产80核心的Pentium 2。在十年前,它是节约的,可执行的方案来生产5000个P6核心。不幸的是,电源设备仅仅可以提供一个芯片的,这意味着需要它单独的供电设备。没用提到 靠液氮来冷却它提供一个稳定的支持。这看起来尽管像存储器技术只会在这个它们可以保存部分提供的数据的时期,每个都有自己的总线,但是你不能最低限度的使 用1000根针脚——64000跟为64位内存总线。甚至设计他们封装在一个芯片上分布象征一个工程挑战;设计主板将要链接存储器通道和内存bank是个 问题,这会给大部分PCB设计者重复的恶梦。
从芯片上抛弃一些缓存工作变慢了点。从芯片上跑多一些核心变得更慢。终于,不管怎么样,聪明的解决方法将会出现的。
RISC相对于CISC
其中一次大辩论在上世纪80年代和90年代中是否RISC或者CISC指令接近的部分设计是否正确。这个主意在RISC之后提供了个简单的指令用在平台的复杂计算上,很快人们需要复杂指令的CISC为了他们自己的需要。
具体化的CISC设计是VAX,写VAX汇编和写高级代码没用太大不同。在稍后的VAX系统中,一些指令是微代码,这些意味着分解在简单些的真是指令后就是 在实际硬件上运行的。在VAX后,Digital发明了Alpha,这芯片相对的出色。Alpha有一个微指令集,但是运行的异常快。在几年里,它是可以 买到的最快的微处理器。甚至到现在,500强计算机中还有一些基于Alpha的,一个不好的事实是这种芯片不会在现今的开发环境中超过五年。
在早些年,RISC做到很好。编译器编写者喜欢这种芯片;它可以简单明白指令集,和它在构建RISC指令集上比在CISC上更简单的了解复杂语言。
第一个问题在RISC上的原理变得明显改善在操作部分。早期RISC芯片没有除法指令;一些甚至不能有乘法指令。相反的,他们创建了一连串的超过早期的指 令,像变换操作。这不是一个软件开发问题;他们会仅复制一连串的指令以在机器结构内部完成除法,放一个宏指令在某些地方,用它像我们有一个除法指令时。这 样一些人找到一个高效的方法使用除法。下一代CPU的除法指令执行操作在几个循环中,直到那些循环外部的数据执行一系列的数据用起来像个代替品。这带到更 远的一步是Intel最后一代核心的微代码结构。一些连续的简单的x86操作现在是一个简单的指令集合。
RISC原理的一些部分继续存在。它一直 广泛的被关注像是一个好主意在指令集的正交上,举个例子,因为提供乘法运算的方法做一件事是在浪费硅晶体。不管怎样,简单指令集的方法被列出。甚至现在的 PowerPC和SPARC芯片是占有了占有市场像RISC处理器一样没能意识到那些RISC创造的周期。
SIMD和更多
后来一个相对普通的特点在高性能计算机领 域,Pentium MMX是第一个x86芯片加入单指令多数据流(SIMD)指令集。这些指令精确列举他们的建议,提供一种方法执行同样的数据乘法操作。稍后传统(数量)指 令回去掉从另一处来的数据,SIMD对应的能去掉四个数据从四个数据中,执行同样的操作在四次输入上。这种运算用在许多图片和视频程序上。
SIMD 指令加入CPU是相对便宜的,提供一个好的回报在投入上。如果你的进程消耗你10%的CPU你要升级,你不太可能注意到这现在仅仅花费5%。有过你有个进 程占用了100%的CPU,你会很幸运的注意到,如果原来需要10分钟运行的程序现在需要2分钟。许多应用SIMD的好处是从SIMD到后面的类型——运 行用了大量CPU能源——因此允许它们运行的更快提供一个可察觉的改善。
超过SIMD,一些进程有合适的指令进行特定运算。VIA的C3,举个例 子,有些指令专门用于为AES加密运算加速。C7加入了一些为SHA-1和SHA-256哈希运算的加速。像图形,关于密码的计算典型的基于CPU。他们 像是更加重要在将来,像这样的数据发送到网络,更多的机器和移动设备上。这不是罕见的在偷窃时查看为一个便携电脑硬件所进行的AES加密运算;加快AES 运算在机器上用磁盘做更快。硬件加速密码破译不是新的。一些公司生产PCI卡形式的密码加速器。
图形处理单元(GPU)
后来只有一些电脑有一个专用的密码加速卡,大部分有个图形处理器。每代GPU越来越相同。这些天,GPU用在很多高性能计算机应用中,因为GPU有庞大的计算能力。在效果上,GPU时个超标量流顶点处理器,它并行处理一些SIMD指令流在很快。
在设计上,GPU和Pentium 4有许多相同的地方。他们都用了超长管线允许他们一次使用许多指令。他们执行起来很糟糕如果其中一个管线预报了错误。这是Pentium 4的一个问题直到这个支流被发现,平均大约每7个指令。它对于GPU不是大问题,这样的设计时为了执行特殊运算,不会陷入更多的错误分歧中。
现在 的环境在PC世界中很像20年前。回到那时,电脑有几个处理器时不寻常的,一个时我们为什么要叫做的中央处理器(CPU)。CPU的一般目的时计算和协调 与其他CPU的活动。通常,工作站和高端昂贵PC有一个浮点处理器(FPU)进行浮点运算。始于80486,FPU同CPU在相同的领域消失了。另外的普 通加法运算时内存管理单元。这个单元控制物理和虚拟内存之间的转换;那些日子里,你很难找到CPU里没用MMU单元的。一个现代电脑有一个CPU和并行的 浮点运算器。它不需要很大的飞跃来想象Intel最终要把一个或两个GPU核心加入CPU中。
在这点上,你或许想这是可能升级的范围,因此它值得 向后退一步看CPU的发展。2005年,苹果的便携式电脑首次销量上超过了台式电脑。这依然在工业上跟随。这个增长范围在移动GPU的销量上大大超过了在 桌面GPU上的销量,Intel在CPU和GPU市场时最大的玩家。很少的人升级他们的GPU在便携式电脑上。
浮点处理器,内存控制单元和 顶点处理器已经准备加入现代的处理器中。数字信号处理单元(DSP)已经加入了一部分数量的处理器中,它们像是他们将要发现他们的方法不久在消费者的 CPU中。第一次用到附加的晶体管时加入了许多执行单元,制造深流水线和更宽的超标量结构,和更多的缓存。现在我们加入整个同种的处理单元。尽管只有一些 级别透过范围。这一步从单核到双核是巨大的改善;在我的电脑的一个CPU上分配75%的CPU资源是少有的,更多普通的将要分配50%,将要在停止共享和 其他程序或核心之间。
从双核到四核将会是一个非常小的改善,单仍有意义。当年升级到32核或64核,事情就变得有趣了。它经常是必须的写线程代码 在某些程度上并且使用起来不能有很多漏洞。这些应用一个异步信息很容易,接近于穿过,但是流行的桌面开发环境API没有设计围绕这个模式。在实际上,很少 的桌面软件用到这些。一些例如,视频编辑。举例子,能吃掉不少抛出的像你将来预料到的CPU资源。已经收缩的高端性能将会继续。那些日子里,一些人主意到 1GHz Athlon和3GHz Core 2 Duo的区别在绝大多数时候。一些人需要最快的电脑可买到的已经相当小。需要中档速度机器的人的数量将要收缩。
移动计算和精确数据中心的继续增长,电的消耗变得更加重要。猜想一个32核CPU允许你关闭核心当你不使用它的时候。在移动领域,你大概最好需要2到3个核心。
不同类型核心的CPU
如果你只有一少部分核心在你的进程上,你就开始惊叹为什么它们存在。少数应用程序需要所有核心为了加快运行速度在专门的硬件上,因此我们用什么代替它?
我们开始看这个将要形成的趋势。例子包含了苹果的Core视频;它将会运行在你的CPU上如果你需要,它有在CPU的顶点单元如果有,或者GPU需要更快。 OpenSSL将会运行在密码加速卡上如果它存在,或者运行在CPU上如果它没有。存在于普通运算的抽象接口是一种功能使它更加容易在硬件上执行;只有一 些小的变化是必须使用一些功能的优势。我们看到OpenGL上的一些相同的东西;顶点变换和光线运算在图形硬件上必须有个新驱动要写,但是不能修改现行的 应用代码。最重要的,专用的硅制造的硬件的效率比一般用途的硬件效率高在未来的工作上,电能的消耗像是更少。
如果让硅进入太空,为什么没有让一个 CPU进入死亡?一个密码加速器呢?专用硬件在其它昂贵的逻辑计算上如何?当他们不用时,你可以关闭他们。当年需要时,他们将会占用一点能源允许同样的计 算在普通硬件上,第一步这里整合了FPU和SIMD单元。下一步将要像整合GPU那样在一起。超越这些,它好像关系到大多数专用硬件的优势。在一些实例 上,我们将会简单的看到扩展的基本指令集(像发生在浮点和SIMD指令的)提供运算一些在逻辑上的传统运算。终于,我们看起来像是那些引申的超过单指令。
我看起来有个主意是封装到FPGA中像是十分动人的。这将允许许多灵活的运算,但是像一个有意义的能源消耗。
责任编辑:lq6
-
芯片
+关注
关注
446文章
47746浏览量
409042 -
双核cpu
+关注
关注
0文章
5浏览量
7786 -
晶体管
+关注
关注
76文章
9045浏览量
135162 -
浮点处理器
+关注
关注
0文章
6浏览量
7666
发布评论请先 登录
相关推荐
使用TCPWM信道同时使用两个内核CM7_0和CM7_1并生成中断,如何在多核CPU中配置TCPWM?
浅谈多CPU、多核CPU、超线程技术、SMP

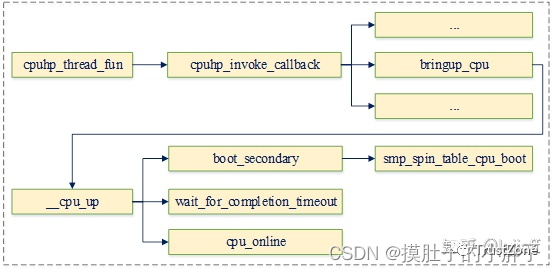
SMP多核secondary cpu启动流程
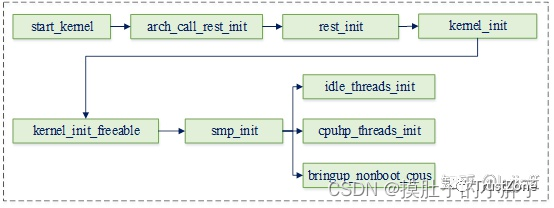
SMP多核启动cpu操作函数
工程师说 | RX系列软件的历史和今后的展望 #6

AUTOSAR架构下的多核通信介绍

基于Tricore芯片的AUTOSAR架构下的多核启动
基于Tricore架构的RTThread多核实现
多核CPU的启动方式
中国首颗ARM+RISC-V异构多核MCU伴随IAR在上海国际嵌入式展亮相
在 IAR Embedded Workbench中进行ARM+RISC-V多核调试
在IAR Embedded Workbench中进行ARM+RISC-V多核调试





 工商网监
工商网监
评论