 利用ImageNet训练了一个能降噪、超分和去雨的图像预训练模型
利用ImageNet训练了一个能降噪、超分和去雨的图像预训练模型
说到Transformer,大家可能会想到BERT[1]、GPT-3[2]等等,这些都是利用无监督训练的大型预训练模型。既然Transformer也能用在CV上,那么能不能做类似的事情呢?这篇论文利用ImageNet训练了一个能降噪、超分和去雨的图像预训练模型(IPT)。
Motivation
目前很多low-level的task其实都是有一定相关性的,就是在一个low-level task上预训练对另一个task是有帮助的,但是目前几乎没有人去做相关的工作。而且pre-training在某些数据稀缺的task上就很有必要,并且无论在CV还是NLP,使用pre-trained model是非常常见的事情。对于一些输入和输出都是image的low-level算法来说,目前的pre-trained model显然是不适合的。
准备数据集
因为Transformer需要大量的数据去拟合,所以必须使用一个大型的数据集。在这篇论文中,作者用的是imagenet。对于imagenet的每一张图片生成各种任务对应的图像对,例如对于超分(super-resolution)来说,模型的输入数据是imagenet经过下采样的数据,而标签是原图。
IPT
在上篇文章介绍过了,因为Transformer本身是用于NLP领域的,输入应该是一个序列,因此这篇的论文做法和ViT[3]一样,首先需要把feature map分块,每个patch则视为一个word。但是不同的是,因为IPT是同时训练多个task,因此模型定义了多个head和tail分别对应不同的task。
整个模型架构包含四个部分:用于提取特征的heads、Transformer Encoder、Transformer Decoder和把feature map还原成输出的tails。
Heads
不同的head对应于不同的task,由于IPT需要处理多个task,因此是一个multi-head的结构,每个head由3层卷积层组成。Heads要完成的任务可以描述为:fH = Hi(x),x是输入图像,f是第i个Head的输出。
Transformer encoder
在输入Transformer前,需要将Head输出的feature map分成一个个patch,同样还需要加入位置编码信息,与ViT不同,这里是直接相加就可以作为Transformer Encoder的输入了,不需要做linear projection。
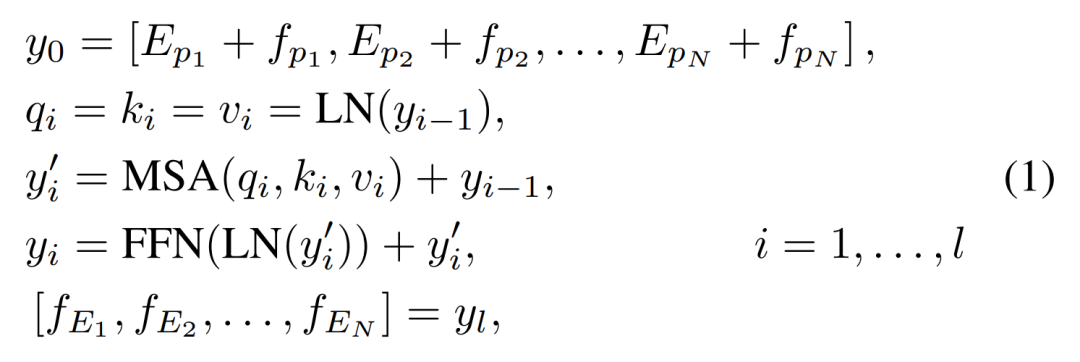
fpi是feature map的一个patch,Epi∈ RP*P×C是fpi的learnable position encoding。LN是layer normalization,MSA是多头self-attention模块,FFN是feed forward network。
Transformer decoder
Transformer decoder的输入时encoder的输出和task embedding。这些task embedding是可训练的,不同的task embedding代表处理不同的task。decoder的计算可以表示如下:
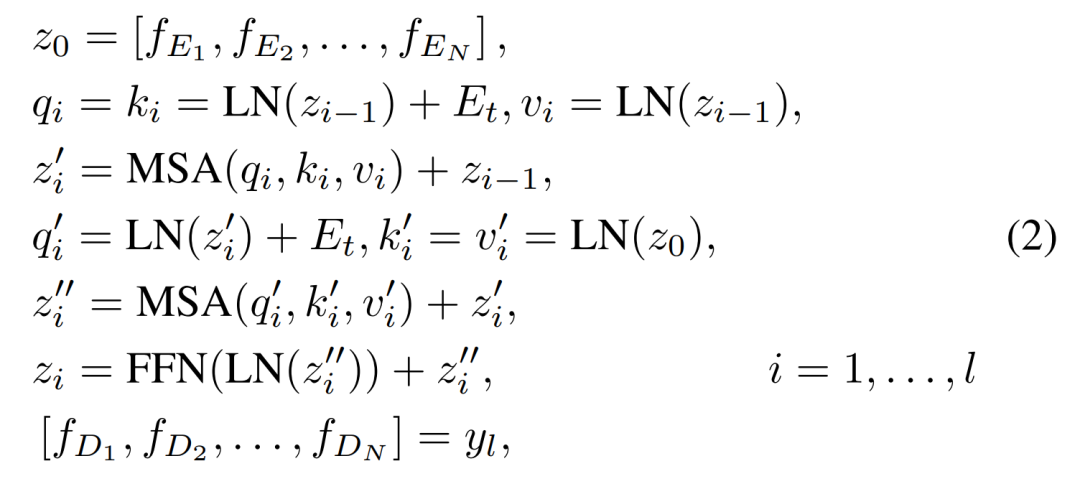
fEi是指encoder的输出,fDi是指decoder的输出。
Tails
Tails与Heads是相对应的,但是不同的tail的输出的大小可能不一样,例如超分,做超分时输出比输入的图像大,因此与其它的tail输出的大小可能不一样。
Loss
loss由两部分组成,分别是Lcontrastive和Lsupervised的加权和。
Lsupervised是指IPT的输出与label的L1 loss。
加入Lcontrastive是为了最小化Transformer decoder对于来自同一张图的不同patch的输出的距离,最大化对于不同图片的patch之间的输出的距离。
实验与结果
作者用了32块NVIDIA Tesla V100,以256的batch size训练了200个epoch。
Reference
[1]Jacob Devlin, Ming-Wei Chang, Kenton Lee, and KristinaToutanova. Bert: Pre-training of deep bidirectionaltransformers for language understanding. arXiv preprintarXiv:1810.04805, 2018.
[2]Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al.Language models are few-shot learners. arXiv preprintarXiv:2005.14165, 2020.
[3]Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
责任编辑:lq
-
模型
+关注
关注
1文章
2701浏览量
47658 -
数据集
+关注
关注
4文章
1176浏览量
24340 -
nlp
+关注
关注
1文章
463浏览量
21812
原文标题:视觉新范式Transformer之IPT
文章出处:【微信号:gh_a204797f977b,微信公众号:深度学习实战】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
视觉深度学习模型:规模越大效果越佳吗?
【书籍评测活动NO.30】大规模语言模型:从理论到实践
谷歌模型训练软件有哪些功能和作用
如何使用Python进行图像识别的自动学习自动训练?
【飞腾派4G版免费试用】第三章:抓取图像,手动标注并完成自定义目标检测模型训练和测试
如何让网络模型加速训练
训练大语言模型带来的硬件挑战

卷积神经网络模型训练步骤
基于预训练模型和语言增强的零样本视觉学习

State of GPT:大神Andrej揭秘OpenAI大模型原理和训练过程

利用NeRF训练深度立体网络的创新流程

什么是预训练AI模型?
利用OpenVINO™部署HuggingFace预训练模型的方法与技巧





 工商网监
工商网监
评论