 增量学习的概念
增量学习的概念
1. 增量学习的概念
1.1 什么是增量学习
人类有终身不断获取、调整和转移知识的能力,虽然在我们的一生中,我们确实倾向于逐渐忘记之前学习过的知识,但只有在极少的情况下,对新知识的学习会灾难性地影响已经学到的知识,这样的学习能力被称为增量学习的能力。
具体来讲,「增量学习的能力就是能够不断地处理现实世界中连续的信息流,在吸收新知识的同时保留甚至整合、优化旧知识的能力。」
增量学习(Incremental Learning)已经有20多年的研究历史,但增量学习更多地起源于认知神经科学对记忆和遗忘机制的研究,因此不少论文的idea都启发于认知科学的发展成果,本文不会探讨增量学习的生物启发,关于面向生物学和认知科学的增量学习综述可见 Continual lifelong learning with neural networks: A review[1]。
1.2 为什么要增量学习
在机器学习领域,增量学习致力于解决模型训练的一个普遍缺陷:「灾难性遗忘(catastrophic forgetting)」,也就是说,一般的机器学习模型(尤其是基于反向传播的深度学习方法)在新任务上训练时,在旧任务上的表现通常会显著下降。
造成灾难性遗忘的一个主要原因是「传统模型假设数据分布是固定或平稳的,训练样本是独立同分布的」,所以模型可以一遍又一遍地看到所有任务相同的数据,但当数据变为连续的数据流时,训练数据的分布就是非平稳的,模型从非平稳的数据分布中持续不断地获取知识时,新知识会干扰旧知识,从而导致模型性能的快速下降,甚至完全覆盖或遗忘以前学习到的旧知识。
为了克服灾难性遗忘,我们希望模型一方面必须表现出从新数据中整合新知识和提炼已有知识的能力(可塑性),另一方面又必须防止新输入对已有知识的显著干扰(稳定性)。这两个互相冲突的需求构成了所谓的「稳定性-可塑性困境(stability-plasticity dilemma)」。
解决灾难性遗忘最简单粗暴的方案就是使用所有已知的数据重新训练网络参数,以适应数据分布随时间的变化。尽管从头训练模型的确完全解决了灾难性遗忘问题,但这种方法效率非常低,极大地阻碍了模型实时地学习新数据。而增量学习的主要目标就是在计算和存储资源有限的条件下,在稳定性-可塑性困境中寻找效用最大的平衡点。
1.3 增量学习的特点
增量学习和持续学习(Continual Learning)、终身学习(Lifelong Learning)的概念大致是等价的,它们都是在连续的数据流中训练模型,随着时间的推移,更多的数据逐渐可用,同时旧数据可能由于存储限制或隐私保护等原因而逐渐不可用,并且学习任务的类型和数量没有预定义(例如分类任务中的类别数)。
但增量学习目前还没有一个特别清晰的定义,因此比较容易与在线学习,迁移学习和多任务学习等概念混淆,「尤其要注意增量学习和在线学习的区别,在线学习通常要求每个样本只能使用一次,且数据全都来自于同一个任务,而增量学习是多任务的,但它允许在进入下一个任务之前多次处理当前任务的数据」。上图表现了增量学习和其他学习范式的区别,一般来说,增量学习有如下几个特点:
学习新知识的同时能够保留以前学习到的大部分知识,也就是模型在旧任务和新任务上均能表现良好。
计算能力与内存应该随着类别数的增加固定或者缓慢增长,最理想的情况是一旦完成某一任务的学习,该任务的观测样本便被全部丢弃。
模型可以从新任务和新数据中持续学习新知识,当新任务在不同时间出现,它都是可训练的。
由于增量学习问题的复杂性和挑战的多样性,人们通常只讨论特定设置下的增量学习。以一个图像分类模型为例,我们希望模型具有增量学习新的图像和新的类别的能力,但前者更多地与迁移学习有关,因此任务增量学习(Task-incremental Learning)和难度更高一点的类增量学习(Class-incremental Learning)是深度学习社区当前主要考虑的增量学习范式。
「本文主要讨论近几年关注度最高的类增量学习范式」,更广泛更详细的增量学习介绍可参考专著《Lifelong Machine Learning》[2]。
2. 增量学习的实现方式
增量学习是一个连续不断的学习过程,在这个过程中,我们假设模型已经学习了前 个任务:,当面对任务 和对应的数据 时,我们希望可以利用从旧任务中学习到的先验知识帮助 的学习,然后更新模型所学习到的知识。这个过程要求我们在当前任务 中寻找参数 最小化下面的损失函数:
其中旧数据 是部分可见或完全不可见的。
增量学习方法的种类有很多种划分方式,本文将其划分为以下三种范式:
正则化(regularization)
回放(replay)
参数隔离(parameter isolation)
其中基于正则化和回放的增量学习范式受到的关注更多,也更接近增量学习的真实目标,参数隔离范式需要引入较多的参数和计算量,因此通常只能用于较简单的任务增量学习。关于其他划分方式和不同类别的增量学习的优缺点对比可见A Comprehensive Study of Class Incremental Learning Algorithms for Visual Tasks[3],下面仅介绍基于正则化和回放的增量学习的经典方法以及相关进展。
2.1 基于正则化的增量学习
基于正则化的增量学习的主要思想是「通过给新任务的损失函数施加约束的方法来保护旧知识不被新知识覆盖」,这类方法通常不需要用旧数据来让模型复习已学习的任务,因此是最优雅的一类增量学习方法。Learning without Forgetting (ECCV 2016)[4]提出的LwF算法是基于深度学习的增量学习的里程碑之作,在介绍LwF算法之前,我们先了解一些最简单的增量学习方法。
上图展示了一个具有多头网络结构的模型学习新任务的不同策略,其中(a)为已经训练好的基于CNN的原始模型, 表示不同任务共享的CNN参数, 表示与原始任务相关的MLP参数,当加入一个新的分类任务时,我们可以增加一个随机初始化的MLP参数 。基于 来学习 的方法包括如下几类:
微调(Fine-tuning):微调没有旧任务参数和样本的指导,因此模型在旧任务上的表现几乎一定会变差,也就是发生灾难性遗忘。
联合训练(Joint Training):联合训练相当于在所有已知数据上重新训练模型,效果最好,因此通常被认为是「增量学习的性能上界」,但训练成本太高。
特征抽取(Feature Extraction):特征抽取只训练 ,共享参数 没有得到更新,虽然不影响模型在旧任务上的表现,但不能有效捕获新任务独有的特征表示,在新任务上的表现通常不如人意。
LwF算法是介于联合训练和微调训练之间的训练方式,LwF的特点是它不需要使用旧任务的数据也能够更新 。LwF算法的主要思想来自于knowledge distillation[5],也就是使新模型在新任务上的预测和旧模型在新任务上的预测相近。
具体来说,LwF算法先得到旧模型在新任务上的预测值,在损失函数中引入新模型输出的蒸馏损失,然后用微调的方法在新任务上训练模型,从而避免新任务的训练过分调整旧模型的参数而导致新模型在旧任务上性能的下降。算法流程如下图所示,其中 用于权衡模型的稳定性和可塑性。
但是,这种方法的缺点是高度依赖于新旧任务之间的相关性,当任务差异太大时会出现任务混淆的现象(inter-task confusion),并且一个任务的训练时间会随着学习任务的数量线性增长,同时引入的正则项常常不能有效地约束模型在新任务上的优化过程。
不少研究者围绕着LwF算法的思想提出了很多改进策略,比较有名的包括Encoder Based Lifelong Learning (ICCV 2017)[6]提出的基于低维特征映射的EBLL算法,以及Overcoming catastrophic forgetting in neural networks (PNAS 2017)[7]提出的基于贝叶斯框架的EWC算法,EWC算法实际上对应了一个通用的「参数约束」方法,它引入了一个额外的和参数有关的正则损失:
该损失会根据不同参数的重要性来鼓励新任务训练得到的新模型参数尽量靠近旧模型参数。后续对EWC作出改进了论文也很多,比如Rotate your Networks: Better Weight Consolidation and Less Catastrophic Forgetting (ICPR 2018)[8]。
概括起来,基于正则化的增量学习方法通过引入额外损失的方式来修正梯度,保护模型学习到的旧知识,提供了一种缓解特定条件下的灾难性遗忘的方法。不过,虽然目前的深度学习模型都是过参数化的,但模型容量终究是有限的,我们通常还是需要在旧任务和新任务的性能表现上作出权衡。近几年,不少研究者也提出了各种类型的正则化手段,有兴趣的话可以参考下面的论文:
Learning without Memorizing (CVPR 2019)[9]
Learning a Unified Classifier Incrementally via Rebalancing (CVPR 2019)[10]
Class-incremental Learning via Deep Model Consolidation (WACV 2020)[11]
2.2 基于回放的增量学习
从字面意思上来看,基于回放的增量学习的基本思想就是"温故而知新",在训练新任务时,一部分具有代表性的旧数据会被保留并用于模型复习曾经学到的旧知识,因此「要保留旧任务的哪部分数据,以及如何利用旧数据与新数据一起训练模型」,就是这类方法需要考虑的主要问题。
iCaRL: Incremental Classifier and Representation Learning (CVPR 2017)[12]是最经典的基于回放的增量学习模型,iCaRL的思想实际上和LwF比较相似,它同样引入了蒸馏损失来更新模型参数,但又放松了完全不能使用旧数据的限制,下面是iCaRL设计的损失函数:
LwF在训练新数据时完全没用到旧数据,而iCaRL在训练新数据时为每个旧任务保留了一部分有代表性的旧数据(iCaRL假设越靠近类别特征均值的样本越有代表性),因此iCaRL能够更好地记忆模型在旧任务上学习到的数据特征。
另外Experience Replay for Continual Learning (NIPS 2019)[13]指出这类模型可以动态调整旧数据的保留数量,从而避免了LwF算法随着任务数量的增大,计算成本线性增长的缺点。基于iCaRL算法的一些有影响力的改进算法包括End-to-End Incremental Learning (ECCV 2018)[14]和Large Scale Incremental Learning (CVPR 2019)[15],这些模型的损失函数均借鉴了知识蒸馏技术,从不同的角度来缓解灾难性遗忘问题,不过灾难性遗忘的问题还远没有被满意地解决。
iCaRL的增量学习方法会更新旧任务的参数 ,因此很可能会导致模型对保留下来的旧数据产生过拟合,Gradient Episodic Memory for Continual Learning (NIPS 2017)[16]针对该问题提出了梯度片段记忆算法(GEM),GEM只更新新任务的参数而不干扰旧任务的参数,GEM以不等式约束的方式修正新任务的梯度更新方向,从而希望模型在不增大旧任务的损失的同时尽量最小化新任务的损失值。
GEM方向的后续改进还有Efficient Lifelong Learning with A-GEM (ICLR 2019)[17]和Gradient based sample selection for online continual learning (NIPS 2019)[18]。
另外,也有一些工作将VAE和GAN的思想引入了增量学习,比如Variational Continual Learning (ICLR 2018)[19]指出了增量学习的贝叶斯性质,将在线变分推理和蒙特卡洛采样引入了增量学习,Continual Learning with Deep Generative Replay (NIPS 2017)[20]通过训练GAN来生成旧数据,从而避免了基于回放的方法潜在的数据隐私问题,这本质上相当于用额外的参数间接存储旧数据,但是生成模型本身还没达到很高的水平,这类方法的效果也不尽人意。
总体来说,基于回放的增量学习的主要缺点是需要额外的计算资源和存储空间用于回忆旧知识,当任务种类不断增多时,要么训练成本会变高,要么代表样本的代表性会减弱,同时在实际生产环境中,这种方法还可能存在「数据隐私泄露」的问题。
3. 增量学习的应用
增量学习的优点是可以随时训练新数据,不需要保留大量训练数据,因此存储和计算开销都比较小,同时还能够有效避免用户的隐私泄露问题,这在「移动边缘计算的场景」下是非常有价值有意义的。「但目前的增量学习依旧是一个很开放的研究问题,很大程度上还处于理论探索阶段,在很多方面学界都没有达成统一的共识,不少论文给出的结论常常会相互冲突,因此增量学习还没有在细分领域中得到大规模的应用和落地。」
3.1 计算机视觉
大部分增量学习研究都是面向图像分类任务的,近几年也有不少论文将增强学习推广到了更复杂目标检测和语义分割任务上,下面列举了一些有代表性的工作。
图像分类
A comprehensive, application-oriented study of catastrophic forgetting in DNNs (ICLR 2019)[21]
A Comprehensive Study of Class Incremental Learning Algorithms for Visual Tasks[22]
目标检测
Incremental Few-Shot Object Detection (CVPR 2020)[23]
Incremental Learning of Object Detectors without Catastrophic Forgetting (ICCV 2017)[24]
语义分割
Modeling the Background for Incremental Learning in Semantic Segmentation (CVPR 2020)[25]
Incremental Learning Techniques for Semantic Segmentation (ICCV workshop 2019)[26]
Incremental Learning for Semantic Segmentation of Large-Scale Remote Sensing Data[27]
3.2 自然语言处理
目前增量学习的研究主要还是面向计算机视觉,在自然语言处理领域还没有得到太多关注。一个主要原因是目前自然语言处理社区的注意力主要集中在以BERT为代表的自监督表示学习上,在大规模预训练模型的推广下,增量学习的应用价值就不是太明显了。
LAMOL: LAnguage MOdeling for Lifelong Language Learning (ICRL 2020)[28]
Episodic Memory in Lifelong Language Learning (NIPS 2019)[29]
Continual Learning for Sentence Representations Using Conceptors (NAACL 2019)[30]
Neural Topic Modeling with Continual Lifelong Learning (ICML 2020)[31]
Incremental Natural Language Processing: Challenges, Strategies, and Evaluation (COLING 2018)[32]
3.3 机器人
机器人是增量学习天然的应用场景,因为机器人必须学会通过连续的观察来适应环境并与之互动,增量学习正好能够很好地刻画真实世界的环境,不过机器人领域本身有很多更重要的问题需要解决,因此增量学习的应用也不太多。
Continual Learning for Robotics: Definition, Framework, Learning Strategies, Opportunities and Challenges[33]
Efficient Adaptation for End-to-End Vision-Based Robotic Manipulation (ICML workshop 2020)[34]
4. 增量学习面临的问题和挑战
4.1 定量评估指标
增量学习的一些常见评估指标包括「准确率、记忆能力和迁移能力」等,其中记忆能力和迁移能力是衡量模型可塑性和稳定性的指标,但这些指标具体的公式定义却是有争议的。虽然人们已经提出了各种各样的增量学习方法,但是在基准数据集的选取和评估算法有效性的指标上还没有达成广泛的共识。
其中一点是增量学习通常需要引入额外的超参数来平衡模型的稳定性和可塑性,这些超参数通常在验证集上被优化,「但这本质上违反了增量学习不能获取未来数据的因果律,从而会导致人们作出过于乐观的结论,在真实的生产环境中常常无法重现实验结果。」
针对超参数选取的问题,A continual learning survey: Defying forgetting in classification tasks (2020)[35]提出了一种通用的增量学习超参数搜索框架,并设计了一系列相对公平的指标来比较增量学习算法,汇报了一些SOTA增量学习算法的表现。
在此基础上,Class-incremental learning: survey and performance evaluation (2020)[36]在多个数据集上对最新的一些增量学习方法进行了综合对比,作者发现在基于正则化的增量学习中,最早提出的LwF算法的表现是相当稳健的,许多后续改进的方法在一些条件下反而不如LwF算法,另外基于数据约束的方法(LwF)实际上通常比基于参数约束的方法(EWC)表现得更好,然而目前人们的研究注意力是偏向后者的。下面是另外一些讨论和提出增量学习评估指标和模型对比的论文,这里不再一一介绍:
A comprehensive, application-oriented study of catastrophic forgetting in DNNs (ICLR 2019)[37]
Don’t forget, there is more than forgetting: new metrics for Continual Learning (ICML workshop 2020)[38]
Towards robust evaluations of continual learning[39]
4.2 真正的增量学习
增量学习本身是一个很开放的概念,目前人们研究的基于深度学习的增量学习大多限制在「有监督分类、任务式增量和多头网络结构的框架」下,这种特定领域的训练方案通常不能直接应用于高度动态化和非结构化的真实环境中,Towards Robust Evaluations of Continual Learning[40]指出「多头设定下的增量学习隐藏了增量学习问题真正的难度」。另外,虽然目前人们主要研究的是有监督学习,但探索更接近真实环境的无监督增量学习,以及其他类型的增量方式也是非常有意义的。
目前的增量学习方法通常「隐式地要求任务的性质差异不能太大」,当任务的性质和难度差异太大时,大部分增量学习方法的性能都会严重下降,甚至低于简单的基线模型。另外,有不少研究表明「目前还没有任何一种增量学习方法在任何条件下都能表现良好」,大部分增量学习方法「对模型结构,数据性质、超参设定都比较敏感」,因此探索在所有任务设定中表现更稳健的增量学习方法也是很有意义的。
责任编辑:lq
-
图像分类
+关注
关注
0文章
87浏览量
11838 -
机器学习
+关注
关注
66文章
8116浏览量
130546
原文标题:增量学习(Incremental Learning)小综述
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
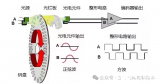
增量式编码器原理图及参数说明
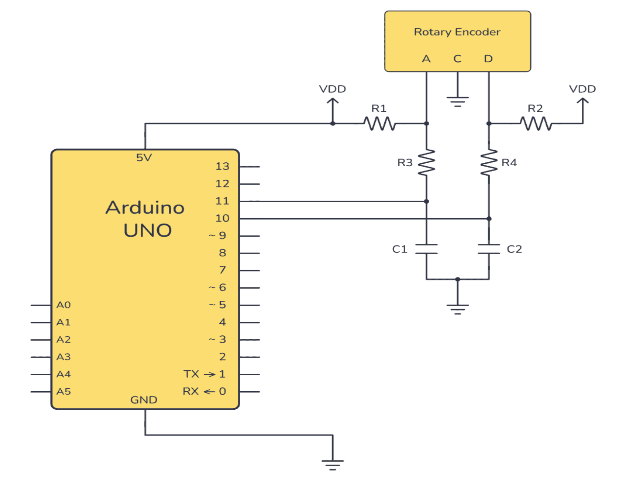
如何将增量旋转编码器与Arduino连接


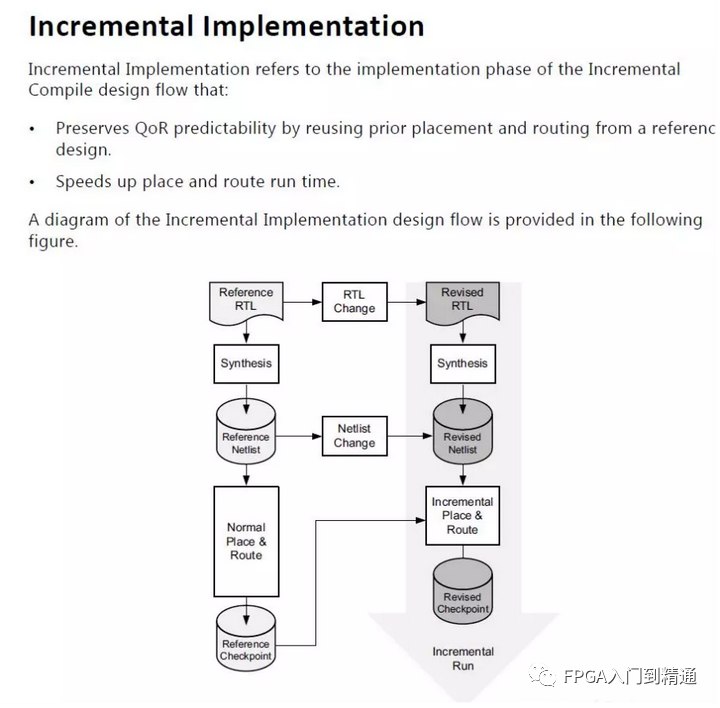
Xilinx Vivado使用增量实现

深度学习和机器学习的定义和优缺点 深度学习和机器学习的区别
机器学习算法入门 机器学习算法介绍 机器学习算法对比
深度学习基本概念
选择增量编码器分辨率的方法,影响增量式编码器分辨率的因素
Vivado增量编译的基本概念、优点、使用方法以及注意事项
ROS学习笔记之ROS基本概念
增量型编码器与绝对值编码器






 工商网监
工商网监
评论